
Линейна функция на най-малките квадрати. Апроксимация на функция чрез метода на най-малките квадрати. Кратка теория на най-малките квадрати за линейни връзки
Метод най-малки квадрати(MNC, английски обикновени най-малки квадрати, OLS)- математически метод, използван за решаване различни задачи, базиран на минимизиране на сумата от квадратните отклонения на някои функции от желаните променливи. Може да се използва за „решаване“ на свръхопределени системи от уравнения (когато броят на уравненията надвишава броя на неизвестните), за намиране на решения в случай на обикновени (не свръхопределени) нелинейни системи от уравнения, за приближаване на точкови стойности на някои функция. OLS е един от основните методи за регресионен анализ за оценка на неизвестни параметри на регресионни модели от извадкови данни.
Енциклопедичен YouTube
1 / 5
✪ Метод на най-малките квадрати. Предмет
✪ Метод на най-малките квадрати, урок 1/2. Линейна функция
✪ Иконометрия. Лекция 5. Метод на най-малките квадрати
✪ Митин И.В. - Обработка на физически резултати. експеримент - Метод на най-малките квадрати (лекция 4)
✪ Иконометрия: Същността на метода на най-малките квадрати №2
субтитри
История
до началото на XIX V. учените не са имали определени правилада решава система от уравнения, в която броят на неизвестните е по-малък от броя на уравненията; Дотогава се използваха частни техники, които зависеха от вида на уравненията и от остроумието на калкулаторите и следователно различните калкулатори, базирани на едни и същи данни от наблюдения, стигаха до различни заключения. Гаус (1795) е отговорен за първото приложение на метода, а Лежандре (1805) независимо го открива и публикува под съвременно име(фр. Méthode des moindres quarrés) . Лаплас свързва метода с теорията на вероятностите, а американският математик Адрейн (1808) разглежда неговите теоретични приложения на вероятностите. Методът е широко разпространен и подобрен чрез по-нататъшни изследвания от Encke, Bessel, Hansen и други.
Същността на метода на най-малките квадрати
Нека x (\displaystyle x)- комплект n (\displaystyle n)неизвестни променливи (параметри), f i (x) (\displaystyle f_(i)(x)), , m > n (\displaystyle m>n)- набор от функции от този набор от променливи. Задачата е да изберете такива стойности x (\displaystyle x), така че стойностите на тези функции да са възможно най-близо до определени стойности y i (\displaystyle y_(i)). По същество ние говорим заза „решението“ на свръхопределена система от уравнения f i (x) = y i (\displaystyle f_(i)(x)=y_(i)), i = 1 , … , m (\displaystyle i=1,\ldots ,m)в посочения смисъл на максимална близост на лявата и дясната част на системата. Същността на метода на най-малките квадрати е да се избере като „мярка за близост“ сумата от квадратните отклонения на лявата и дясната страна | f i (x) − y i |
(\displaystyle |f_(i)(x)-y_(i)|).. По този начин същността на MNC може да се изрази по следния начин: ∑ i e i 2 = ∑ i (y i − f i (x)) 2 → min x (\displaystyle \sum _(i)e_(i)^(2)=\sum _(i)(y_(i)-f_( i)(x))^(2)\rightarrow \min _(x))Ако системата от уравнения има решение, тогава минимумът на сумата от квадрати ще бъде равен на нула и точните решения на системата от уравнения могат да бъдат намерени аналитично или, например, с помощта на различни числени методи за оптимизация. Ако системата е свръхопределена, това е, свободно казано, броят на независимите уравнения x (\displaystyle x)повече количество желани променливи, тогава системата няма точно решение и методът на най-малките квадрати ни позволява да намерим някакъв „оптимален“ векторв смисъл на максимална близост на векторите y (\displaystyle y)и f (x) (\displaystyle f(x))или максимална близост на вектора на отклонение
e (\displaystyle e)
до нула (близостта се разбира в смисъл на евклидово разстояние).
Пример - система от линейни уравнения,По-специално, методът на най-малките квадрати може да се използва за "решаване" на система от линейни уравнения A x = b (\displaystyle Ax=b)Къде A (\displaystyle A)матрица с правоъгълен размер
m × n, m > n (\displaystyle m\times n,m>n) (т.е. броят на редовете на матрица A е по-голям от броя на търсените променливи).Такава система от уравнения в x (\displaystyle x)общ случай няма решение. Следователно тази система може да бъде „решена“ само в смисъл на избор на такъв векторв смисъл на максимална близост на векторите за минимизиране на "разстоянието" между векторите A x (\displaystyle Ax) b (\displaystyle b). За да направите това, можете да приложите критерия за минимизиране на сумата от квадратите на разликите между лявата и дясната страна на уравненията на системата, т.е. (A x − b) T (A x − b) → min x (\displaystyle (Ax-b)^(T)(Ax-b)\rightarrow \min _(x)). Лесно е да се покаже, че решаването на този проблем за минимизиране води до решението
следваща система.уравнения
A T A x = A T b ⇒ x = (A T A) − 1 A T b (\displaystyle A^(T)Ax=A^(T)b\Rightarrow x=(A^(T)A)^(-1)A^ (T)b) n (\displaystyle n) OLS в регресионен анализ (апроксимация на данни) желани променливи, тогава системата няма точно решение и методът на най-малките квадрати ни позволява да намерим някакъв „оптимален“ векторНека има x (\displaystyle x). Предизвикателството е да се гарантира, че връзката между желани променливи, тогава системата няма точно решение и методът на най-малките квадрати ни позволява да намерим някакъв „оптимален“ векторв смисъл на максимална близост на векторите x (\displaystyle x)приближено чрез някаква известна функция до някои неизвестни параметри за минимизиране на "разстоянието" между векторите, тоест всъщност намира най-добрите стойности на параметрите за минимизиране на "разстоянието" между векторите, максимално приближаващи стойностите f (x, b) (\displaystyle f(x, b))към действителните стойности желани променливи, тогава системата няма точно решение и методът на най-малките квадрати ни позволява да намерим някакъв „оптимален“ вектор. Всъщност това се свежда до случая на „решаване“ на свръхопределена система от уравнения по отношение на за минимизиране на "разстоянието" между векторите:
F (x t , b) = y t , t = 1 , … , n (\displaystyle f(x_(t),b)=y_(t),t=1,\ldots ,n).
В регресионния анализ и по-специално в иконометрията се използват вероятностни модели на зависимост между променливите
Y t = f (x t, b) + ε t (\displaystyle y_(t)=f(x_(t),b)+\varepsilon _(t)),
По-специално, методът на най-малките квадрати може да се използва за "решаване" на система от линейни уравнения ε t (\displaystyle \varepsilon _(t))- т.нар случайни грешкимодели.
Съответно отклонения на наблюдаваните стойности желани променливи, тогава системата няма точно решение и методът на най-малките квадрати ни позволява да намерим някакъв „оптимален“ векторот модела f (x, b) (\displaystyle f(x, b))вече се приема в самия модел. Същността на метода на най-малките квадрати (обикновен, класически) е да се намерят такива параметри за минимизиране на "разстоянието" между векторите, при което сумата от квадратните отклонения (грешки, за регресионните модели те често се наричат регресионни остатъци) e t (\displaystyle e_(t))ще бъде минимален:
b ^ O L S = arg min b R S S (b) (\displaystyle (\hat (b))_(OLS)=\arg \min _(b)RSS(b)),По-специално, методът на най-малките квадрати може да се използва за "решаване" на система от линейни уравнения R S S (\displaystyle RSS)- английски Остатъчната сума на квадратите се определя като:
R S S (b) = e T e = ∑ t = 1 n e t 2 = ∑ t = 1 n (y t − f (x t , b)) 2 (\displaystyle RSS(b)=e^(T)e=\sum _ (t=1)^(n)e_(t)^(2)=\сума _(t=1)^(n)(y_(t)-f(x_(t),b))^(2) ).В общия случай този проблем може да бъде решен чрез методи на числена оптимизация (минимизация). В този случай те говорят за нелинейни най-малки квадрати(NLS или NLLS - английски нелинейни най-малки квадрати). В много случаи е възможно да се получи аналитично решение. За да се реши задачата за минимизиране, е необходимо да се намерят стационарни точки на функцията R S S (b) (\displaystyle RSS(b)), диференцирайки го по неизвестни параметри за минимизиране на "разстоянието" между векторите, приравняване на производните на нула и решаване на получената система от уравнения:
∑ t = 1 n (y t − f (x t , b)) ∂ f (x t , b) ∂ b = 0 (\displaystyle \sum _(t=1)^(n)(y_(t)-f(x_ (t),b))(\frac (\partial f(x_(t),b))(\partial b))=0).OLS в случай на линейна регресия
Нека регресионната зависимост е линейна:
y t = ∑ j = 1 k b j x t j + ε = x t T b + ε t (\displaystyle y_(t)=\sum _(j=1)^(k)b_(j)x_(tj)+\varepsilon =x_( t)^(T)b+\varepsilon _(t)).Нека ге колонният вектор на наблюденията на променливата, която се обяснява, и X (\displaystyle X)- Това (n × k) (\displaystyle ((n\пъти k)))-матрица на факторните наблюдения (редовете на матрицата са вектори на стойностите на факторите в дадено наблюдение, колоните са вектор на стойностите на даден фактор във всички наблюдения). Матричното представяне на линейния модел има формата:
y = X b + ε (\displaystyle y=Xb+\varepsilon ).Тогава векторът на оценките на обяснената променлива и векторът на регресионните остатъци ще бъдат равни
y ^ = X b , e = y − y ^ = y − X b (\displaystyle (\hat (y))=Xb,\quad e=y-(\hat (y))=y-Xb).Съответно сумата от квадратите на регресионните остатъци ще бъде равна на
R S S = e T e = (y − X b) T (y − X b) (\displaystyle RSS=e^(T)e=(y-Xb)^(T)(y-Xb)).Диференциране на тази функция по отношение на вектора на параметрите за минимизиране на "разстоянието" между векторитеи приравнявайки производните на нула, получаваме система от уравнения (в матрична форма):
(X T X) b = X T y (\displaystyle (X^(T)X)b=X^(T)y).В дешифрирана матрична форма тази система от уравнения изглежда така:
(∑ x t 1 2 ∑ x t 1 x t 2 ∑ x t 1 x t 3 … ∑ x t 1 x t k ∑ x t 2 x t 1 ∑ x t 2 2 ∑ x t 2 x t 3 … ∑ x t 2 x t k ∑ x t 3 x t 1 ∑ x t 3 x t 2 ∑ x t 3 2 … ∑ x t 3 x t k ⋮ ⋮ ⋮ ⋱ ⋮ ∑ x t k x t 2 ∑ x t k x t 3 … ∑ x t k 2) (b 1 b 2 b 3 ⋮ b k) = (∑ x t 1 y t ∑ x t 2 y t ∑ x t 3 y t ⋮ ∑ x t k y t) , (\displaystyle (\begin(pmatrix)\sum x_(t1)^(2)&\sum x_(t1)x_(t2)&\sum x_(t1)x_(t3)&\ldots &\sum x_(t1)x_(tk)\\\sum x_(t2)x_(t1)&\sum x_(t2)^(2)&\sum x_(t2)x_(t3)&\ldots &\ сума x_(t2)x_(tk)\\\сума x_(t3)x_(t1)&\сума x_(t3)x_(t2)&\сума x_(t3)^(2)&\ldots &\сума x_ (t3)x_(tk)\\\vdots &\vdots &\vdots &\ddots &\vdots \\\sum x_(tk)x_(t1)&\sum x_(tk)x_(t2)&\sum x_ (tk)x_(t3)&\ldots &\sum x_(tk)^(2)\\\end(pmatrix))(\begin(pmatrix)b_(1)\\b_(2)\\b_(3 )\\\vdots \\b_(k)\\\end(pmatrix))=(\begin(pmatrix)\sum x_(t1)y_(t)\\\sum x_(t2)y_(t)\\ \sum x_(t3)y_(t)\\\vdots \\\sum x_(tk)y_(t)\\\end(pmatrix)),)където всички суми се вземат върху всички валидни стойности t (\displaystyle t).
