
Least squares linear function. Function approximation by the least squares method. Brief theory of the method of least squares for linear dependence
Ordinary Least Squares (OLS)- a mathematical method used to solve various problems, based on minimizing the sum of the squares of the deviations of some functions from the desired variables. It can be used to "solve" overdetermined systems of equations (when the number of equations exceeds the number of unknowns), to find a solution in the case of ordinary (not overdetermined) nonlinear systems of equations, to approximate the point values of some function. OLS is one of the basic regression analysis methods for estimating unknown parameters of regression models based on sample data.
Collegiate YouTube
1 / 5
✪ Least squares method. Theme
✪ Least squares lesson 1/2. Linear function
✪ Econometrics. Lecture 5 Least squares method
✪ Mitin IV - Processing of the results of physical. Experiment - Least Squares Method (Lecture 4)
✪ Econometrics: Understanding Least Squares # 2
Subtitles
History
Until the beginning of the 19th century. scientists did not have definite rules for solving a system of equations in which the number of unknowns is less than the number of equations; Until that time, particular methods were used that depended on the type of equations and on the wit of calculators, and therefore different calculators, based on the same observational data, came to different conclusions. Gauss (1795) was the author of the first application of the method, and Legendre (1805) independently discovered and published it under the modern name (fr. Méthode des moindres quarrés). Laplace linked the method with the theory of probability, and the American mathematician Edrain (1808) considered its theoretical and probabilistic applications. The method was spread and improved by further research by Encke, Bessel, Hansen and others.
The essence of the least squares method
Let be x (\ displaystyle x)- kit n (\ displaystyle n) unknown variables (parameters), f i (x) (\ displaystyle f_ (i) (x)), , m> n (\ displaystyle m> n)- a set of functions from this set of variables. The task is to select such values x (\ displaystyle x) so that the values of these functions are as close as possible to some values y i (\ displaystyle y_ (i))... In essence, we are talking about the "solution" of the overdetermined system of equations f i (x) = y i (\ displaystyle f_ (i) (x) = y_ (i)), i = 1,…, m (\ displaystyle i = 1, \ ldots, m) in the indicated sense of the maximum proximity of the left and right parts of the system. The essence of the LSM is to choose the sum of the squares of the deviations of the left and right sides as a "measure of proximity" | f i (x) - y i | (\ displaystyle | f_ (i) (x) -y_ (i) |)... Thus, the essence of OLS can be expressed as follows:
∑ iei 2 = ∑ i (yi - fi (x)) 2 → min x (\ displaystyle \ sum _ (i) e_ (i) ^ (2) = \ sum _ (i) (y_ (i) -f_ ( i) (x)) ^ (2) \ rightarrow \ min _ (x)).If the system of equations has a solution, then the minimum of the sum of squares will be equal to zero and exact solutions of the system of equations can be found analytically or, for example, by various numerical optimization methods. If the system is redefined, that is, speaking loosely, the number of independent equations is greater than the number of sought variables, then the system does not have an exact solution and the least squares method allows you to find some “optimal” vector x (\ displaystyle x) in the sense of maximum proximity of vectors y (\ displaystyle y) and f (x) (\ displaystyle f (x)) or the maximum proximity of the vector of deviations e (\ displaystyle e) to zero (proximity is understood in the sense of Euclidean distance).
Example - a system of linear equations
In particular, the least squares method can be used to "solve" a system of linear equations
A x = b (\ displaystyle Ax = b),where A (\ displaystyle A) rectangular size matrix m × n, m> n (\ displaystyle m \ times n, m> n)(i.e., the number of rows of matrix A is more than the number of sought variables).
In the general case, such a system of equations has no solution. Therefore, this system can be "solved" only in the sense of choosing such a vector x (\ displaystyle x) to minimize the "distance" between vectors A x (\ displaystyle Ax) and b (\ displaystyle b)... To do this, you can apply the criterion for minimizing the sum of squares of the differences between the left and right sides of the equations of the system, that is, (A x - b) T (A x - b) → min x (\ displaystyle (Ax-b) ^ (T) (Ax-b) \ rightarrow \ min _ (x))... It is easy to show that the solution of this minimization problem leads to the solution of the following system of equations
ATA x = AT b ⇒ x = (ATA) - 1 AT b (\ displaystyle A ^ (T) Ax = A ^ (T) b \ Rightarrow x = (A ^ (T) A) ^ (- 1) A ^ (T) b).OLS in regression analysis (data fit)
Let there be n (\ displaystyle n) values of some variable y (\ displaystyle y)(these can be the results of observations, experiments, etc.) and the corresponding variables x (\ displaystyle x)... The challenge is to ensure that the relationship between y (\ displaystyle y) and x (\ displaystyle x) approximate by some function known up to some unknown parameters b (\ displaystyle b), that is, in fact, find the best values of the parameters b (\ displaystyle b), maximally approximating values f (x, b) (\ displaystyle f (x, b)) to actual values y (\ displaystyle y)... In fact, this reduces to the case of a "solution" of an overdetermined system of equations with respect to b (\ displaystyle b):
F (x t, b) = y t, t = 1,…, n (\ displaystyle f (x_ (t), b) = y_ (t), t = 1, \ ldots, n).
In regression analysis, and in econometrics in particular, probabilistic models of the relationship between variables are used
Y t = f (x t, b) + ε t (\ displaystyle y_ (t) = f (x_ (t), b) + \ varepsilon _ (t)),
where ε t (\ displaystyle \ varepsilon _ (t))- so called random errors models.
Accordingly, the deviations of the observed values y (\ displaystyle y) from model f (x, b) (\ displaystyle f (x, b)) is assumed already in the model itself. The essence of OLS (ordinary, classical) is to find such parameters b (\ displaystyle b) for which the sum of squares of deviations (errors, for regression models they are often called regression residuals) e t (\ displaystyle e_ (t)) will be minimal:
b ^ O L S = arg min b R S S (b) (\ displaystyle (\ hat (b)) _ (OLS) = \ arg \ min _ (b) RSS (b)),where R S S (\ displaystyle RSS)- English. Residual Sum of Squares is defined as:
RSS (b) = e T e = ∑ t = 1 net 2 = ∑ t = 1 n (yt - f (xt, b)) 2 (\ displaystyle RSS (b) = e ^ (T) e = \ sum _ (t = 1) ^ (n) e_ (t) ^ (2) = \ sum _ (t = 1) ^ (n) (y_ (t) -f (x_ (t), b)) ^ (2) ).In the general case, this problem can be solved by numerical optimization (minimization) methods. In this case, they talk about nonlinear least squares(NLS or NLLS - English Non-Linear Least Squares). In many cases, an analytical solution can be obtained. To solve the minimization problem, it is necessary to find the stationary points of the function R S S (b) (\ displaystyle RSS (b)), differentiating it by unknown parameters b (\ displaystyle b), equating the derivatives to zero and solving the resulting system of equations:
∑ t = 1 n (yt - f (xt, b)) ∂ f (xt, b) ∂ b = 0 (\ displaystyle \ sum _ (t = 1) ^ (n) (y_ (t) -f (x_ (t), b)) (\ frac (\ partial f (x_ (t), b)) (\ partial b)) = 0).OLS for Linear Regression
Let the regression dependence be linear:
yt = ∑ j = 1 kbjxtj + ε = xt T b + ε t (\ displaystyle y_ (t) = \ sum _ (j = 1) ^ (k) b_ (j) x_ (tj) + \ varepsilon = x_ ( t) ^ (T) b + \ varepsilon _ (t)).Let be y is the column vector of observations of the variable being explained, and X (\ displaystyle X)- this is (n × k) (\ displaystyle ((n \ times k)))-matrix of observations of factors (rows of the matrix are vectors of values of factors in a given observation, by columns - a vector of values of a given factor in all observations). The matrix representation of the linear model is:
y = X b + ε (\ displaystyle y = Xb + \ varepsilon).Then the vector of estimates of the explained variable and the vector of regression residuals will be equal
y ^ = X b, e = y - y ^ = y - X b (\ displaystyle (\ hat (y)) = Xb, \ quad e = y - (\ hat (y)) = y-Xb).accordingly, the sum of the squares of the regression residuals will be
R S S = e T e = (y - X b) T (y - X b) (\ displaystyle RSS = e ^ (T) e = (y-Xb) ^ (T) (y-Xb)).Differentiating this function with respect to the parameter vector b (\ displaystyle b) and equating the derivatives to zero, we obtain a system of equations (in matrix form):
(X T X) b = X T y (\ displaystyle (X ^ (T) X) b = X ^ (T) y).In deciphered matrix form, this system of equations looks like this:
(∑ xt 1 2 ∑ xt 1 xt 2 ∑ xt 1 xt 3… ∑ xt 1 xtk ∑ xt 2 xt 1 ∑ xt 2 2 ∑ xt 2 xt 3… ∑ xt 2 xtk ∑ xt 3 xt 1 ∑ xt 3 xt 2 ∑ xt 3 2… ∑ xt 3 xtk ⋮ ⋮ ⋮ ⋱ ⋮ ∑ xtkxt 1 ∑ xtkxt 2 ∑ xtkxt 3… ∑ xtk 2) (b 1 b 2 b 3 ⋮ bk) = (∑ xt 1 yt ∑ xt 2 yt ∑ xt 3 yt ⋮ ∑ xtkyt), (\ displaystyle (\ begin (pmatrix) \ sum x_ (t1) ^ (2) & \ sum x_ (t1) x_ (t2) & \ sum x_ (t1) x_ (t3) & \ ldots & \ sum x_ (t1) x_ (tk) \\\ sum x_ (t2) x_ (t1) & \ sum x_ (t2) ^ (2) & \ sum x_ (t2) x_ (t3) & \ ldots & \ sum x_ (t2) x_ (tk) \\\ sum x_ (t3) x_ (t1) & \ sum x_ (t3) x_ (t2) & \ sum x_ (t3) ^ (2) & \ ldots & \ sum x_ (t3) x_ (tk) \\\ vdots & \ vdots & \ vdots & \ ddots & \ vdots \\\ sum x_ (tk) x_ (t1) & \ sum x_ (tk) x_ (t2) & \ sum x_ (tk) x_ (t3) & \ ldots & \ sum x_ (tk) ^ (2) \\\ end (pmatrix)) (\ begin (pmatrix) b_ (1) \\ b_ (2) \\ b_ (3 ) \\\ vdots \\ b_ (k) \\\ end (pmatrix)) = (\ begin (pmatrix) \ sum x_ (t1) y_ (t) \\\ sum x_ (t2) y_ (t) \\ \ sum x_ (t3) y_ (t) \\\ vdots \\\ sum x_ (tk) y_ (t) \\\ end (pmatrix)),) where all the sums are taken over all admissible values t (\ displaystyle t).
If a constant is included in the model (as usual), then x t 1 = 1 (\ displaystyle x_ (t1) = 1) with all t (\ displaystyle t), therefore, in the upper left corner of the matrix of the system of equations, there is the number of observations n (\ displaystyle n), and in the rest of the elements of the first row and the first column - just the sum of the values of the variables: ∑ x t j (\ displaystyle \ sum x_ (tj)) and the first element of the right side of the system is ∑ y t (\ displaystyle \ sum y_ (t)).
The solution of this system of equations gives the general formula of the OLS estimates for the linear model:
b ^ OLS = (XTX) - 1 XT y = (1 n XTX) - 1 1 n XT y = V x - 1 C xy (\ displaystyle (\ hat (b)) _ (OLS) = (X ^ (T ) X) ^ (- 1) X ^ (T) y = \ left ((\ frac (1) (n)) X ^ (T) X \ right) ^ (- 1) (\ frac (1) (n )) X ^ (T) y = V_ (x) ^ (- 1) C_ (xy)).For analytical purposes, the last representation of this formula turns out to be useful (in the system of equations when divided by n, instead of sums, arithmetic means appear). If in the regression model the data centered, then in this representation the first matrix has the meaning of the sample covariance matrix of factors, and the second is the vector of covariance of factors with the dependent variable. If, in addition, the data is also normalized to SKO (that is, ultimately standardized), then the first matrix has the meaning of a selective correlation matrix of factors, the second vector is a vector of selective correlations of factors with a dependent variable.
An important property of OLS estimates for models with constant- the line of the constructed regression passes through the center of gravity of the sample data, that is, the equality is fulfilled:
y ¯ = b 1 ^ + ∑ j = 2 kb ^ jx ¯ j (\ displaystyle (\ bar (y)) = (\ hat (b_ (1))) + \ sum _ (j = 2) ^ (k) (\ hat (b)) _ (j) (\ bar (x)) _ (j)).In particular, in the extreme case, when the only regressor is a constant, we find that the OLS estimate of the only parameter (the constant itself) is equal to the mean value of the variable being explained. That is, the arithmetic mean, known for its good properties from the laws of large numbers, is also an OLS-estimate - it satisfies the criterion of the minimum sum of squares of deviations from it.
The simplest special cases
In the case of paired linear regression y t = a + b x t + ε t (\ displaystyle y_ (t) = a + bx_ (t) + \ varepsilon _ (t)), when the linear dependence of one variable on another is estimated, the calculation formulas are simplified (you can do without matrix algebra). The system of equations is as follows:
(1 x ¯ x ¯ x 2 ¯) (ab) = (y ¯ xy ¯) (\ displaystyle (\ begin (pmatrix) 1 & (\ bar (x)) \\ (\ bar (x)) & (\ bar (x ^ (2))) \\\ end (pmatrix)) (\ begin (pmatrix) a \\ b \\\ end (pmatrix)) = (\ begin (pmatrix) (\ bar (y)) \\ (\ overline (xy)) \\\ end (pmatrix))).Hence, it is easy to find estimates of the coefficients:
(b ^ = Cov (x, y) Var (x) = xy ¯ - x ¯ y ¯ x 2 ¯ - x ¯ 2, a ^ = y ¯ - bx ¯. (\ displaystyle (\ begin (cases) (\ hat (b)) = (\ frac (\ mathop (\ textrm (Cov)) (x, y)) (\ mathop (\ textrm (Var)) (x))) = (\ frac ((\ overline (xy)) - (\ bar (x)) (\ bar (y))) ((\ overline (x ^ (2))) - (\ overline (x)) ^ (2))), \\ ( \ hat (a)) = (\ bar (y)) - b (\ bar (x)). \ end (cases)))Despite the fact that in the general case the model with a constant is preferable, in some cases it is known from theoretical considerations that the constant a (\ displaystyle a) should be zero. For example, in physics, the relationship between voltage and current has the form U = I ⋅ R (\ displaystyle U = I \ cdot R); measuring the voltage and current strength, it is necessary to estimate the resistance. In this case, we are talking about the model y = b x (\ displaystyle y = bx)... In this case, instead of the system of equations, we have the only equation
(∑ x t 2) b = ∑ x t y t (\ displaystyle \ left (\ sum x_ (t) ^ (2) \ right) b = \ sum x_ (t) y_ (t)).
Consequently, the formula for estimating a single coefficient has the form
B ^ = ∑ t = 1 nxtyt ∑ t = 1 nxt 2 = xy ¯ x 2 ¯ (\ displaystyle (\ hat (b)) = (\ frac (\ sum _ (t = 1) ^ (n) x_ (t ) y_ (t)) (\ sum _ (t = 1) ^ (n) x_ (t) ^ (2))) = (\ frac (\ overline (xy)) (\ overline (x ^ (2)) ))).