Ако в модела е включена константа (както обикновено), тогава x t 1 = 1 (\displaystyle x_(t1)=1)пред всички t (\displaystyle t), следователно в горния ляв ъгъл на матрицата на системата от уравнения има броя на наблюденията n (\displaystyle n), а в останалите елементи на първия ред и първата колона - просто сумите на стойностите на променливите: ∑ x t j (\displaystyle \sum x_(tj))и първият елемент от дясната страна на системата е ∑ y t (\displaystyle \sum y_(t)).
Решението на тази система от уравнения дава обща формула OLS оценки за линейния модел:
b ^ O L S = (X T X) − 1 X T y = (1 n X T X) − 1 1 n X T y = V x − 1 C x y (\displaystyle (\hat (b))_(OLS)=(X^(T )X)^(-1)X^(T)y=\left((\frac (1)(n))X^(T)X\right)^(-1)(\frac (1)(n ))X^(T)y=V_(x)^(-1)C_(xy)).За аналитични цели последното представяне на тази формула се оказва полезно (в системата от уравнения при деление на n вместо суми се появяват средни аритметични). Ако в регресионен модел данните центриран, тогава в това представяне първата матрица има значението на примерна ковариационна матрица от фактори, а втората е вектор от ковариации на фактори със зависимата променлива. Ако в допълнение данните също са нормализиранкъм MSE (тоест в крайна сметка стандартизиран), тогава първата матрица има значението на примерна корелационна матрица на фактори, вторият вектор - вектор на примерни корелации на фактори със зависимата променлива.
Важно свойство на оценките на OLS за модели с постоянна- линията на конструираната регресия минава през центъра на тежестта на извадковите данни, т.е. равенството е изпълнено:
y ¯ = b 1 ^ + ∑ j = 2 k b ^ j x ¯ j (\displaystyle (\bar (y))=(\hat (b_(1)))+\sum _(j=2)^(k) (\hat (b))_(j)(\bar (x))_(j)).По-специално, в в краен случай, когато единственият регресор е константа, получаваме, че OLS оценката на единствения параметър (самата константа) е равна на средната стойност на обяснената променлива. Тоест, средната аритметична стойност, известна с добрите си свойства от законите на големите числа, също е оценка на най-малките квадрати - тя удовлетворява критерия за минималната сума на квадратите на отклоненията от нея.
Най-простите специални случаи
В случай на парна баня линейна регресия y t = a + b x t + ε t (\displaystyle y_(t)=a+bx_(t)+\varepsilon _(t)), когато се оценява линейната зависимост на една променлива от друга, формулите за изчисление се опростяват (можете да правите без матрична алгебра). Системата от уравнения има формата:
(1 x ¯ x ¯ x 2 ¯) (a b) = (y ¯ x y ¯) (\displaystyle (\begin(pmatrix)1&(\bar (x))\\(\bar (x))&(\bar (x^(2)))\\\end(pmatrix))(\begin(pmatrix)a\\b\\\end(pmatrix))=(\begin(pmatrix)(\bar (y))\\ (\overline (xy))\\\end(pmatrix))).От тук е лесно да намерите оценки на коефициента:
( b ^ = Cov (x , y) Var (x) = x y ¯ − x ¯ y ¯ x 2 ¯ − x ¯ 2 , a ^ = y ¯ − b x ¯ . (\displaystyle (\begin(cases) (\hat (b))=(\frac (\mathop (\textrm (Cov)) (x,y))(\mathop (\textrm (Var)) (x)))=(\frac ((\overline (xy))-(\bar (x))(\bar (y)))((\overline (x^(2)))-(\overline (x))^(2))),\\( \hat (a))=(\bar (y))-b(\bar (x)).\end(cases)))Въпреки факта, че в общия случай моделите с константа са за предпочитане, в някои случаи от теоретични съображения е известно, че константа a (\displaystyle a)трябва да е равно на нула. Например във физиката връзката между напрежение и ток е U = I ⋅ R (\displaystyle U=I\cdot R); При измерване на напрежение и ток е необходимо да се оцени съпротивлението. В случая говорим за модела y = b x (\displaystyle y=bx). В този случай вместо система от уравнения имаме едно уравнение
(∑ x t 2) b = ∑ x t y t (\displaystyle \left(\sum x_(t)^(2)\right)b=\sum x_(t)y_(t)).
Следователно формулата за оценка на единичния коефициент има формата
B ^ = ∑ t = 1 n x t y t ∑ t = 1 n x t 2 = x y ¯ x 2 ¯ (\displaystyle (\hat (b))=(\frac (\sum _(t=1)^(n)x_(t )y_(t))(\sum _(t=1)^(n)x_(t)^(2)))=(\frac (\overline (xy))(\overline (x^(2)) ))).
Случаят на полиномен модел
Ако данните са подходящи от полиномна регресионна функция на една променлива f (x) = b 0 + ∑ i = 1 k b i x i (\displaystyle f(x)=b_(0)+\sum \limits _(i=1)^(k)b_(i)x^(i)), след това, възприемане на степени x i (\displaystyle x^(i))като независими фактори за всеки i (\displaystyle i)възможно е да се оценят параметрите на модела въз основа на общата формула за оценка на параметрите на линеен модел. За да направите това, достатъчно е да вземете предвид в общата формула, че с такова тълкуване x t i x t j = x t i x t j = x t i + j (\displaystyle x_(ti)x_(tj)=x_(t)^(i)x_(t)^(j)=x_(t)^(i+j))в смисъл на максимална близост на векторите x t j y t = x t j y t (\displaystyle x_(tj)y_(t)=x_(t)^(j)y_(t)). следователно матрични уравненияв този случай ще приеме формата:
(n ∑ n x t … ∑ n x t k ∑ n x t ∑ n x t 2 … ∑ n x t k + 1 ⋮ ⋮ ⋱ ⋮ ∑ n x t k ∑ n x t k + 1 … ∑ n x t 2 k) [ b 0 b 1 ⋮ b k ] = [ ∑ n y t ∑ n t y t ⋮ ∑ n x t k y t ] .
(\displaystyle (\begin(pmatrix)n&\sum \limits _(n)x_(t)&\ldots &\sum \limits _(n)x_(t)^(k)\\\sum \limits _( n)x_(t)&\sum \limits _(n)x_(t)^(2)&\ldots &\sum \limits _(n)x_(t)^(k+1)\\\vdots & \vdots &\ddots &\vdots \\\sum \limits _(n)x_(t)^(k)&\sum \limits _(n)x_(t)^(k+1)&\ldots &\ сума \лимити _(n)x_(t)^(2k)\end(pmatrix))(\begin(bmatrix)b_(0)\\b_(1)\\\vdots \\b_(k)\end( bmatrix))=(\begin(bmatrix)\sum \limits _(n)y_(t)\\\sum \limits _(n)x_(t)y_(t)\\\vdots \\\sum \limits _(n)x_(t)^(k)y_(t)\end(bmatrix)).)
Статистически свойства на OLS оценителите На първо място, отбелязваме, че за линейните модели оценките на OLS са линейни оценки, както следва от горната формула. За безпристрастни оценки на OLS е необходимо и достатъчно да се извършинай-важното условие регресионен анализ: в зависимост от факторите, математическото очакване на случайна грешка трябва да бъде равно на нула.Това състояние
- , по-специално, е удовлетворен, ако
- математическото очакване на случайни грешки е нула и
факторите и случайните грешки са независими случайни променливи. Второто условие - условието за екзогенност на факторите - е основно. Ако това свойство не е изпълнено, тогава можем да предположим, че почти всички оценки ще бъдат изключително незадоволителни: те дори няма да бъдат последователни (тоест дори много голямо количество данни не ни позволява да получим висококачествени оценки в този случай ). В класическия случай се прави по-силно предположение за детерминизма на факторите, за разлика от случайна грешка, което автоматично означава, че условието за екзогенност е изпълнено. В общия случай за съгласуваност на оценките е достатъчно да се удовлетвори условието за екзогенност заедно с конвергенцията на матрицата V x (\displaystyle V_(x))
към някаква неособена матрица, тъй като размерът на извадката нараства до безкрайност.
За да бъдат, в допълнение към последователността и безпристрастността, оценките на (обикновените) най-малки квадрати също ефективни (най-добрите в класа на линейните безпристрастни оценки), трябва да бъдат изпълнени допълнителни свойства на случайната грешка: Тези предположения могат да бъдат формулирани за ковариационната матрица на вектора на случайната грешка.
V (ε) = σ 2 I (\displaystyle V(\varepsilon)=\sigma ^(2)I) Линеен модел, който отговаря на тези условия, се нарича. OLS оценките за класическа линейна регресия са безпристрастни, последователни и най-ефективните оценки в класа на всички линейни безпристрастни оценки (в английската литература понякога се използва съкращението СИН (Най-добрият линеен безпристрастен оценител) - най-добрата линейна безпристрастна оценка; В руската литература по-често се цитира теоремата на Гаус-Марков). Както е лесно да се покаже, ковариационната матрица на вектора на оценките на коефициента ще бъде равна на:
V (b ^ O L S) = σ 2 (X T X) − 1 (\displaystyle V((\hat (b))_(OLS))=\sigma ^(2)(X^(T)X)^(-1 )).
Ефективността означава, че тази ковариационна матрица е „минимална“ (всяка линейна комбинация от коефициенти, и по-специално самите коефициенти, имат минимална дисперсия), тоест в класа на линейните безпристрастни оценители, OLS оценителите са най-добри. Диагоналните елементи на тази матрица - дисперсиите на оценките на коефициентите - са важни параметри за качеството на получените оценки. Не е възможно обаче да се изчисли ковариационната матрица, тъй като дисперсията на случайната грешка е неизвестна. Може да се докаже, че безпристрастна и последователна (за класически линеен модел) оценка на дисперсията на случайните грешки е количеството:
S 2 = R S S / (n − k) (\displaystyle s^(2)=RSS/(n-k)).
Замествайки тази стойност във формулата за ковариационната матрица, получаваме оценка на ковариационната матрица. Получените оценки също са безпристрастни и последователни. Също така е важно оценката на дисперсията на грешката (и следователно дисперсията на коефициентите) и оценките на параметрите на модела да са независими случайни променливи, което ви позволява да получите тестова статистика за тестване на хипотези относно коефициентите на модела.
Трябва да се отбележи, че ако класическите допускания не са изпълнени, оценките на параметрите на OLS не са най-ефективните и, когато W (\displaystyle W)е някаква симетрична матрица с положително определено тегло. Обикновените най-малки квадрати са специален случай този подход, когато матрицата на теглото е пропорционална на матрицата на идентичността. Както е известно, за симетричните матрици (или оператори) има разширение W = P T P (\displaystyle W=P^(T)P). Следователно посоченият функционал може да бъде представен по следния начин e T P T P e = (P e) T P e = e ∗ T e ∗ (\displaystyle e^(T)P^(T)Pe=(Pe)^(T)Pe=e_(*)^(T)e_( *)), тоест този функционал може да бъде представен като сбор от квадратите на някои трансформирани „остатъци“. По този начин можем да разграничим клас от методи на най-малките квадрати - LS методи (Least Squares).
Доказано е (теорема на Ейткен), че за обобщен линеен регресионен модел (в който не се налагат ограничения върху ковариационната матрица на случайните грешки), най-ефективни (в класа на линейните непредубедени оценки) са т.нар. оценки. обобщени най-малки квадрати (GLS - Обобщени най-малки квадрати)- LS метод с тегловна матрица, равна на обратната ковариационна матрица на случайни грешки: W = V ε − 1 (\displaystyle W=V_(\varepsilon )^(-1)).
Може да се покаже, че формулата за GLS оценки на параметрите на линеен модел има вида
B ^ G L S = (X T V − 1 X) − 1 X T V − 1 y (\displaystyle (\hat (b))_(GLS)=(X^(T)V^(-1)X)^(-1) X^(T)V^(-1)y).
Ковариационната матрица на тези оценки съответно ще бъде равна на
V (b ^ G L S) = (X T V − 1 X) − 1 (\displaystyle V((\hat (b))_(GLS))=(X^(T)V^(-1)X)^(- 1)).
Всъщност същността на OLS се състои в определена (линейна) трансформация (P) на оригиналните данни и прилагането на обикновен OLS към трансформираните данни. Целта на тази трансформация е, че за трансформираните данни случайните грешки вече отговарят на класическите допускания.
Претеглен OLS
В случай на диагонална матрица на тегло (и следователно ковариационна матрица на случайни грешки), имаме така наречените претеглени най-малки квадрати (WLS). В този случай претеглената сума от квадрати на остатъците на модела е сведена до минимум, т.е. всяко наблюдение получава „тегло“, което е обратно пропорционално на дисперсията на случайната грешка в това наблюдение: e T W e = ∑ t = 1 n e t 2 σ t 2 (\displaystyle e^(T)We=\sum _(t=1)^(n)(\frac (e_(t)^(2))(\ сигма_(t)^(2)))). Всъщност данните се трансформират чрез претегляне на наблюденията (разделяне на количество, пропорционално на изчисленото стандартно отклонение на случайните грешки), а към претеглените данни се прилага обикновен OLS.
ISBN 978-5-7749-0473-0.
КУРСОВА РАБОТА
дисциплина: Информатика
Тема: Апроксимация на функция по метода на най-малките квадрати
Въведение
1. Постановка на проблема
2. Формули за изчисление
Изчисляване с помощта на таблици, направени по средства Microsoft Excel
Диаграма на алгоритъма
Изчисление в MathCad
Резултати, получени с помощта на линейната функция
Представяне на резултатите под формата на графики
Въведение
Цел курсова работае да задълбочи познанията по компютърни науки, да развие и затвърди умения за работа с процесора за електронни таблици Microsoft Excel и софтуерния продукт MathCAD и да ги използва за решаване на задачи с компютър от предметна област, свързана с научни изследвания.
Апроксимацията (от латинското "approximare" - "да се приближавам") е приблизително изразяване на всякакви математически обекти (например числа или функции) чрез други, които са по-прости, по-удобни за използване или просто по-известни. В научните изследвания апроксимацията се използва за описване, анализиране, обобщаване и по-нататъшно използване на емпирични резултати.
Както е известно, може да има точна (функционална) връзка между количествата, когато една конкретна стойност съответства на една стойност на аргумента, и по-малко точна (корелационна) връзка, когато една конкретна стойност на аргумента съответства на приблизителна стойност или определен набор от функционални стойности, в една или друга степен близки една до друга. Когато провеждате научни изследвания, обработвате резултатите от наблюдение или експеримент, обикновено трябва да се справите с втория вариант.
При изучаване на количествените зависимости на различни показатели, чиито стойности се определят емпирично, като правило има известна променливост. Отчасти се определя от разнородността на изследваните обекти на неживата и особено от живата природа и отчасти се определя от грешката на наблюдението и количествената обработка на материалите. Последният компонент не винаги може да бъде напълно елиминиран, той може да бъде сведен до минимум чрез внимателен избор на адекватен метод на изследване и внимателна работа. Следователно, когато се извършва всякаква изследователска работа, възниква проблемът с идентифицирането на истинската природа на зависимостта на изследваните показатели, в една или друга степен, маскирани от липсата на отчитане на променливостта: стойности. За тази цел се използва апроксимация - приблизително описание на корелационната зависимост на променливите чрез подходящо уравнение на функционалната зависимост, което предава основната тенденция на зависимостта (или нейната "тенденция").
При избора на приближение трябва да се изхожда от конкретния проблем на изследването. Обикновено колкото по-просто е уравнението, използвано за приближение, толкова по-приблизително е полученото описание на връзката. Ето защо е важно да се прочете колко значими и какво причинява отклоненията на конкретни стойности от резултантната тенденция. Когато се описва зависимостта на емпирично определени стойности, може да се постигне много по-голяма точност чрез използване на някои по-сложни, многопараметрични уравнения. Въпреки това, няма смисъл да се стремим да предаваме случайни отклонения на стойностите в конкретни серии от емпирични данни с максимална точност. Много по-важно е да се схване общата закономерност, която в случая най-логично и с приемлива точност се изразява именно чрез двупараметричното уравнение на степенна функция. По този начин, когато избира метод на приближение, изследователят винаги прави компромис: той решава до каква степен в този случай е препоръчително и целесъобразно да се „пожертват“ детайлите и съответно как най-общо трябва да се изрази зависимостта на сравняваните променливи. Наред с идентифицирането на модели, маскирани от случайни отклонения на емпиричните данни от общия модел, апроксимацията също така позволява да се решат много други важни проблеми: формализиране на намерената зависимост; намерете неизвестни стойности на зависимата променлива чрез интерполация или, ако е подходящо, екстраполация.
Във всяка задача са формулирани условията на задачата, изходните данни, формата за издаване на резултати и са посочени основните математически зависимости за решаване на задачата. В съответствие с метода за решаване на задачата е разработен алгоритъм за решение, който е представен в графичен вид.
1. Постановка на проблема
1. Използвайки метода на най-малките квадрати, приближете функцията, дадена в таблицата:
а) полином от първа степен ![]() ;
;
б) полином от втора степен;
в) експоненциална зависимост.
За всяка зависимост изчислете коефициента на детерминизъм.
Изчислете коефициента на корелация (само в случай а).
За всяка зависимост изградете линия на тенденция.
С помощта на функцията LINEST изчислете числените характеристики на зависимостта от.
Сравнете вашите изчисления с резултатите, получени с помощта на функцията LINEST.
Направете заключение коя от получените формули по възможно най-добрия начинприближава функцията.
Напишете програма на един от езиците за програмиране и сравнете резултатите от изчисленията с получените по-горе.
Вариант 3. Функцията е дадена в таблицата. 1.
Таблица 1.