Polynomial model case
If the data is fitted with a single variable polynomial regression function f (x) = b 0 + ∑ i = 1 k b i x i (\ displaystyle f (x) = b_ (0) + \ sum \ limits _ (i = 1) ^ (k) b_ (i) x ^ (i)), then, perceiving the degree x i (\ displaystyle x ^ (i)) as independent factors for everyone i (\ displaystyle i) it is possible to estimate the parameters of the model based on the general formula for estimating the parameters of a linear model. To do this, it is sufficient to take into account in the general formula that with such an interpretation x t i x t j = x t i x t j = x t i + j (\ displaystyle x_ (ti) x_ (tj) = x_ (t) ^ (i) x_ (t) ^ (j) = x_ (t) ^ (i + j)) and x t j y t = x t j y t (\ displaystyle x_ (tj) y_ (t) = x_ (t) ^ (j) y_ (t))... Consequently, the matrix equations in this case will take the form:
(n ∑ nxt… ∑ nxtk ∑ nxt ∑ nxt 2… ∑ nxtk + 1 ⋮ ⋮ ⋱ ⋮ ∑ nxtk ∑ nxtk + 1… ∑ nxt 2 k) [b 0 b 1 ⋮ bk] = [∑ nyt ∑ nxtyt ⋮ ∑ nxtkyt ]. (\ displaystyle (\ begin (pmatrix) n & \ sum \ limits _ (n) x_ (t) & \ ldots & \ sum \ limits _ (n) x_ (t) ^ (k) \\\ sum \ limits _ ( n) x_ (t) & \ sum \ limits _ (n) x_ (t) ^ (2) & \ ldots & \ sum \ limits _ (n) x_ (t) ^ (k + 1) \\\ vdots & \ vdots & \ ddots & \ vdots \\\ sum \ limits _ (n) x_ (t) ^ (k) & \ sum \ limits _ (n) x_ (t) ^ (k + 1) & \ ldots & \ sum \ limits _ (n) x_ (t) ^ (2k) \ end (pmatrix)) (\ begin (bmatrix) b_ (0) \\ b_ (1) \\\ vdots \\ b_ (k) \ end ( bmatrix)) = (\ begin (bmatrix) \ sum \ limits _ (n) y_ (t) \\\ sum \ limits _ (n) x_ (t) y_ (t) \\\ vdots \\\ sum \ limits _ (n) x_ (t) ^ (k) y_ (t) \ end (bmatrix)).)
Statistical properties of OLS estimates
First of all, we note that for linear models, OLS estimates are linear estimates, as follows from the above formula. For the unbiasedness of the OLS estimates, it is necessary and sufficient to fulfill the most important condition of regression analysis: the mathematical expectation of a random error, conditional in terms of factors, should be equal to zero. This condition, in particular, is satisfied if
- the mathematical expectation of random errors is zero, and
- factors and random errors are independent random variables.
The second condition - the condition of exogenous factors - is fundamental. If this property is not met, then we can assume that almost any estimates will be extremely unsatisfactory: they will not even be consistent (that is, even a very large amount of data does not allow obtaining qualitative estimates in this case). In the classical case, a stronger assumption is made about the determinism of factors, as opposed to a random error, which automatically means the fulfillment of the exogenous condition. In the general case, for the consistency of the estimates, it is sufficient to satisfy the exogeneity condition together with the convergence of the matrix V x (\ displaystyle V_ (x)) to some non-degenerate matrix with increasing sample size to infinity.
In order for, in addition to consistency and unbiasedness, estimates of (ordinary) least squares to be effective (the best in the class of linear unbiased estimates), it is necessary to fulfill additional properties of a random error:
These assumptions can be formulated for the covariance matrix of the vector of random errors V (ε) = σ 2 I (\ displaystyle V (\ varepsilon) = \ sigma ^ (2) I).
A linear model satisfying these conditions is called classical... OLS estimates for classical linear regression are unbiased, consistent and the most effective estimates in the class of all linear unbiased estimates (in English literature, the abbreviation is sometimes used BLUE (Best Linear Unbiased Estimator) is the best linear unbiased estimate; in the domestic literature, the Gauss - Markov theorem is more often cited). As it is easy to show, the covariance matrix of the vector of coefficient estimates will be equal to:
V (b ^ OLS) = σ 2 (XTX) - 1 (\ displaystyle V ((\ hat (b)) _ (OLS)) = \ sigma ^ (2) (X ^ (T) X) ^ (- 1 )).
Efficiency means that this covariance matrix is "minimal" (any linear combination of coefficients, and in particular the coefficients themselves, have the minimum variance), that is, in the class of linear unbiased estimates, the OLS estimates are the best. The diagonal elements of this matrix - the variances of the coefficient estimates - are important parameters of the quality of the estimates obtained. However, it is impossible to calculate the covariance matrix, since the variance of the random errors is unknown. It can be proved that the unbiased and consistent (for the classical linear model) estimate of the variance of random errors is the value:
S 2 = R S S / (n - k) (\ displaystyle s ^ (2) = RSS / (n-k)).
Substituting this value in the formula for the covariance matrix and we obtain an estimate of the covariance matrix. The estimates obtained are also unbiased and consistent. It is also important that the estimation of the variance of errors (and hence the variances of the coefficients) and the estimates of the model parameters are independent random variables, which allows one to obtain test statistics for testing hypotheses about the coefficients of the model.
It should be noted that if the classical assumptions are not met, the OLS estimates of the parameters are not the most efficient and, where W (\ displaystyle W)- some symmetric positive definite weight matrix. The usual OLS is a special case of this approach, when the weight matrix is proportional to the identity matrix. As is known, for symmetric matrices (or operators) there is a decomposition W = P T P (\ displaystyle W = P ^ (T) P)... Therefore, this functional can be represented as follows e TPTP e = (P e) TP e = e ∗ T e ∗ (\ displaystyle e ^ (T) P ^ (T) Pe = (Pe) ^ (T) Pe = e _ (*) ^ (T) e_ ( *)), that is, this functional can be represented as the sum of the squares of some transformed "residuals". Thus, we can distinguish a class of least squares methods - LS-methods (Least Squares).
It has been proved (Aitken's theorem) that for a generalized linear regression model (in which no restrictions are imposed on the covariance matrix of random errors), the most effective (in the class of linear unbiased estimates) are estimates of the so-called generalized OLS (OLS, GLS - Generalized Least Squares)- LS-method with a weight matrix equal to the inverse covariance matrix of random errors: W = V ε - 1 (\ displaystyle W = V _ (\ varepsilon) ^ (- 1)).
It can be shown that the formula for OLS estimates for the parameters of a linear model has the form
B ^ GLS = (XTV - 1 X) - 1 XTV - 1 y (\ displaystyle (\ hat (b)) _ (GLS) = (X ^ (T) V ^ (- 1) X) ^ (- 1) X ^ (T) V ^ (- 1) y).
The covariance matrix of these estimates will accordingly be equal to
V (b ^ GLS) = (XTV - 1 X) - 1 (\ displaystyle V ((\ hat (b)) _ (GLS)) = (X ^ (T) V ^ (- 1) X) ^ (- 1)).
In fact, the essence of OLS is a certain (linear) transformation (P) of the original data and the application of the usual OLS to the transformed data. The goal of this transformation is that for the transformed data, random errors already satisfy the classical assumptions.
Weighted OLS
In the case of a diagonal weight matrix (and hence a covariance matrix of random errors), we have the so-called Weighted Least Squares (WLS). In this case, the weighted sum of the squares of the residuals of the model is minimized, that is, each observation receives a "weight" inversely proportional to the variance of the random error in this observation: e TW e = ∑ t = 1 net 2 σ t 2 (\ displaystyle e ^ (T) We = \ sum _ (t = 1) ^ (n) (\ frac (e_ (t) ^ (2)) (\ sigma _ (t) ^ (2))))... In fact, the data is transformed by weighting the observations (dividing by a value proportional to the estimated standard deviation of random errors), and regular OLS is applied to the weighted data.
ISBN 978-5-7749-0473-0.
COURSE WORK
by discipline: Informatics
Topic: Least Squares Function Approximation
Introduction
1. Statement of the problem
2. Calculation formulas
Calculation using tables made using Microsoft Excel
Algorithm diagram
Calculation in the MathCad program
Results obtained using the Linear function
Presentation of results in the form of graphs
Introduction
The aim of the course work is to deepen the knowledge of computer science, develop and consolidate the skills of working with the Microsoft Excel spreadsheet processor and the MathCAD software product and their use for solving problems using a computer from the subject area related to research.
Approximation (from the Latin "approximare" - "to approach") - an approximate expression of any mathematical objects (for example, numbers or functions) through other simpler, more convenient to use, or simply better known. In scientific research, approximation is used to describe, analyze, generalize and further use empirical results.
As you know, there can be an exact (functional) relationship between quantities, when one value of the argument corresponds to one definite value, and a less precise (correlation) relationship, when one specific value of the argument corresponds to an approximate value or a set of values of a function that are more or less close. to each other. When conducting scientific research, processing the results of observation or experiment, one usually has to deal with the second option.
When studying the quantitative dependencies of various indicators, the values of which are determined empirically, as a rule, there is some variability. Partly it is set by the heterogeneity of the studied objects of inanimate and, especially, living nature, partly - it is caused by the observation error and quantitative processing of materials. The last component is not always possible to exclude completely, it can only be minimized by careful selection of an adequate research method and accuracy of work. Therefore, when performing any research work, the problem arises of identifying the true nature of the dependence of the studied indicators, this or that degree is masked by the unaccounted for variability: values. For this, an approximation is used - an approximate description of the correlation dependence of variables by a suitable equation of functional dependence, which conveys the main trend of the dependence (or its "trend").
When choosing an approximation, one should proceed from a specific research problem. Usually, the simpler the equation is used for approximation, the more approximate the description of the dependence will be. Therefore, it is important to read how significant and what caused the deviations of specific values from the resulting trend. When describing the dependence of empirically determined values, it is possible to achieve much greater accuracy using some more complex, multi-parametric equation. However, it makes no sense to strive with maximum accuracy to convey random deviations of values in specific series of empirical data. It is much more important to grasp the general pattern, which in this case is most logically and with acceptable accuracy expressed precisely by the two-parameter equation of the power function. Thus, choosing an approximation method, the researcher always makes a compromise: decides to what extent in this case it is advisable and appropriate to “sacrifice” the details and, accordingly, how general the dependence of the compared variables should be expressed. Along with identifying patterns masked by random deviations of empirical data from the general pattern, approximation also allows solving many other important problems: formalizing the found dependence; find unknown values of the dependent variable by interpolation or, if applicable, extrapolation.
In each task, the conditions of the problem, the initial data, the form of issuing the results are formulated, the main mathematical dependences for solving the problem are indicated. In accordance with the method for solving the problem, a solution algorithm is developed, which is presented in graphical form.
1. Statement of the problem
1. Using the least squares method, the function given in the table is approximated:
a) a polynomial of the first degree ![]() ;
;
b) a polynomial of the second degree;
c) exponential dependence.
Calculate the coefficient of determinism for each dependency.
Calculate the correlation coefficient (only in case a).
Draw a trend line for each dependency.
Using the LINEST function, calculate the numerical characteristics of the dependence on.
Compare your calculations with the results obtained using LINEST.
Draw a conclusion which of the obtained formulas best approximates the function.
Write a program in one of the programming languages and compare the counting results with those obtained above.
Option 3. The function is given in table. 1.
Table 1.
2. Calculation formulas Often, when analyzing empirical data, it becomes necessary to find a functional relationship between the values of x and y, which are obtained as a result of experience or measurements. Xi (independent value) is given by the experimenter, and yi, called empirical or experimental values, is obtained as a result of experience. The analytical form of the functional dependence that exists between the values of x and y is usually unknown, therefore, a practically important task arises - to find an empirical formula (where are the parameters), the values of which, if possible, would differ little from the experimental values. According to the least squares method, the best coefficients are those for which the sum of the squares of the deviations of the found empirical function from the given values of the function is minimal. Using the necessary condition for the extremum of a function of several variables - the equality of partial derivatives to zero, find a set of coefficients that provide the minimum of the function defined by formula (2) and obtain a normal system for determining the coefficients Thus, finding the coefficients is reduced to solving system (3). The type of system (3) depends on which class of empirical formulas we are looking for dependence (1). In the case of a linear dependence, system (3) takes the form: In the case of a quadratic dependence, system (3) takes the form: In some cases, as an empirical formula, a function is taken into which the undefined coefficients enter nonlinearly. In this case, sometimes the problem can be linearized, i.e. reduce to linear. These dependences include the exponential dependence where a1 and a2 are undefined coefficients. Linearization is achieved by taking the logarithm of equality (6), after which we obtain the relation Let us denote and, respectively, by and, then dependence (6) can be written in the form, which makes it possible to apply formulas (4) with the replacement of a1 by and by. The graph of the restored functional dependence y (x) according to the measurement results (xi, yi), i = 1,2,…, n is called the regression curve. To check the agreement of the constructed regression curve with the experimental results, the following numerical characteristics are usually introduced: the correlation coefficient (linear dependence), the correlation ratio, and the determinism coefficient. The correlation coefficient is a measure of the linear relationship between dependent random variables: it shows how well, on average, one of the variables can be represented as a linear function of the other. The correlation coefficient is calculated using the formula: where is the arithmetic mean of x, y, respectively. The correlation coefficient between random variables in absolute value does not exceed 1. The closer to 1, the closer the linear relationship between x and y. In the case of a nonlinear correlation, the conditional mean values are located near the curved line. In this case, it is recommended to use the correlation ratio as a characteristic of the bond strength, the interpretation of which does not depend on the type of the studied dependence. The correlation ratio is calculated by the formula: where Is always. Equality = corresponds to random uncorrelated values; = if and only if there is an exact functional relationship between x and y. In the case of a linear dependence of y on x, the correlation ratio coincides with the square of the correlation coefficient. The value is used as an indicator of the deviation of the regression from linearity. The correlation ratio is a measure of the correlation between y c x in any form, but it cannot give an idea of the degree of closeness of empirical data to a special form. To find out how accurately the plotted 5th curve reflects empirical data, one more characteristic is introduced - the coefficient of determinism. The coefficient of determinism is determined by the formula: where Sres = is the residual sum of squares, which characterizes the deviation of the experimental data from the theoretical ones; full is the total sum of squares, where the average value is yi. The smaller the residual sum of squares compared to the total sum of squares, the greater the coefficient of determinism r2, which shows how well the equation obtained using regression analysis explains the relationship between the variables. If it is equal to 1, then there is a complete correlation with the model, i.e. there is no difference between actual and estimated y-values. Otherwise, if the coefficient of determinism is 0, then the regression equation fails to predict y values. The coefficient of determinism does not always exceed the correlation ratio. In the case when equality is satisfied, then we can assume that the constructed empirical formula most accurately reflects the empirical data. 3. Calculation using tables made using Microsoft Excel To carry out calculations, it is advisable to arrange the data in the form of Table 2 using the tools of the Microsoft Excel spreadsheet processor. table 2