2. Формули за изчисление Често, когато се анализират емпирични данни, има нужда да се намери функционална връзка между величините x и y, които се получават в резултат на опит или измервания. Xi (независима стойност) се задава от експериментатора, а yi, наречени емпирични или експериментални стойности, се получава в резултат на експеримента. Аналитичната форма на съществуващата функционална връзка между величините x и y обикновено е неизвестна, така че възниква практически важна задача - да се намери емпирична формула (където са параметрите), чиито стойности биха се различавали малко от експерименталните стойности. Според метода на най-малките квадрати най-добрите коефициенти са тези, за които сумата от квадратните отклонения на намерената емпирична функция от дадените стойности на функцията ще бъде минимална. Използвайки необходимото условие за екстремума на функция на няколко променливи - равенството на частните производни на нула, намираме набор от коефициенти, които осигуряват минимума на функцията, определена с формула (2), и получаваме нормална система за определяне на коефициентите Така намирането на коефициентите се свежда до решаване на система (3). Видът на системата (3) зависи от това от кой клас емпирични формули търсим зависимост (1). В случай линейна зависимостсистема (3) ще приеме формата: В случай на квадратична зависимост системата (3) ще приеме формата: В някои случаи като емпирична формула се приема функция, в която неопределените коефициенти влизат нелинейно. В този случай понякога проблемът може да бъде линеаризиран, т.е. намали до линейно. Такива зависимости включват експоненциалната зависимост където a1 и a2 са недефинирани коефициенти. Линеаризацията се постига чрез вземане на логаритъм на равенство (6), след което се получава отношението Нека означим и съответно с и , тогава зависимостта (6) може да бъде записана във вида , което ни позволява да приложим формули (4) със замяна на a1 с и с . Графиката на реконструираната функционална зависимост y(x) въз основа на резултатите от измерването (xi, yi), i=1,2,…,n се нарича регресионна крива. За да се провери съответствието на построената регресионна крива с експерименталните резултати, обикновено се въвеждат следните числени характеристики: коефициент на корелация (линейна зависимост), съотношение на корелация и коефициент на детерминация. Коефициентът на корелация е мярка за линейната връзка между зависимите случайни променливи: той показва колко добре средно една от променливите може да бъде представена като линейна функция на другата. Коефициентът на корелация се изчислява по формулата: къде е средното аритметична стойностсъответно в x, y. Коефициентът на корелация между случайните променливи по абсолютна стойност не надвишава 1. Колкото по-близо е до 1, толкова по-тясна е линейната връзка между x и y. В случай на нелинейни корелационна връзкаусловните средни стойности са разположени около кривата линия. В този случай се препоръчва да се използва корелационно съотношение като характеристика на силата на връзката, чието тълкуване не зависи от вида на изследваната зависимост. Коефициентът на корелация се изчислява по формулата: Къде Винаги. Равенство = съответства на произволни некорелирани стойности; = ако и само ако има точна функционална връзка между x и y. При линейна зависимост на y от x съотношението на корелация съвпада с квадрата на коефициента на корелация. Стойността се използва като индикатор за отклонението на регресията от линейната. Коефициентът на корелация е мярка за корелацията между y и x във всякаква форма, но не може да даде представа за степента на приближаване на емпиричните данни до специална форма. За да разберете колко точно построената крива отразява емпиричните данни, се въвежда друга характеристика - коефициентът на детерминация. Коефициентът на детерминизъм се определя по формулата: където Sres = - остатъчна сума от квадрати, характеризираща отклонението на експерименталните данни от теоретичните total - обща сума от квадрати, където средната стойност е yi. Колкото по-малък е остатъчният сбор от квадрати в сравнение с обща сумаквадрати, толкова по-голяма е стойността на коефициента на детерминация r2, който показва колко добре уравнението, получено с помощта на регресионен анализ, обяснява връзките между променливите. Ако е равно на 1, тогава има пълна корелация с модела, т.е. няма разлика между действителните и прогнозните стойности на y. IN обратен случай, ако коефициентът на детерминация е 0, тогава регресионното уравнение е неуспешно при прогнозиране на стойностите на y. Коефициентът на детерминизъм винаги не надвишава съотношението на корелация. В случай, че равенството е изпълнено, можем да приемем, че построената емпирична формула най-точно отразява емпиричните данни. 3. Изчисляване с помощта на таблици, направени с Microsoft Excel За извършване на изчисления е препоръчително да подредите данните във формата на таблица 2, като използвате процесора за електронни таблици Microsoft Excel. Таблица 2
Нека обясним как се съставя Таблица 2. Стъпка 1. В клетки A1: A25 въвеждаме стойностите xi. Стъпка 2. В клетки B1:B25 въвеждаме стойностите на yi. Стъпка 3. В клетка C1 въведете формулата = A1^2. Стъпка 4. Тази формула се копира в клетки C1:C25. Стъпка 5. В клетка D1 въведете формулата = A1 * B1. Стъпка 6. Тази формула се копира в клетки D1:D25. Стъпка 7. В клетка F1 въведете формулата = A1^4. Стъпка 8. Тази формула се копира в клетки F1:F25. Стъпка 9. В клетка G1 въведете формулата = A1^2*B1. Стъпка 10. Тази формула се копира в клетки G1:G25. Стъпка 11. В клетка H1 въведете формулата = LN(B1). Стъпка 12. Тази формула се копира в клетки H1:H25. Стъпка 13. В клетка I1 въведете формулата = A1*LN(B1). Стъпка 14. Тази формула се копира в клетки I1:I25. Извършваме следващите стъпки, като използваме автоматично сумиране S. Стъпка 15. В клетка A26 въведете формулата = SUM(A1:A25). Стъпка 16. В клетка B26 въведете формулата = SUM(B1:B25). Стъпка 17. В клетка C26 въведете формулата = SUM(C1:C25). Стъпка 18. В клетка D26 въведете формулата = SUM(D1:D25). Стъпка 19. В клетка E26 въведете формулата = SUM(E1:E25). Стъпка 20. В клетка F26 въведете формулата = SUM(F1:F25). Стъпка 21. В клетка G26 въведете формулата = SUM(G1:G25). Стъпка 22. В клетка H26 въведете формулата = SUM(H1:H25). Стъпка 23. В клетка I26 въведете формулата = SUM(I1:I25). Нека апроксимираме функцията с линейна функция. За определяне на коефициентите ще използваме система (4). Използвайки сумите от таблица 2, разположени в клетки A26, B26, C26 и D26, записваме система (4) във формата решавайки което, получаваме Системата е решена с помощта на метода на Крамер. Същността на която е следната. Да разгледаме система от n алгебрични линейни уравнения с n неизвестни: Детерминантата на системата е детерминантата на системната матрица: Нека означим с - детерминантата, която се получава от детерминантата на системата Δ чрез заместване на j-тата колона с колоната Така линейното приближение има формата Решаваме система (11) с помощта на Microsoft Excel. Резултатите са представени в таблица 3. Таблица 3
Обратна матрица В таблица 3 в клетки A32:B33 е записана формулата (=MOBR(A28:B29)). В клетки E32:E33 е записана формулата (=MULTIPLE(A32:B33),(C28:C29)). След това приближаваме функцията квадратична функция решавайки което, получаваме a1=10.663624, По този начин квадратичното приближение има формата Решаваме система (16) с помощта на Microsoft Excel. Резултатите са представени в таблица 4. Таблица 4
Обратна матрица В таблица 4 в клетки A41:C43 е записана формулата (=MOBR(A36:C38)). В клетки F41:F43 е записана формулата (=MULTIPLE(A41:C43),(D36:D38)). Сега нека апроксимираме функцията с експоненциална функция. За да определим коефициентите и, вземаме логаритъма на стойностите и използвайки сумите от таблица 2, разположени в клетки A26, C26, H26 и I26, получаваме системата След като решихме система (18), получаваме и . След потенциране получаваме. По този начин експоненциалното приближение има формата Решаваме система (18) с помощта на Microsoft Excel. Резултатите са представени в таблица 5. Таблица 5
Обратна матрица В клетки A50:B51 е записана формулата (=MOBR(A46:B47)). В клетки E49:E50 е записана формулата (=MULTIPLE(A50:B51),(C46:C47)). В клетка E51 е записана формулата =EXP(E49). Нека изчислим средноаритметичното по формулите: Резултатите от изчисленията с помощта на Microsoft Excel са представени в таблица 6. Таблица 6
В клетка B54 е записана формулата = A26/25. В клетка B55 е записана формулата = B26/25 Таблица 7
Стъпка 1. В клетка J1 въведете формулата = (A1-$B$54)*(B1-$B$55). Стъпка 2. Тази формула се копира в клетки J2:J25. Стъпка 3. В клетка K1 въведете формулата = (A1-$B$54)^2. Стъпка 4. Тази формула се копира в клетки k2:K25. Стъпка 5. В клетка L1 въведете формулата = (B1-$B$55)^2. Стъпка 6. Тази формула се копира в клетки L2:L25. Стъпка 7. В клетка M1 въведете формулата = ($E$32+$E$33*A1-B1)^2. Стъпка 8. Тази формула се копира в клетки M2:M25. Стъпка 9. В клетка N1 въведете формулата = ($F$41+$F$42*A1+$F$43*A1^2-B1)^2. Стъпка 10. Тази формула се копира в клетки N2:N25. Стъпка 11. В клетка O1 въведете формулата = ($E$51*EXP($E$50*A1)-B1)^2. Стъпка 12. Тази формула се копира в клетки O2:O25. Извършваме следващите стъпки, като използваме автоматично сумиране S. Стъпка 13. В клетка J26 въведете формулата = SUM(J1:J25). Стъпка 14. В клетка K26 въведете формулата = SUM(K1:K25). Стъпка 15. В клетка L26 въведете формулата = SUM(L1:L25). Стъпка 16. В клетка M26 въведете формулата = SUM(M1:M25). Стъпка 17. В клетка N26 въведете формулата = SUM(N1:N25). Стъпка 18. В клетка O26 въведете формулата = SUM(O1:O25). Сега нека изчислим коефициента на корелация, използвайки формула (8) (само за линейно приближение) и коефициента на детерминация, използвайки формула (10). Резултатите от изчисленията с помощта на Microsoft Excel са представени в таблица 8. Таблица 8
Коефициент на корелация Коефициент на детерминизъм (линейно приближение) Коефициент на детерминизъм (квадратично приближение) Коефициент на детерминизъм (експоненциално приближение) В клетка E57 формулата е написана =J26/(K26*L26)^(1/2). В клетка E59 е записана формулата = 1-M26/L26. В клетка E61 е записана формулата = 1-N26/L26. В клетка E63 е записана формулата = 1-O26/L26. Анализът на резултатите от изчисленията показва, че квадратичното приближение най-добре описва експерименталните данни. Диаграма на алгоритъма ориз. 1. Алгоритъмна диаграма за изчислителната програма. 5. Изчисляване в MathCad Линейна регресия · линия (x, y) - вектор от два елемента (b, a) коефициенти на линейна регресия b+ax; · x - вектор на реални аргументни данни; · y е вектор от реални стойности на данни с еднакъв размер. Фигура 2. Полиномна регресия означава приближаване на данните (x1, y1) с полином k-та степенЗа k=i полиномът е права линия, за k=2 е парабола, за k=3 е кубична парабола и т.н. По правило на практика к<5. · regress (x,y,k) - вектор от коефициенти за построяване на полиномна регресия на данни; · interp (s,x,y,t) - резултатът от полиномна регресия; · s=регресия(x,y,k); · x е вектор от реални аргументни данни, чиито елементи са подредени във възходящ ред; · y е вектор от реални стойности на данни с еднакъв размер; · k - степен на регресионен полином (цяло положително число); · t - стойността на аргумента на регресионния полином. Фигура 3 В допълнение към разгледаните, в Mathcad са вградени още няколко вида трипараметрични регресии, които се различават донякъде от горните регресионни опции по това, че за тях, в допълнение към масива от данни, е необходимо да се уточнят някои начални стойности; на коефициентите a, b, c. Използвайте подходящия тип регресия, ако имате добра представа какъв вид зависимост описва вашия набор от данни. Когато даден тип регресия не отразява добре последователност от данни, резултатът често е незадоволителен и дори много различен в зависимост от избора на начални стойности. Всяка от функциите произвежда вектор от прецизирани параметри a, b, c. Резултати, получени с помощта на функцията LINEST Нека да разгледаме целта на функцията LINEST. Тази функция използва най-малки квадрати, за да изчисли правата линия, която най-добре отговаря на наличните данни. Функцията връща масив, който описва получения ред. Уравнението за права линия е: M1x1 + m2x2 + ... + b или y = mx + b, таблица алгоритъм софтуер на microsoft където зависимата стойност y е функция на независимата стойност x. Стойностите на m са коефициентите, съответстващи на всяка независима променлива x, а b е константа. Обърнете внимание, че y, x и m могат да бъдат вектори. За да получите резултатите, трябва да създадете таблична формула, която ще заема 5 реда и 2 колони. Този интервал може да се намира навсякъде в работния лист. През този интервал трябва да въведете функцията LINEST. В резултат на това всички клетки от интервала A65:B69 трябва да бъдат запълнени (както е показано в таблица 9). Таблица 9.