Let us explain how table 2 is compiled. Step 1.In cells A1: A25, enter the values xi. Step 2 In cells B1: B25 we enter the values of уi. Step 3 In cell C1, enter the formula = A1 ^ 2. Step 4. In cells C1: C25, this formula is copied. Step 5 In cell D1, enter the formula = A1 * B1. Step 6 This formula is copied into cells D1: D25. Step 7 In cell F1, enter the formula = A1 ^ 4. Step 8 This formula is copied into cells F1: F25. Step 9 In cell G1, enter the formula = A1 ^ 2 * B1. Step 10 This formula is copied into cells G1: G25. Step 11 In cell H1, enter the formula = LN (B1). Step 12.In cells H1: H25 this formula is copied. Step 13 In cell I1, enter the formula = A1 * LN (B1). Step 14.In cells I1: I25, this formula is copied. The next steps are done using the autosum S. Step 15. In cell A26, enter the formula = SUM (A1: A25). Step 16. In cell B26, enter the formula = SUM (B1: B25). Step 17. In cell C26, enter the formula = SUM (C1: C25). Step 18. In cell D26, enter the formula = SUM (D1: D25). Step 19. In cell E26, enter the formula = SUM (E1: E25). Step 20. In cell F26, enter the formula = SUM (F1: F25). Step 21. In cell G26, enter the formula = SUM (G1: G25). Step 22. In cell H26, enter the formula = SUM (H1: H25). Step 23. In cell I26, enter the formula = SUM (I1: I25). Let us approximate the function by a linear function. To determine the coefficients and use system (4). Using the total sums of Table 2 located in cells A26, B26, C26 and D26, we write system (4) in the form having solved which, we get The system was solved by Cramer's method. The essence of which is as follows. Consider a system of n algebraic linear equations with n unknowns: The determinant of the system is the determinant of the matrix of the system: We denote the determinant, which is obtained from the determinant of the system Δ by replacing the j-th column with the column Thus, the linear approximation has the form System (11) is solved using Microsoft Excel tools. The results are shown in Table 3. Table 3
inverse matrix Table 3 in cells A32: B33 contains the formula (= MOBR (A28: B29)). In cells E32: E33 the formula is written (= MULTIPLE (A32: B33), (C28: C29)). Next, we approximate the function by a quadratic function solving which, we get a1 = 10.663624, Thus, the quadratic approximation has the form System (16) is solved using Microsoft Excel tools. The results are shown in Table 4. Table 4
inverse matrix In table 4, in cells A41: C43, the formula is written (= MOBR (A36: C38)). Cells F41: F43 contain the formula (= MULTIPLE (A41: C43), (D36: D38)). Now we approximate the function with an exponential function. To determine the coefficients and we logarithm the values and, using the total sums of Table 2, located in cells A26, C26, H26 and I26, we obtain the system Having solved system (18), we obtain and. After potentiation we get. Thus, the exponential approximation has the form System (18) is solved using Microsoft Excel tools. The results are shown in Table 5. Table 5
inverse matrix In cells A50: B51, the formula is written (= MOBR (A46: B47)). In cells E49: E50, the formula is written (= MULTIPLE (A50: B51), (C46: C47)). Cell E51 contains the formula = EXP (E49). Let's calculate the arithmetic mean using the formulas: The calculation results using Microsoft Excel are presented in Table 6. Table 6
Cell B54 contains the formula = A26 / 25. Cell B55 contains the formula = B26 / 25 Table 7
Step 1 In cell J1, enter the formula = (A1- $ B $ 54) * (B1- $ B $ 55). Step 2 This formula is copied into cells J2: J25. Step 3 In cell K1, enter the formula = (A1- $ B $ 54) ^ 2. Step 4 This formula is copied into cells k2: K25. Step 5 In cell L1, enter the formula = (B1- $ B $ 55) ^ 2. Step 6 This formula is copied into cells L2: L25. Step 7 In cell M1, enter the formula = ($ E $ 32 + $ E $ 33 * A1-B1) ^ 2. Step 8 This formula is copied into cells M2: M25. Step 9 In cell N1, enter the formula = ($ F $ 41 + $ F $ 42 * A1 + $ F $ 43 * A1 ^ 2-B1) ^ 2. Step 10.In cells N2: N25, this formula is copied. Step 11 In cell O1, enter the formula = ($ E $ 51 * EXP ($ E $ 50 * A1) -B1) ^ 2. Step 12 This formula is copied to cells O2: O25. The next steps are done with the auto-summing S. Step 13 In cell J26, enter the formula = SUMM (J1: J25). Step 14 In cell K26, enter the formula = SUMM (K1: K25). Step 15 In cell L26, enter the formula = SUMM (L1: L25). Step 16 In cell M26, enter the formula = SUMM (M1: M25). Step 17 In cell N26, enter the formula = SUMM (N1: N25). Step 18 In cell O26, enter the formula = SUMM (O1: O25). Now let us calculate the correlation coefficient using formula (8) (only for linear approximation) and the coefficient of determinism using formula (10). The results of calculations using Microsoft Excel are presented in Table 8. Table 8
Correlation coefficient Determinism coefficient (linear approximation) Determinism coefficient (quadratic approximation) Determinism coefficient (exponential approximation) Cell E57 contains the formula = J26 / (K26 * L26) ^ (1/2). Cell E59 contains the formula = 1-M26 / L26. Cell E61 contains the formula = 1-N26 / L26. Cell E63 contains the formula = 1-O26 / L26. Analysis of the calculation results shows that the quadratic approximation best describes the experimental data. Algorithm diagram Rice. 1. Scheme of the algorithm for the calculation program. 5. Calculation in the MathCad program Linear regression · Line (x, y) - a vector of two elements (b, a) of linear regression coefficients b + ax; · X - vector of valid data of the argument; · Y is a vector of valid data values of the same size. Figure 2. Polynomial regression means approximating the data (x1, y1) by a polynomial of the kth degree.With k = i, the polynomial is a straight line, with k = 2 - a parabola, with k = 3 - a cubic parabola, etc. As a rule, in practice, k<5. Regress (x, y, k) - vector of coefficients for constructing polynomial data regression; Interp (s, x, y, t) - the result of polynomial regression; S = regress (x, y, k); · X - vector of valid data of the argument, the elements of which are arranged in ascending order; · Y is a vector of valid data values of the same size; · K - degree of the regression polynomial (positive integer); · T - the value of the argument of the regression polynomial. Figure 3 In addition to those considered, several more types of three-parameter regression are built into Mathcad, their implementation is somewhat different from the above regression options in that, in addition to the data array, it is required to set some initial values of the coefficients a, b, c for them. Use the appropriate type of regression if you have a good idea of what kind of dependency describes your data set. When the type of regression does not reflect the sequence of data well, then its result is often unsatisfactory and even very different depending on the choice of initial values. Each of the functions produces a vector of specified parameters a, b, c. Results from LINEST Let's look at the purpose of the LINEST function. This function uses the least squares method to calculate the straight line that best fits the available data. The function returns an array that describes the resulting line. The equation for a straight line is as follows: M1x1 + m2x2 + ... + b or y = mx + b, tabular microsoft software algorithm where the dependent y-value is a function of the independent x-value. The m values are the coefficients corresponding to each independent variable x, and b is a constant. Note that y, x and m can be vectors. To get the results, you need to create a tabular formula that will occupy 5 rows and 2 columns. This interval can be located anywhere on the worksheet. The LINEST function is required at this interval. As a result, all cells of the A65: B69 interval should be filled (as shown in Table 9). Table 9.
Let us explain the purpose of some of the values in Table 9. The values located in cells A65 and B65 characterize the slope and shift, respectively. - the coefficient of determinism. - F - the observed value. - the number of degrees of freedom. - the regression sum of squares. - the residual sum of squares. Presentation of results in the form of graphs Rice. 4. Graph of linear approximation Rice. 5. Plot of quadratic approximation Rice. 6. Graph of exponential approximation conclusions Let's draw conclusions based on the results of the data obtained. Analysis of the calculation results shows that the quadratic approximation best describes the experimental data, since the trend line for it most accurately reflects the behavior of the function in this area. Comparing the results obtained using the LINEST function, we see that they completely coincide with the calculations carried out above. This indicates that the calculations are correct. The results obtained using the MathCad program completely coincide with the values given above. This indicates the correctness of the calculations. Bibliography 1 B.P. Demidovich, I.A. Maroon. Foundations of Computational Mathematics. M: State publishing house of physical and mathematical literature. 2 Informatics: Textbook ed. prof. N.V. Makarova. M: Finance and Statistics, 2007. 3 Informatics: Workshop on the technology of working on a computer, ed. prof. N.V. Makarova. M: Finance and Statistics, 2010. 4 V.B. Komyagin. Excel programming in Visual Basic. M: Radio and communication, 2007. 5 N. Nicole, R. Albrecht. Excel. Spreadsheets. M: Ed. ECOM, 2008. 6 Methodological instructions for the implementation of course work in computer science (for correspondence students of all specialties), ed. Zhurova G.N., SPbGGI (TU), 2011.
![]() , (1)
, (1)
![]() :
:![]() (3)
(3)
 (4)
(4)
 (5)
(5)
![]() (7)
(7)
 (8)
(8) (9)
(9) (10)
(10)
![]() and the numerator characterizes the dispersion of the conditional averages around the unconditional average.
and the numerator characterizes the dispersion of the conditional averages around the unconditional average.![]() - regression sum of squares, which characterizes the scatter of the data.
- regression sum of squares, which characterizes the scatter of the data.
 (11)
(11)
![]() and .
and . (12)
(12)
 (13)
(13)
![]() ... To determine the coefficients a1, a2, and a3, we use system (5). Using the total sums of Table 2, located in cells A26, B26, C26, D26, E26, F26, G26, we write system (5) in the form
... To determine the coefficients a1, a2, and a3, we use system (5). Using the total sums of Table 2, located in cells A26, B26, C26, D26, E26, F26, G26, we write system (5) in the form  (16)
(16)
![]() and
and ![]()
 (18)
(18)








The least squares method is one of the most widespread and most developed due to its simplicity and efficiency of methods for estimating the parameters of linear... At the same time, certain caution should be exercised when using it, since the models built with its use may not satisfy a number of requirements for the quality of their parameters and, as a result, it is not “good enough” to display the patterns of the process development.
Let us consider the procedure for estimating the parameters of a linear econometric model using the least squares method in more detail. Such a model in general form can be represented by equation (1.2):
y t = a 0 + a 1 х 1 t + ... + a n х nt + ε t.
The initial data when estimating the parameters a 0, a 1, ..., a n is the vector of values of the dependent variable y= (y 1, y 2, ..., y T) "and the matrix of values of independent variables

in which the first column of ones corresponds to the coefficient of the model.
The method of least squares got its name, proceeding from the basic principle, which the parameter estimates obtained on its basis must satisfy: the sum of the squares of the model error should be minimal.
Examples of solving problems using the least squares method
Example 2.1. The trading enterprise has a network of 12 stores, information on the activities of which is presented in table. 2.1.
The management of the company would like to know how the size of the annual depends on the retail space of the store.
Table 2.1
|
Store number |
Annual turnover, RUB mln |
Trade area, thousand m 2 |
Least squares solution. Let's designate - the annual turnover of the th store, mln rubles; - sales area of the th store, thousand m 2.

Figure 2.1. Scatter plot for example 2.1
To determine the form of the functional relationship between the variables and build a scatter diagram (Fig. 2.1).
Based on the scatter diagram, it can be concluded that the annual turnover is positively dependent on the retail space (i.e., y will grow with growth). The most appropriate form of functional communication is linear.
Information for further calculations is presented in table. 2.2. Using the least squares method, we estimate the parameters of a linear one-factor econometric model

Table 2.2
Thus,
Consequently, with an increase in the sales area by 1 thousand m 2, all other things being equal, the average annual turnover increases by 67.8871 million rubles.
Example 2.2. The company's management noticed that the annual turnover depends not only on the retail space of the store (see example 2.1), but also on the average number of visitors. The relevant information is presented in table. 2.3.
Table 2.3
Solution. Let's designate - the average number of visitors to the th store per day, thousand people.
To determine the form of the functional relationship between the variables and build a scatter diagram (Fig. 2.2).
Based on the scatterplot, it can be concluded that the annual turnover is positively dependent on the average number of visitors per day (i.e., y will grow with growth). The form of functional dependence is linear.

Rice. 2.2. Scatterplot for Example 2.2
Table 2.4
In general, it is necessary to determine the parameters of the two-factor econometric model
у t = a 0 + a 1 х 1 t + a 2 х 2 t + ε t
The information required for further calculations is presented in table. 2.4.
Let us estimate the parameters of a linear two-factor econometric model using the least squares method.

Thus,
The estimate of the coefficient = 61.6583 shows that, all other things being equal, with an increase in the selling area by 1 thousand m 2, the annual turnover will increase by an average of 61.6583 million rubles.
(see figure). It is required to find the equation of the line
The smaller the number in absolute value, the better the straight line (2) is selected. As a characteristic of the accuracy of the selection of straight line (2), we can take the sum of squares
The minimum conditions for S will be
 |
(6) |
 |
(7) |
Equations (6) and (7) can be written as follows:
 |
(8) |
 |
(9) |
From equations (8) and (9) it is easy to find a and b from the experimental values x i and y i. Line (2), defined by equations (8) and (9), is called the line obtained by the method of least squares (this name emphasizes the fact that the sum of squares S has a minimum). Equations (8) and (9), from which the straight line (2) is determined, are called normal equations.
You can indicate a simple and general way of writing normal equations. Using the experimental points (1) and equation (2), we can write the system of equations for a and b
| y 1 = ax 1 + b, | |||
| y 2 = ax 2 + b, ... |
(10) | ||
| y n = ax n + b, | |||
We multiply the left and right sides of each of these equations by the coefficient of the first unknown a (i.e., by x 1, x 2, ..., x n) and add the resulting equations, the result is the first normal equation (8).
We multiply the left and right sides of each of these equations by the coefficient of the second unknown b, i.e. by 1, and add the resulting equations, the result is the second normal equation (9).
This method of obtaining normal equations is general: it is suitable, for example, for the function
there is a constant value and it must be determined from experimental data (1).
The system of equations for k can be written:
Find line (2) using the least squares method.
Solution. We find:
x i = 21, y i = 46.3, x i 2 = 91, x i y i = 179.1.
We write down equations (8) and (9)
From here we find
Estimating the accuracy of the least squares method
Let us give an estimate of the accuracy of the method for the linear case when equation (2) holds.
Let the experimental values x i be exact, and the experimental values y i have random errors with the same variance for all i.
Let us introduce the notation
| (16) |
Then the solutions of equations (8) and (9) can be represented in the form
| (17) | |
| (18) | |
| where | |
| (19) | |
| From equation (17) we find | |
| (20) | |
| Similarly, from Eq. (18), we obtain | |
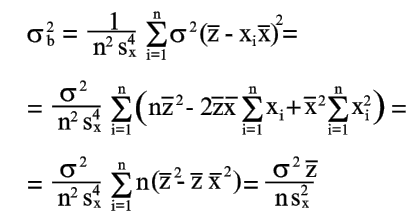 |
(21) |
| because | |
| (22) | |
| From equations (21) and (22) we find | |
 |
(23) |
Equations (20) and (23) give an estimate of the accuracy of the coefficients determined by equations (8) and (9).
Note that the coefficients a and b are correlated. We find their correlation moment by simple transformations.
From here we find
0.072 for x = 1 and 6,
0.041 at x = 3.5.
Literature
Shore. Ya. B. Statistical methods of analysis and quality control and reliability. M.: Gosenergoizdat, 1962, p. 552, S. 92-98.
This book is intended for a wide range of engineers (research institutes, design bureaus, test sites and factories) involved in determining the quality and reliability of electronic equipment and other mass industrial products (mechanical engineering, instrument making, artillery, etc.).
The book provides an application of the methods of mathematical statistics to the processing and evaluation of test results, which determine the quality and reliability of the tested products. For the convenience of the readers, the necessary information from mathematical statistics is provided, as well as a large number of auxiliary mathematical tables that facilitate the necessary calculations.
The presentation is illustrated by a large number of examples taken from the field of radio electronics and artillery technology.
Least square method
In the final lesson of the topic, we will get acquainted with the most famous application FNP, which finds the widest application in various fields of science and practice. It can be physics, chemistry, biology, economics, sociology, psychology, and so on, and so on. By the will of fate, I often have to deal with the economy, and therefore today I will issue you a ticket to an amazing country called Econometrics=) ... How do you not want it ?! It's very good there - you just need to make up your mind! ... But what you probably definitely want is to learn how to solve problems least squares method... And especially diligent readers will learn how to solve them not only faultlessly, but also VERY FAST ;-) But first general problem statement+ related example:
Let in some subject area the indicators are investigated that have a quantitative expression. At the same time, there is every reason to believe that the indicator depends on the indicator. This assumption can be both a scientific hypothesis and based on elementary common sense. Leaving science aside, however, and exploring more mouth-watering areas - namely grocery stores. Let us denote by:
- retail space of a grocery store, sq.m.,
- annual turnover of the grocery store, mln. Rub.