Нека обясним предназначението на някои от количествата, разположени в таблица 9. Стойностите, разположени в клетки A65, характеризират съответно коефициента на детерминация - регресионна сума на квадратите. Представяне на резултатите под формата на графики ориз. 4. Линейна апроксимационна графика ориз. 5. Квадратна апроксимационна графика ориз. 6. Графика за експоненциално напасване Изводи Нека направим изводи въз основа на резултатите от получените данни. Анализът на резултатите от изчисленията показва, че квадратичното приближение най-добре описва експерименталните данни, т.к. тренд линията за него най-точно отразява поведението на функцията в тази област. Сравнявайки резултатите, получени с помощта на функцията LINEST, виждаме, че те напълно съвпадат с извършените по-горе изчисления. Това показва, че изчисленията са правилни. Резултатите, получени с помощта на програмата MathCad, напълно съвпадат със стойностите, дадени по-горе. Това показва точността на изчисленията. Списък на използваната литература 1 B.P. Демидович, И.А. Кестеняво. Основи на изчислителната математика. М: Държавно издателство за физико-математическа литература. 2 Информатика: Учебник, изд. проф. Н.В. Макарова. М: Финанси и статистика, 2007 г. 3 Информатика: Уъркшоп по компютърни технологии, изд. проф. Н.В. Макарова. М: Финанси и статистика, 2010. 4 V.B. Комягин. Програмиране в Excel с помощта на Visual Basic. М: Радио и комуникация, 2007. 5 Н. Никол, Р. Албрехт. Excel. Електронни таблици. М: Изд. "ЕКОМ", 2008г. 6 Указания за изпълнение на курсова работа по компютърни науки (за задочни студенти от всички специалности), изд. Журова Г. Н., Държавен хидрологичен институт в Санкт Петербург (ТУ), 2011 г.
![]() , (1)
, (1)
![]() :
:![]() (3)
(3)
 (4)
(4)
 (5)
(5)
![]() (7)
(7)
 (8)
(8) (9)
(9) (10)
(10)
![]() а числителят характеризира дисперсията на условните средни около безусловната средна.
а числителят характеризира дисперсията на условните средни около безусловната средна.![]() - регресионна сума от квадрати, характеризиращи разпространението на данните.
- регресионна сума от квадрати, характеризиращи разпространението на данните.
 (11)
(11)
![]() И .
И . (12)
(12)
 (13)
(13)
![]() . За определяне на коефициентите a1, a2 и a3 използваме система (5). Използвайки сумите от таблица 2, разположени в клетки A26, B26, C26, D26, E26, F26, G26, записваме система (5) във формата
. За определяне на коефициентите a1, a2 и a3 използваме система (5). Използвайки сумите от таблица 2, разположени в клетки A26, B26, C26, D26, E26, F26, G26, записваме система (5) във формата  (16)
(16)
![]() и
и ![]()
 (18)
(18)








Методът на най-малките квадрати е един от най-разпространените и най-разработените поради своята простота и ефективност на методите за оценка на параметрите на линейни. В същото време, когато го използвате, трябва да се внимава, тъй като моделите, конструирани с него, може да не отговарят на редица изисквания за качеството на техните параметри и в резултат на това да не отразяват „добре“ моделите на развитие на процеса .
Нека разгледаме по-подробно процедурата за оценка на параметрите на линеен иконометричен модел с помощта на метода на най-малките квадрати. Такъв модел най-общо може да бъде представен чрез уравнение (1.2):
y t = a 0 + a 1 x 1 t +...+ a n x nt + ε t.
Първоначалните данни при оценяване на параметрите a 0 , a 1 ,..., a n е вектор от стойности на зависимата променлива г= (y 1, y 2, ..., y T)" и матрицата от стойности на независими променливи

в която първата колона, състояща се от единици, съответства на коефициента на модела.
Методът на най-малките квадрати получи името си въз основа на основния принцип, че оценките на параметрите, получени на негова основа, трябва да удовлетворяват: сумата от квадратите на грешката на модела трябва да бъде минимална.
Примери за решаване на задачи по метода на най-малките квадрати
Пример 2.1.Търговското предприятие разполага с мрежа от 12 магазина, информация за дейността на които е представена в табл. 2.1.
Ръководството на предприятието би искало да знае как годишната сума зависи от търговската площ на магазина.
Таблица 2.1
|
Номер на магазина |
Годишен оборот, милиони рубли. |
Търговска площ, хил. м2 |
Решение на най-малките квадрати.Нека обозначим годишния оборот на магазина, милиони рубли; — търговска площ на магазина, хиляди m2.

Фиг.2.1. Точкова диаграма за пример 2.1
За да определим формата на функционалната връзка между променливите и ще изградим точкова диаграма (фиг. 2.1).
Въз основа на диаграмата на разсейване можем да заключим, че годишният оборот зависи положително от търговската площ (т.е. y ще нараства с увеличаване на ). Най-подходящата форма на функционална връзка е линеен.
Информация за допълнителни изчисления е представена в табл. 2.2. Използвайки метода на най-малките квадрати, ние оценяваме параметрите на линеен еднофакторен иконометричен модел

Таблица 2.2
по този начин
Следователно, с увеличаване на търговските площи с 1 хил. м2, при равни други условия, средният годишен оборот се увеличава с 67,8871 милиона рубли.
Пример 2.2.Ръководството на компанията забеляза, че годишният оборот зависи не само от търговската площ на магазина (виж пример 2.1), но и от средния брой посетители. Съответната информация е представена в табл. 2.3.
Таблица 2.3
Решение.Нека обозначим средния брой посетители на ти магазин на ден, хиляди души.
За да определим формата на функционалната връзка между променливите и ще изградим точкова диаграма (фиг. 2.2).
Въз основа на диаграмата на разсейване можем да заключим, че годишният оборот зависи положително от средния брой посетители на ден (т.е. y ще нараства с нарастване). Формата на функционалната зависимост е линейна.

ориз. 2.2. Точкова диаграма за пример 2.2
Таблица 2.4
Като цяло е необходимо да се определят параметрите на двуфакторен иконометричен модел
y t = a 0 + a 1 x 1 t + a 2 x 2 t + ε t
Информацията, необходима за по-нататъшни изчисления, е представена в табл. 2.4.
Нека оценим параметрите на линеен двуфакторен иконометричен модел, използвайки метода на най-малките квадрати.

по този начин
Оценката на коефициента =61,6583 показва, че при равни други условия, с увеличаване на търговската площ с 1 хил. м 2, годишният оборот ще се увеличи средно с 61,6583 милиона рубли.
(виж снимката). Трябва да намерите уравнението на права
Колкото по-малко е числото в абсолютна стойност, толкова по-добра е избраната права линия (2). Като характеристика на точността на избиране на права линия (2) можем да приемем сумата от квадрати
Минималните условия за S ще бъдат
 |
(6) |
 |
(7) |
Уравнения (6) и (7) могат да бъдат записани, както следва:
 |
(8) |
 |
(9) |
От уравнения (8) и (9) е лесно да се намерят a и b от експерименталните стойности на xi и y i. Линия (2), определена от уравнения (8) и (9), се нарича линия, получена чрез метода на най-малките квадрати (това име подчертава, че сборът от квадрати S има минимум). Уравнения (8) и (9), от които се определя правата (2), се наричат нормални уравнения.
Можете да посочите прост и общ начин за съставяне на нормални уравнения. Използвайки експериментални точки (1) и уравнение (2), можем да напишем система от уравнения за a и b
| y 1 = ax 1 + b, | |||
| y 2 = ax 2 + b, ... |
(10) | ||
| y n = ax n + b, | |||
Нека умножим лявата и дясната страна на всяко от тези уравнения по коефициента на първото неизвестно a (т.е. по x 1, x 2, ..., x n) и да добавим получените уравнения, което води до първото нормално уравнение (8) .
Нека умножим лявата и дясната страна на всяко от тези уравнения по коефициента на второто неизвестно b, т.е. с 1 и добавете получените уравнения, резултатът е второто нормално уравнение (9).
Този метод за получаване на нормални уравнения е общ: той е подходящ например за функцията
има постоянна стойност и тя трябва да се определи от експериментални данни (1).
Системата от уравнения за k може да бъде записана:
Намерете права линия (2), като използвате метода на най-малките квадрати.
Решение.Откриваме:
x i =21, y i =46,3, x i 2 =91, x i y i =179,1.
Записваме уравнения (8) и (9)
От тук намираме
Оценяване на точността на метода на най-малките квадрати
Нека дадем оценка на точността на метода за линейния случай, когато уравнение (2) е в сила.
Нека експерименталните стойности x i са точни, а експерименталните стойности y i имат случайни грешки със същата дисперсия за всички i.
Нека въведем нотацията
| (16) |
Тогава решенията на уравнения (8) и (9) могат да бъдат представени във формата
| (17) | |
| (18) | |
| Къде | |
| (19) | |
| От уравнение (17) намираме | |
| (20) | |
| По същия начин от уравнение (18) получаваме | |
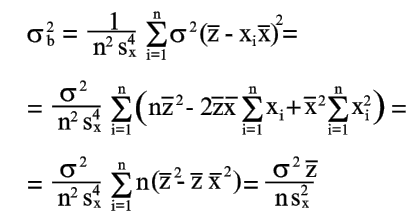 |
(21) |
| защото | |
| (22) | |
| От уравнения (21) и (22) намираме | |
 |
(23) |
Уравнения (20) и (23) осигуряват оценка на точността на коефициентите, определени от уравнения (8) и (9).