It is absolutely clear that the larger the area of the store, the more its turnover will be in most cases.
Suppose that after observing / experimenting / calculating / dancing with a tambourine, we have numerical data at our disposal: 
With grocery stores, I think everything is clear: - this is the area of the 1st store, - its annual turnover, - the area of the 2nd store, - its annual turnover, etc. By the way, it is not at all necessary to have access to classified materials - a fairly accurate estimate of the turnover can be obtained by means of mathematical statistics... However, let's not be distracted, the course of commercial espionage - it is already paid =)
Tabular data can also be written in the form of dots and depicted in the usual for us Cartesian system .
Let's answer an important question: how many points do you need for a qualitative study?
The bigger, the better. The minimum allowable set consists of 5-6 points. In addition, with a small amount of data, the sample cannot include “anomalous” results. So, for example, a small elite store can help out by orders of magnitude more "its colleagues", thereby distorting the general pattern that needs to be found!
To put it quite simply - we need to choose a function, schedule which passes as close as possible to the points ![]() ... This function is called approximating
(approximation - approximation) or theoretical function
... Generally speaking, there immediately appears an obvious "challenger" - a high degree polynomial whose graph passes through ALL points. But this option is difficult, and often simply incorrect. (since the chart will be “twisting” all the time and reflecting poorly the main trend).
... This function is called approximating
(approximation - approximation) or theoretical function
... Generally speaking, there immediately appears an obvious "challenger" - a high degree polynomial whose graph passes through ALL points. But this option is difficult, and often simply incorrect. (since the chart will be “twisting” all the time and reflecting poorly the main trend).
Thus, the sought function should be simple enough and at the same time reflect the dependence adequately. As you might guess, one of the methods for finding such functions is called least squares method... First, let's take a look at its essence in general terms. Let some function approximate the experimental data: 
How to evaluate the accuracy of this approximation? Let us calculate the differences (deviations) between the experimental and functional values (studying the drawing)... The first thought that comes to mind is to estimate how large the sum is, but the problem is that the differences can be negative. (for example, ![]() )
and deviations as a result of such summation will cancel each other out. Therefore, as an estimate of the accuracy of the approximation, it begs to accept the sum modules deviations:
)
and deviations as a result of such summation will cancel each other out. Therefore, as an estimate of the accuracy of the approximation, it begs to accept the sum modules deviations:
![]() or collapsed: (suddenly, who does not know:
Is the sum icon, and
- auxiliary variable - "counter", which takes values from 1 to
)
.
or collapsed: (suddenly, who does not know:
Is the sum icon, and
- auxiliary variable - "counter", which takes values from 1 to
)
.
Approaching the experimental points with different functions, we will get different values, and it is obvious where this sum is less - that function is more accurate.
Such a method exists and it is called least modulus method... However, in practice, it has become much more widespread. least square method, in which possible negative values are eliminated not by the modulus, but by squaring the deviations:
![]() , after which efforts are directed to the selection of such a function so that the sum of the squares of the deviations
, after which efforts are directed to the selection of such a function so that the sum of the squares of the deviations ![]() was as small as possible. Actually, hence the name of the method.
was as small as possible. Actually, hence the name of the method.
And now we return to another important point: as noted above, the selected function should be quite simple - but there are also a lot of such functions: linear , hyperbolic , exponential , logarithmic , quadratic etc. And, of course, here I would immediately like to "reduce the field of activity." Which class of functions to choose for research? A primitive but effective trick:
- The easiest way to draw points ![]() on the drawing and analyze their location. If they tend to be in a straight line, then you should look for equation of a straight line
on the drawing and analyze their location. If they tend to be in a straight line, then you should look for equation of a straight line ![]() with optimal values and. In other words, the task is to find SUCH coefficients - so that the sum of the squares of the deviations is the smallest.
with optimal values and. In other words, the task is to find SUCH coefficients - so that the sum of the squares of the deviations is the smallest.
If the points are located, for example, along hyperbole, then it is a priori clear that a linear function will give a bad approximation. In this case, we are looking for the most "favorable" coefficients for the hyperbola equation ![]() - those that give the minimum sum of squares
- those that give the minimum sum of squares  .
.
Now note that in both cases we are talking about functions of two variables whose arguments are parameters of wanted dependencies:
And in essence, we need to solve a standard problem - to find minimum function of two variables.
Let's remember our example: suppose that the "store" points tend to be located in a straight line and there is every reason to believe that linear relationship turnover from the retail space. Let's find SUCH coefficients "a" and "bs" so that the sum of the squares of the deviations ![]() was the smallest. Everything is as usual - first 1st order partial derivatives... According to linearity rule you can differentiate directly under the amount icon:
was the smallest. Everything is as usual - first 1st order partial derivatives... According to linearity rule you can differentiate directly under the amount icon: 
If you want to use this information for an essay or course book, I will be very grateful for the link in the list of sources, you will find such detailed calculations in few places: 
Let's compose a standard system: 
We reduce each equation by "two" and, in addition, "break up" the sums: 
Note
: Analyze on your own why “a” and “bie” can be taken out for the sum icon. By the way, formally this can be done with the sum ![]()
Let's rewrite the system in an "applied" form: 
after which the algorithm for solving our problem begins to be drawn:
Do we know the coordinates of the points? We know. Amounts ![]() can we find? Easily. We compose the simplest system of two linear equations in two unknowns("A" and "bh"). We solve the system, for example, Cramer's method, as a result of which we obtain a stationary point. Checking sufficient condition for extremum, one can make sure that at this point the function
can we find? Easily. We compose the simplest system of two linear equations in two unknowns("A" and "bh"). We solve the system, for example, Cramer's method, as a result of which we obtain a stationary point. Checking sufficient condition for extremum, one can make sure that at this point the function ![]() achieves exactly minimum... Verification is associated with additional calculations and therefore we will leave it behind the scenes. (if necessary, the missing frame can be viewedhere
)
... We draw the final conclusion:
achieves exactly minimum... Verification is associated with additional calculations and therefore we will leave it behind the scenes. (if necessary, the missing frame can be viewedhere
)
... We draw the final conclusion:
Function ![]() the best way (at least compared to any other linear function) brings experimental points closer
the best way (at least compared to any other linear function) brings experimental points closer ![]() ... Roughly speaking, its graph runs as close as possible to these points. In tradition econometrics the resulting approximating function is also called paired linear regression equation
.
... Roughly speaking, its graph runs as close as possible to these points. In tradition econometrics the resulting approximating function is also called paired linear regression equation
.
The problem under consideration is of great practical importance. In the situation with our example, the equation ![]() allows you to predict what turnover ("Game") will be at the store with one or another value of the retail space (this or that value "x")... Yes, the forecast obtained will be only a forecast, but in many cases it will be quite accurate.
allows you to predict what turnover ("Game") will be at the store with one or another value of the retail space (this or that value "x")... Yes, the forecast obtained will be only a forecast, but in many cases it will be quite accurate.
I will analyze just one problem with "real" numbers, since there are no difficulties in it - all calculations are at the level of the 7-8 grade school curriculum. In 95 percent of cases, you will be asked to find just a linear function, but at the very end of the article I will show that it is no more difficult to find the equations of the optimal hyperbola, exponent and some other functions.
In fact, it remains to hand out the promised buns - so that you learn how to solve such examples not only accurately, but also quickly. We carefully study the standard:
Task
As a result of studying the relationship between the two indicators, the following pairs of numbers were obtained: 
Using the least squares method, find the linear function that best approximates the empirical (experienced) data. Make a drawing on which, in a Cartesian rectangular coordinate system, plot experimental points and a graph of the approximating function ![]() ... Find the sum of the squares of the deviations between empirical and theoretical values. Figure out if the function would be better (from the point of view of the method of least squares) zoom in on experimental points.