Имайте предвид, че коефициентите a и b са корелирани. Чрез прости трансформации намираме техния корелационен момент.
От тук намираме
0,072 при x=1 и 6,
0,041 при х=3,5.
Литература
Шор. Я. Б. Статистически методи за анализ и контрол на качеството и надеждността. М.: Госенергоиздат, 1962, с. 552, стр. 92-98.
Тази книга е предназначена за широк кръг инженери (научноизследователски институти, конструкторски бюра, тестови площадки и заводи), участващи в определянето на качеството и надеждността на електронно оборудване и други масови промишлени продукти (машиностроене, приборостроене, артилерия и др.).
Книгата предлага приложение на методите на математическата статистика при обработката и оценката на резултатите от изпитванията, които определят качеството и надеждността на изпитваните продукти. За улеснение на читателите е предоставена необходимата информация от математическата статистика, както и голям брой помощни математически таблици, които улесняват необходимите изчисления.
Презентацията е илюстрирана с голям брой примери от областта на радиоелектрониката и артилерийската техника.
Метод на най-малките квадрати
В последния урок по темата ще се запознаем с най-известното приложение FNP, който намира най-широко приложение в различни области на науката и практическата дейност. Това може да бъде физика, химия, биология, икономика, социология, психология и така нататък, и така нататък. По волята на съдбата често ми се налага да се занимавам с икономиката и затова днес ще организирам за вас пътуване до една невероятна страна, наречена Иконометрия=) ...Как да не искаш?! Там е много добре - просто трябва да вземете решение! ...Но това, което вероятно определено искате, е да се научите как да решавате проблеми метод на най-малките квадрати. И особено прилежните читатели ще се научат да ги решават не само точно, но и МНОГО БЪРЗО ;-) Но първо общо изложение на проблема+ придружаващ пример:
Да предположим, че в определена предметна област се изучават показатели, които имат количествен израз. В същото време има всички основания да се смята, че индикаторът зависи от индикатора. Това предположение може да бъде или научна хипотеза, или да се основава на основен здрав разум. Да оставим науката настрана обаче и да разгледаме по-апетитните области – а именно хранителните магазини. Да означим с:
– търговска площ на магазин за хранителни стоки, кв.м.,
– годишен оборот на магазин за хранителни стоки, милиона рубли.
Абсолютно ясно е, че колкото по-голяма е площта на магазина, толкова по-голям в повечето случаи ще бъде неговият оборот.
Да приемем, че след извършване на наблюдения/експерименти/изчисления/танци с тамбура имаме на разположение числени данни: 
С магазините за хранителни стоки мисля, че всичко е ясно: - това е площта на 1-ви магазин, - годишният му оборот, - площта на 2-ри магазин, - годишният му оборот и т.н. Между другото, изобщо не е необходимо да имате достъп до класифицирани материали - доста точна оценка на търговския оборот може да се получи с помощта на математическа статистика. Но нека не се разсейваме, курсът по търговски шпионаж вече е платен =)
Табличните данни също могат да бъдат записани под формата на точки и изобразени в познатата форма Декартова система .
Нека отговорим на един важен въпрос: Колко точки са необходими за качествено изследване?
Колкото повече, толкова по-добре. Минималният приемлив набор се състои от 5-6 точки. Освен това, когато количеството данни е малко, „аномалните“ резултати не могат да бъдат включени в извадката. Така например малък елитен магазин може да спечели порядъци повече от „колегите си“, като по този начин изкриви общия модел, който трябва да намерите!
Казано много просто, трябва да изберем функция, графиккойто минава възможно най-близо до точките ![]() . Тази функция се нарича приближаващ
(приближение - приближение)или теоретична функция
. Най-общо казано, тук веднага се появява очевиден „претендент“ - полином от висока степен, чиято графика минава през ВСИЧКИ точки. Но тази опция е сложна и често просто неправилна. (тъй като графиката ще се „върти“ през цялото време и ще отразява слабо основната тенденция).
. Тази функция се нарича приближаващ
(приближение - приближение)или теоретична функция
. Най-общо казано, тук веднага се появява очевиден „претендент“ - полином от висока степен, чиято графика минава през ВСИЧКИ точки. Но тази опция е сложна и често просто неправилна. (тъй като графиката ще се „върти“ през цялото време и ще отразява слабо основната тенденция).
По този начин търсената функция трябва да бъде доста проста и в същото време адекватно да отразява зависимостта. Както можете да се досетите, един от методите за намиране на такива функции се нарича метод на най-малките квадрати. Първо, нека да разгледаме неговата същност в общи линии. Нека някаква функция апроксимира експериментални данни: 
Как да оценим точността на това приближение? Нека изчислим и разликите (отклоненията) между експерименталните и функционалните стойности (изучаваме чертежа). Първата мисъл, която идва на ум, е да преценим колко голяма е сумата, но проблемът е, че разликите могат да бъдат отрицателни (Например, ![]() )
и отклоненията в резултат на такова сумиране ще се компенсират взаимно. Следователно, като оценка на точността на приближението, е добре да се вземе сумата модулиотклонения:
)
и отклоненията в резултат на такова сумиране ще се компенсират взаимно. Следователно, като оценка на точността на приближението, е добре да се вземе сумата модулиотклонения:
![]() или свито: (ако някой не знае:
е иконата за сума и
– спомагателна променлива „брояч“, която приема стойности от 1 до
)
.
или свито: (ако някой не знае:
е иконата за сума и
– спомагателна променлива „брояч“, която приема стойности от 1 до
)
.
Чрез приближаване на експериментални точки с различни функции, ще получим различни стойности и очевидно, когато тази сума е по-малка, тази функция е по-точна.
Такъв метод съществува и се нарича метод на най-малък модул. На практика обаче той стана много по-разпространен метод на най-малките квадрати, при които възможните отрицателни стойности се елиминират не от модула, а чрез квадратиране на отклоненията:
![]() , след което усилията са насочени към избор на функция, така че сумата на квадратите на отклоненията
, след което усилията са насочени към избор на функция, така че сумата на квадратите на отклоненията ![]() беше възможно най-малък. Всъщност от тук идва и името на метода.
беше възможно най-малък. Всъщност от тук идва и името на метода.
И сега се връщаме към друг важен момент: както беше отбелязано по-горе, избраната функция трябва да е доста проста - но има и много такива функции: линеен , хиперболичен , експоненциален , логаритмичен , квадратна и т.н. И, разбира се, тук веднага бих искал да „намаля сферата на дейност“. Кой клас функции трябва да избера за изследване? Примитивна, но ефективна техника:
– Най-лесният начин е да изобразите точки ![]() върху чертежа и анализирайте местоположението им. Ако те са склонни да се движат по права линия, тогава трябва да потърсите уравнение на права
върху чертежа и анализирайте местоположението им. Ако те са склонни да се движат по права линия, тогава трябва да потърсите уравнение на права ![]() с оптимални стойности и . С други думи, задачата е да се намерят ТАКИВА коефициенти, така че сумата на квадратите на отклоненията да е най-малка.
с оптимални стойности и . С други думи, задачата е да се намерят ТАКИВА коефициенти, така че сумата на квадратите на отклоненията да е най-малка.
Ако точките са разположени, например, по хипербола, тогава очевидно е ясно, че линейната функция ще даде лошо приближение. В този случай ние търсим най-„благоприятните“ коефициенти за уравнението на хиперболата ![]() – тези, които дават минималния сбор от квадрати
– тези, които дават минималния сбор от квадрати  .
.
Сега имайте предвид, че и в двата случая говорим за функции на две променливи, чиито аргументи са търсени параметри на зависимост:
И по същество трябва да решим стандартен проблем - намери минимална функция на две променливи.
Нека си спомним нашия пример: да предположим, че точките на „магазин“ обикновено са разположени в права линия и има всички основания да се смята, че линейна зависимостоборот от търговски площи. Нека намерим ТАКИВА коефициенти “a” и “be”, така че сумата от квадратите на отклоненията ![]() беше най-малкият. Всичко е както обикновено - първо Частични производни от 1-ви ред. Според правило за линейностМожете да разграничите точно под иконата за сума:
беше най-малкият. Всичко е както обикновено - първо Частични производни от 1-ви ред. Според правило за линейностМожете да разграничите точно под иконата за сума: 
Ако искате да използвате тази информация за есе или курсова работа, ще бъда много благодарен за връзката в списъка с източници, на няколко места ще намерите такива подробни изчисления: 
Нека създадем стандартна система: 
Ние намаляваме всяко уравнение с „две“ и в допълнение „разбиваме“ сумите: 
Забележка
: независимо анализирайте защо „a“ и „be“ могат да бъдат извадени отвъд иконата за сума. Между другото, формално това може да стане със сумата ![]()
Нека пренапишем системата в „приложна“ форма: 
след което алгоритъмът за решаване на нашия проблем започва да се появява:
Знаем ли координатите на точките? Ние знаем. суми ![]() можем ли да го намерим? Лесно. Нека направим най-простото система от две линейни уравнения с две неизвестни(„а“ и „бъди“). Решаваме системата, напр. Методът на Крамер, в резултат на което получаваме неподвижна точка. Проверка достатъчно условие за екстремум, можем да проверим, че в този момент функцията
можем ли да го намерим? Лесно. Нека направим най-простото система от две линейни уравнения с две неизвестни(„а“ и „бъди“). Решаваме системата, напр. Методът на Крамер, в резултат на което получаваме неподвижна точка. Проверка достатъчно условие за екстремум, можем да проверим, че в този момент функцията ![]() достига точно минимум. Проверката включва допълнителни изчисления и затова ще я оставим зад кулисите (при необходимост може да се види липсващата рамкатук
)
. Правим окончателното заключение:
достига точно минимум. Проверката включва допълнителни изчисления и затова ще я оставим зад кулисите (при необходимост може да се види липсващата рамкатук
)
. Правим окончателното заключение:
функция ![]() по възможно най-добрия начин (поне в сравнение с всяка друга линейна функция)сближава експерименталните точки
по възможно най-добрия начин (поне в сравнение с всяка друга линейна функция)сближава експерименталните точки ![]() . Грубо казано, неговата графика минава възможно най-близо до тези точки. В традицията иконометрияполучената апроксимираща функция също се нарича сдвоено уравнение на линейна регресия
.
. Грубо казано, неговата графика минава възможно най-близо до тези точки. В традицията иконометрияполучената апроксимираща функция също се нарича сдвоено уравнение на линейна регресия
.
Разглежданият проблем е от голямо практическо значение. В нашата примерна ситуация, ур. ![]() ви позволява да предвидите какъв търговски оборот ("Игрек")магазинът ще има при една или друга стойност на търговската площ (едно или друго значение на "х"). Да, получената прогноза ще бъде само прогноза, но в много случаи ще се окаже доста точна.
ви позволява да предвидите какъв търговски оборот ("Игрек")магазинът ще има при една или друга стойност на търговската площ (едно или друго значение на "х"). Да, получената прогноза ще бъде само прогноза, но в много случаи ще се окаже доста точна.
Ще анализирам само един проблем с „реални“ числа, тъй като в него няма трудности - всички изчисления са на нивото на училищната програма за 7-8 клас. В 95 процента от случаите ще бъдете помолени да намерите само линейна функция, но в самия край на статията ще покажа, че не е по-трудно да намерите уравненията на оптималната хипербола, експоненциалната и някои други функции.
Всъщност остава само да раздадете обещаните лакомства - за да се научите да решавате подобни примери не само точно, но и бързо. Ние внимателно изучаваме стандарта:
Задача
В резултат на изследване на връзката между два показателя бяха получени следните двойки числа: 
Използвайки метода на най-малките квадрати, намерете линейната функция, която най-добре приближава емпиричната (опитен)данни. Направете чертеж, върху който да построите експериментални точки и графика на апроксимиращата функция в декартова правоъгълна координатна система ![]() . Намерете сумата от квадратите на отклоненията между емпиричните и теоретичните стойности. Разберете дали функцията би била по-добра (от гледна точка на метода на най-малките квадрати)доближете експерименталните точки.
. Намерете сумата от квадратите на отклоненията между емпиричните и теоретичните стойности. Разберете дали функцията би била по-добра (от гледна точка на метода на най-малките квадрати)доближете експерименталните точки.
Моля, обърнете внимание, че значенията на „x“ са естествени и това има характерно смислово значение, за което ще говоря малко по-късно; но те, разбира се, могат да бъдат и дробни. Освен това, в зависимост от съдържанието на конкретна задача, стойностите на „X“ и „игра“ могат да бъдат напълно или частично отрицателни. Е, дадена ни е „безлична“ задача и започваме решение:
Намираме коефициентите на оптималната функция като решение на системата: 
С цел по-компактен запис, променливата „брояч“ може да бъде пропусната, тъй като вече е ясно, че сумирането се извършва от 1 до .
По-удобно е да се изчислят необходимите количества в таблична форма: 
Изчисленията могат да се извършват на микрокалкулатор, но е много по-добре да използвате Excel - както по-бързо, така и без грешки; вижте кратко видео:
Така получаваме следното система:![]()
Тук можете да умножите второто уравнение по 3 и извадете 2-то от 1-вото уравнение член по член. Но това е късмет - на практика системите често не са подарък и в такива случаи спестява Методът на Крамер:
, което означава, че системата има уникално решение.

Да проверим. Разбирам, че не искате, но защо пропускате грешки, когато те абсолютно не могат да бъдат пропуснати? Нека заместим намереното решение в лявата част на всяко уравнение на системата:
Получават се десните части на съответните уравнения, което означава, че системата е решена правилно.
Така желаната апроксимираща функция: – от всички линейни функцииТя е тази, която най-добре приближава експерименталните данни.
За разлика от директен
зависимост на оборота на магазина от неговата площ, установената зависимост е обратен
(принцип "колкото повече, толкова по-малко"), и този факт веднага се разкрива от негатива наклон. функция ![]() ни казва, че с увеличаване на определен показател с 1 единица, стойността на зависимия показател намалява среднос 0,65 единици. Както се казва, колкото по-висока е цената на елдата, толкова по-малко се продава.
ни казва, че с увеличаване на определен показател с 1 единица, стойността на зависимия показател намалява среднос 0,65 единици. Както се казва, колкото по-висока е цената на елдата, толкова по-малко се продава.
За да начертаем апроксимиращата функция, нека намерим нейните две стойности:
и изпълнете чертежа: 
Построената права се нарича тренд линия
(а именно линейна линия на тенденция, т.е. в общия случай тенденцията не е непременно права линия). Всеки е запознат с израза „да бъдеш в тенденция“ и смятам, че този термин не се нуждае от допълнителни коментари.
Нека изчислим сумата на квадратите на отклоненията ![]() между емпирични и теоретични стойности. Геометрично това е сумата от квадратите на дължините на сегментите „малина“. (две от които са толкова малки, че дори не се виждат).
между емпирични и теоретични стойности. Геометрично това е сумата от квадратите на дължините на сегментите „малина“. (две от които са толкова малки, че дори не се виждат).
Нека обобщим изчисленията в таблица: 
Те отново могат да се направят ръчно за всеки случай, ще дам пример за 1-ва точка: ![]()
но е много по-ефективно да го направите по вече познатия начин:
Повтаряме още веднъж: Какъв е смисълът на получения резултат?от всички линейни функции y функция ![]() индикаторът е най-малкият, тоест в своето семейство той е най-доброто приближение. И тук, между другото, последният въпрос на проблема не е случаен: какво ще стане, ако предложената експоненциална функция
индикаторът е най-малкият, тоест в своето семейство той е най-доброто приближение. И тук, между другото, последният въпрос на проблема не е случаен: какво ще стане, ако предложената експоненциална функция ![]() би ли било по-добре да сближим експерименталните точки?
би ли било по-добре да сближим експерименталните точки?
Нека намерим съответната сума от квадратни отклонения - за да ги различим, ще ги обознача с буквата "епсилон". Техниката е абсолютно същата: 
И отново, за всеки случай, изчисления за 1-ва точка: 
В Excel използваме стандартната функция EXP (синтаксисът може да бъде намерен в помощта на Excel).
Заключение: , което означава, че експоненциалната функция приближава експерименталните точки по-лошо от права линия ![]() .
.
Но тук трябва да се отбележи, че "по-лошо" е още не означава, което е лошо. Сега построих графика на тази експоненциална функция - и тя също минава близо до точките ![]() - толкова много, че без аналитични изследвания е трудно да се каже коя функция е по-точна.
- толкова много, че без аналитични изследвания е трудно да се каже коя функция е по-точна.
Това завършва решението и се връщам към въпроса за естествените стойности на аргумента. В различни изследвания, обикновено икономически или социологически, естествените „Х“ се използват за номериране на месеци, години или други равни интервали от време. Помислете например за следния проблем:
За оборота на дребно на магазина за първото полугодие има следните данни:
Използвайки аналитично подреждане по права линия, определете обема на оборота за юли.
Да, няма проблем: номерираме месеците 1, 2, 3, 4, 5, 6 и използваме обичайния алгоритъм, в резултат на което получаваме уравнение - единственото нещо е, че когато става въпрос за време, те обикновено използват буквата "те" (въпреки че това не е критично). Полученото уравнение показва, че през първото полугодие търговският оборот се е увеличил средно с 27,74 единици. на месец. Да вземем прогнозата за юли (месец № 7): д.е.
И има безброй задачи като тази. Желаещите могат да ползват допълнителна услуга, а именно моята Ексел калкулатор (демо версия), което решава анализирания проблем почти моментално!Налична е работеща версия на програмата на размянаили за символична такса.
В края на урока, кратка информация за намирането на зависимости от някои други типове. Всъщност няма много какво да се каже, тъй като основният подход и алгоритъмът за решение остават същите.
Да приемем, че разположението на експерименталните точки прилича на хипербола. След това, за да намерите коефициентите на най-добрата хипербола, трябва да намерите минимума на функцията - всеки може да извърши подробни изчисления и да стигне до подобна система: 
От формална техническа гледна точка се получава от „линейна“ система  (нека го обозначим със звездичка)замяна на "x" с . Е, какво ще кажете за сумите?
(нека го обозначим със звездичка)замяна на "x" с . Е, какво ще кажете за сумите? ![]() изчисляване, след което до оптималните коефициенти „а“ и „бе“ под ръка.
изчисляване, след което до оптималните коефициенти „а“ и „бе“ под ръка.
Ако има всички основания да се смята, че точките ![]() са разположени по логаритмична крива, след което, за да намерим оптималните стойности, намираме минимума на функцията
са разположени по логаритмична крива, след което, за да намерим оптималните стойности, намираме минимума на функцията ![]() . Формално, в системата (*) трябва да се замени с:
. Формално, в системата (*) трябва да се замени с: 
Когато извършвате изчисления в Excel, използвайте функцията LN. Признавам, че няма да ми е особено трудно да създам калкулатори за всеки от разглежданите случаи, но все пак би било по-добре, ако сами „програмирате“ изчисленията. Видео уроци в помощ.
С експоненциалната зависимост ситуацията е малко по-сложна. За да намалим материята до линейния случай, ние вземаме функцията логаритъм и използваме свойства на логаритъма:
Сега, сравнявайки получената функция с линейната функция, стигаме до извода, че в системата (*) трябва да се замени с , а – с . За удобство нека обозначим: 
Моля, имайте предвид, че системата е разрешена по отношение на и, и следователно, след като намерите корените, не трябва да забравяте да намерите самия коефициент.
За да доближим експерименталните точки ![]() оптимална парабола
оптимална парабола ![]() , трябва да се намери минимална функция на три променливи
, трябва да се намери минимална функция на три променливи ![]() . След извършване на стандартни действия получаваме следното „работещо“ система:
. След извършване на стандартни действия получаваме следното „работещо“ система:
Да, разбира се, тук има повече суми, но няма никакви затруднения, когато използвате любимото си приложение. И накрая, ще ви кажа как бързо да извършите проверка с помощта на Excel и да изградите желаната линия на тренда: създайте точкова диаграма, изберете някоя от точките с мишката ![]() и щракнете с десния бутон изберете опцията „Добавяне на тренд линия“. След това изберете типа диаграма и в раздела "Опции"активирайте опцията „Покажи уравнението на диаграмата“. добре
и щракнете с десния бутон изберете опцията „Добавяне на тренд линия“. След това изберете типа диаграма и в раздела "Опции"активирайте опцията „Покажи уравнението на диаграмата“. добре
Както винаги, искам да завърша статията с красива фраза и почти написах „Бъдете в тенденция!“ Но навреме промени решението си. И не защото е стереотипно. Не знам как е за никого, но аз не искам да следвам промотираната американска и особено европейска тенденция =) Затова пожелавам на всеки от вас да се придържа към собствената си линия!
http://www.grandars.ru/student/vysshaya-matematika/metod-naimenshih-kvadratov.html
Методът на най-малките квадрати е един от най-разпространените и най-разработените поради своята простота и ефективност на методите за оценка на параметрите на линейни иконометрични модели. В същото време, когато го използвате, трябва да се внимава, тъй като моделите, конструирани с него, може да не отговарят на редица изисквания за качеството на техните параметри и в резултат на това да не отразяват „добре“ моделите на развитие на процеса .
Нека разгледаме по-подробно процедурата за оценка на параметрите на линеен иконометричен модел с помощта на метода на най-малките квадрати. Такъв модел най-общо може да бъде представен чрез уравнение (1.2):
y t = a 0 + a 1 x 1t +...+ a n x nt + ε t.
Първоначалните данни при оценяване на параметрите a 0 , a 1 ,..., a n е вектор от стойности на зависимата променлива г= (y 1, y 2, ..., y T)" и матрицата от стойности на независими променливи

в която първата колона, състояща се от единици, съответства на коефициента на модела.
Методът на най-малките квадрати получи името си въз основа на основния принцип, че оценките на параметрите, получени на негова основа, трябва да удовлетворяват: сумата от квадратите на грешката на модела трябва да бъде минимална.
Примери за решаване на задачи по метода на най-малките квадрати
Пример 2.1.Търговското предприятие разполага с мрежа от 12 магазина, информация за дейността на които е представена в табл. 2.1.
Ръководството на предприятието би искало да знае как размерът на годишния оборот зависи от търговската площ на магазина.
Таблица 2.1
| Номер на магазина | Годишен оборот, милиони рубли. | Търговска площ, хил. м2 |
| 19,76 | 0,24 | |
| 38,09 | 0,31 | |
| 40,95 | 0,55 | |
| 41,08 | 0,48 | |
| 56,29 | 0,78 | |
| 68,51 | 0,98 | |
| 75,01 | 0,94 | |
| 89,05 | 1,21 | |
| 91,13 | 1,29 | |
| 91,26 | 1,12 | |
| 99,84 | 1,29 | |
| 108,55 | 1,49 |
Решение на най-малките квадрати.Нека обозначим годишния оборот на магазина, милиони рубли; - търговска площ на магазина, хиляди m2.

Фиг.2.1. Точкова диаграма за пример 2.1
За да определим формата на функционалната връзка между променливите и ще изградим точкова диаграма (фиг. 2.1).
Въз основа на диаграмата на разсейване можем да заключим, че годишният оборот зависи положително от търговската площ (т.е. y ще нараства с увеличаване на ). Най-подходящата форма на функционална връзка е линеен.
Информация за допълнителни изчисления е представена в табл. 2.2. Използвайки метода на най-малките квадрати, ние оценяваме параметрите на линеен еднофакторен иконометричен модел

Таблица 2.2
| t | y t | х 1т | y t 2 | х 1т 2 | x 1t y t |
| 19,76 | 0,24 | 390,4576 | 0,0576 | 4,7424 | |
| 38,09 | 0,31 | 1450,8481 | 0,0961 | 11,8079 | |
| 40,95 | 0,55 | 1676,9025 | 0,3025 | 22,5225 | |
| 41,08 | 0,48 | 1687,5664 | 0,2304 | 19,7184 | |
| 56,29 | 0,78 | 3168,5641 | 0,6084 | 43,9062 | |
| 68,51 | 0,98 | 4693,6201 | 0,9604 | 67,1398 | |
| 75,01 | 0,94 | 5626,5001 | 0,8836 | 70,5094 | |
| 89,05 | 1,21 | 7929,9025 | 1,4641 | 107,7505 | |
| 91,13 | 1,29 | 8304,6769 | 1,6641 | 117,5577 | |
| 91,26 | 1,12 | 8328,3876 | 1,2544 | 102,2112 | |
| 99,84 | 1,29 | 9968,0256 | 1,6641 | 128,7936 | |
| 108,55 | 1,49 | 11783,1025 | 2,2201 | 161,7395 | |
| С | 819,52 | 10,68 | 65008,554 | 11,4058 | 858,3991 |
| Средно | 68,29 | 0,89 |
по този начин
Следователно, с увеличаване на търговските площи с 1 хил. м2, при равни други условия, средният годишен оборот се увеличава с 67,8871 милиона рубли.
Пример 2.2.Ръководството на компанията забеляза, че годишният оборот зависи не само от търговската площ на магазина (виж пример 2.1), но и от средния брой посетители. Съответната информация е представена в табл. 2.3.
Таблица 2.3
Решение.Нека обозначим - средният брой посетители на ти магазин на ден, хиляди души.
За да определим формата на функционалната връзка между променливите и ще изградим точкова диаграма (фиг. 2.2).
Въз основа на диаграмата на разсейване можем да заключим, че годишният оборот зависи положително от средния брой посетители на ден (т.е. y ще нараства с нарастване). Формата на функционалната зависимост е линейна.

ориз. 2.2. Точкова диаграма за пример 2.2
Таблица 2.4
| t | х 2т | x 2t 2 | y t x 2t | x 1t x 2t |
| 8,25 | 68,0625 | 163,02 | 1,98 | |
| 10,24 | 104,8575 | 390,0416 | 3,1744 | |
| 9,31 | 86,6761 | 381,2445 | 5,1205 | |
| 11,01 | 121,2201 | 452,2908 | 5,2848 | |
| 8,54 | 72,9316 | 480,7166 | 6,6612 | |
| 7,51 | 56,4001 | 514,5101 | 7,3598 | |
| 12,36 | 152,7696 | 927,1236 | 11,6184 | |
| 10,81 | 116,8561 | 962,6305 | 13,0801 | |
| 9,89 | 97,8121 | 901,2757 | 12,7581 | |
| 13,72 | 188,2384 | 1252,0872 | 15,3664 | |
| 12,27 | 150,5529 | 1225,0368 | 15,8283 | |
| 13,92 | 193,7664 | 1511,016 | 20,7408 | |
| С | 127,83 | 1410,44 | 9160,9934 | 118,9728 |
| Средно | 10,65 |
Като цяло е необходимо да се определят параметрите на двуфакторен иконометричен модел
y t = a 0 + a 1 x 1t + a 2 x 2t + ε t
Информацията, необходима за по-нататъшни изчисления, е представена в табл. 2.4.
Нека оценим параметрите на линеен двуфакторен иконометричен модел, използвайки метода на най-малките квадрати.

по този начин
Оценката на коефициента =61,6583 показва, че при равни други условия, с увеличаване на търговската площ с 1 хил. м 2, годишният оборот ще се увеличи средно с 61,6583 милиона рубли.
Оценката на коефициента = 2,2748 показва, че при равни други условия с увеличение на средния брой посетители на 1 хил. души. на ден, годишният оборот ще се увеличи средно с 2,2748 милиона рубли.
Пример 2.3.Използвайки информацията, представена в табл. 2.2 и 2.4, оценяват параметъра на еднофакторния иконометричен модел
![]()
където е центрираната стойност на годишния оборот на магазина, милиони рубли; - центрирана стойност на средния дневен брой посетители на t-тия магазин, хиляди души. (вижте примери 2.1-2.2).
Решение.Допълнителна информация, необходима за изчисленията, е представена в табл. 2.5.
Таблица 2.5
| -48,53 | -2,40 | 5,7720 | 116,6013 | |
| -30,20 | -0,41 | 0,1702 | 12,4589 | |
| -27,34 | -1,34 | 1,8023 | 36,7084 | |
| -27,21 | 0,36 | 0,1278 | -9,7288 | |
| -12,00 | -2,11 | 4,4627 | 25,3570 | |
| 0,22 | -3,14 | 9,8753 | -0,6809 | |
| 6,72 | 1,71 | 2,9156 | 11,4687 | |
| 20,76 | 0,16 | 0,0348 | 3,2992 | |
| 22,84 | -0,76 | 0,5814 | -17,413 | |
| 22,97 | 3,07 | 9,4096 | 70,4503 | |
| 31,55 | 1,62 | 2,6163 | 51,0267 | |
| 40,26 | 3,27 | 10,6766 | 131,5387 | |
| Сума | 48,4344 | 431,0566 |
Използвайки формула (2.35), получаваме

по този начин
![]()
http://www.cleverstudents.ru/articles/mnk.html
Пример.
Експериментални данни за стойностите на променливите Xи приса дадени в таблицата. 
В резултат на тяхното подравняване се получава функцията ![]()
Използване метод на най-малките квадрати, апроксимирайте тези данни чрез линейна зависимост y=ax+b(намерете параметри Ав смисъл на максимална близост на векторите b). Открийте коя от двете линии по-добре (в смисъла на метода на най-малките квадрати) подравнява експерименталните данни. Направете рисунка.
Решение.
В нашия пример n=5. Попълваме таблицата за удобство при изчисляване на сумите, които са включени във формулите на необходимите коефициенти. 
Стойностите в четвъртия ред на таблицата се получават чрез умножаване на стойностите на 2-ри ред по стойностите на 3-ти ред за всяко число аз.
Стойностите в петия ред на таблицата се получават чрез повдигане на квадрат на стойностите във 2-ри ред за всяко число аз.
Стойностите в последната колона на таблицата са сумите от стойностите в редовете.
Използваме формулите на метода на най-малките квадрати, за да намерим коефициентите Ав смисъл на максимална близост на векторите b. Заменяме съответните стойности от последната колона на таблицата в тях: 
следователно y = 0,165x+2,184- желаната апроксимираща права линия.
Остава да разберем коя от линиите y = 0,165x+2,184или ![]() приближава по-добре оригиналните данни, т.е. оценки, използващи метода на най-малките квадрати.
приближава по-добре оригиналните данни, т.е. оценки, използващи метода на най-малките квадрати.
Доказателство.
Така че, когато се намери Ав смисъл на максимална близост на векторите bфункция приема най-малката стойност, необходимо е в тази точка матрицата на квадратната форма на диференциала от втори ред за функцията ![]() беше положително категоричен. Нека го покажем.
беше положително категоричен. Нека го покажем.
Диференциалът от втори ред има формата: 
това е
Следователно матрицата на квадратна форма има формата 
и стойностите на елементите не зависят от Аи b.
Нека покажем, че матрицата е положително определена. За да направите това, ъгловите минори трябва да са положителни.
Ъглов минор от първи ред  . Неравенството е строго, тъй като точките
. Неравенството е строго, тъй като точките