... Find the sum of the squares of the deviations between empirical and theoretical values. Figure out if the function would be better (from the point of view of the method of least squares) zoom in on experimental points.
Note that the “x” meanings are natural, and this has a characteristic meaningful meaning, which I will talk about a little later; but they, of course, can be fractional. In addition, depending on the content of a particular problem, both "x" and "game" values can be fully or partially negative. Well, we have a “faceless” task, and we start it solution:
We find the coefficients of the optimal function as a solution to the system: 
For the sake of a more compact notation, the "counter" variable can be omitted, since it is already clear that the summation is carried out from 1 to.
It is more convenient to calculate the required amounts in a tabular form: 
Calculations can be carried out on a microcalculator, but it is much better to use Excel - both faster and without errors; watch a short video:
Thus, we obtain the following the system:![]()
Here you can multiply the second equation by 3 and subtract the 2nd from the 1st equation term-by-term... But this is luck - in practice, systems are often not a gift, and in such cases it saves Cramer's method:
, which means that the system has a unique solution.

Let's check. I understand that I don’t want to, but why skip errors where they can be completely avoided? We substitute the found solution into the left side of each equation of the system:
The right-hand sides of the corresponding equations are obtained, which means that the system is solved correctly.
Thus, the required approximating function: - from of all linear functions it is she who approximates the experimental data in the best way.
Unlike straight
dependence of the turnover of the store on its area, the dependence found is reverse
(the principle "the more - the less"), and this fact is immediately revealed by the negative slope... Function ![]() informs us that with an increase in a certain indicator by 1 unit, the value of the dependent indicator decreases average by 0.65 units. As the saying goes, the higher the price of buckwheat, the less it is sold.
informs us that with an increase in a certain indicator by 1 unit, the value of the dependent indicator decreases average by 0.65 units. As the saying goes, the higher the price of buckwheat, the less it is sold.
To plot the graph of the approximating function, we find two of its values:
and execute the drawing: 
The constructed line is called trend line
(namely, a linear trend line, i.e., in the general case, a trend is not necessarily a straight line)... Everyone is familiar with the expression "be in trend", and I think that this term does not need additional comments.
Let's calculate the sum of the squares of the deviations ![]() between empirical and theoretical values. Geometrically, it is the sum of the squares of the lengths of the "crimson" segments (two of which are so small that you can't even see them).
between empirical and theoretical values. Geometrically, it is the sum of the squares of the lengths of the "crimson" segments (two of which are so small that you can't even see them).
Let's summarize the calculations in a table: 
They can again be done manually, just in case I will give an example for the 1st point: ![]()
but it is much more efficient to act in a well-known way:
Let's repeat: what is the meaning of the obtained result? From of all linear functions function ![]() the indicator is the smallest, that is, in its family it is the best approximation. And here, by the way, the final question of the problem is not accidental: what if the proposed exponential function
the indicator is the smallest, that is, in its family it is the best approximation. And here, by the way, the final question of the problem is not accidental: what if the proposed exponential function ![]() will it be better to approximate the experimental points?
will it be better to approximate the experimental points?
Let's find the corresponding sum of squares of deviations - in order to distinguish, I will designate them with the letter "epsilon". The technique is exactly the same: 
And again, just for every fireman, calculations for the 1st point: 
In Excel, we use the standard function EXP (see the Excel Help for the syntax).
Output:, which means that the exponential function approximates the experimental points worse than the straight line ![]() .
.
But here it should be noted that "worse" is does not mean yet, what is wrong. Now I have plotted this exponential function - and it also goes close to the points ![]() - so much so that without analytical research it is difficult to say which function is more accurate.
- so much so that without analytical research it is difficult to say which function is more accurate.
This completes the solution, and I return to the question of the natural values of the argument. In various studies, as a rule, economic or sociological, natural “x” numbers months, years or other equal time intervals. Consider, for example, a problem like this:
We have the following data on retail turnover of the store for the first half of the year:
Using analytical straight line alignment, determine the turnover for July.
Yes, no problem: we number the months 1, 2, 3, 4, 5, 6 and use the usual algorithm, as a result of which we get an equation - the only thing when it comes to time is usually the letter "te" (although this is not critical)... The resulting equation shows that in the first half of the year, trade increased by an average of 27.74 units. per month. Get the forecast for July (month no. 7): d.e.
And such tasks - darkness is dark. Those who wish can use an additional service, namely my Excel calculator (demo version), which the solves the analyzed problem almost instantly! The working version of the program is available in exchange or for token.
At the end of the lesson, brief information on finding dependencies of some other types. Actually, there is nothing special to tell, since the principled approach and the solution algorithm remain the same.
Let's assume that the arrangement of the experimental points resembles a hyperbola. Then, in order to find the coefficients of the best hyperbola, you need to find the minimum of the function - those who wish can carry out detailed calculations and come to a similar system: 
From a formal and technical point of view, it is obtained from a "linear" system  (let's designate it with an "asterisk") replacing "x" with. Well, and the amounts are
(let's designate it with an "asterisk") replacing "x" with. Well, and the amounts are ![]() calculate, and then to the optimal coefficients "a" and "be" a stone's throw.
calculate, and then to the optimal coefficients "a" and "be" a stone's throw.
If there is every reason to believe that the points ![]() are located along a logarithmic curve, then to search for optimal values and find the minimum of the function
are located along a logarithmic curve, then to search for optimal values and find the minimum of the function ![]() ... Formally, in the system (*) must be replaced by:
... Formally, in the system (*) must be replaced by: 
When doing calculations in Excel, use the function LN... I admit, it will not be difficult for me to create calculators for each of the cases under consideration, but it will still be better if you "program" the calculations yourself. Lesson videos to help.
With exponential dependence, the situation is a little more complicated. To reduce the matter to the linear case, let us logarithm the function and use properties of the logarithm:
Now, comparing the resulting function with a linear function, we come to the conclusion that in the system (*) must be replaced by, and - by. For convenience we denote: 
Please note that the system is resolved relative to and, and therefore, after finding the roots, you must remember to find the coefficient itself.
To bring the experimental points closer ![]() optimal parabola
optimal parabola ![]() , should be found minimum function of three variables
, should be found minimum function of three variables ![]() ... After completing the standard actions, we get the following "working" the system:
... After completing the standard actions, we get the following "working" the system:
Yes, of course, there are more sums here, but when using your favorite application, there are no difficulties at all. And finally, I'll tell you how to quickly check and build the desired trend line using Excel: create a scatter chart, select any of the points with the mouse ![]() and through the right click select the option "Add a trend line"... Next, select the type of chart and on the tab "Options" activate the option Show Equation In Chart... OK
and through the right click select the option "Add a trend line"... Next, select the type of chart and on the tab "Options" activate the option Show Equation In Chart... OK
As always, I would like to end the article with some beautiful phrase, and I almost typed “Be in trend!”. But he changed his mind in time. And not because it is stereotyped. I don’t know how anyone, but I don’t want to follow the promoted American and especially the European trend =) Therefore, I wish each of you to adhere to your own line!
http://www.grandars.ru/student/vysshaya-matematika/metod-naimenshih-kvadratov.html
The least squares method is one of the most widespread and most developed due to its simplicity and efficiency of methods for estimating parameters of linear econometric models... At the same time, certain caution should be exercised when using it, since the models built with its use may not satisfy a number of requirements for the quality of their parameters and, as a result, it is not “good enough” to display the patterns of the process development.
Let us consider the procedure for estimating the parameters of a linear econometric model using the least squares method in more detail. Such a model in general form can be represented by equation (1.2):
y t = a 0 + a 1 х 1t + ... + a n х nt + ε t.
The initial data when estimating the parameters a 0, a 1, ..., a n is the vector of values of the dependent variable y= (y 1, y 2, ..., y T) "and the matrix of values of independent variables

in which the first column of ones corresponds to the coefficient of the model.
The method of least squares got its name, proceeding from the basic principle, which the parameter estimates obtained on its basis must satisfy: the sum of the squares of the model error should be minimal.
Examples of solving problems using the least squares method
Example 2.1. The trading enterprise has a network of 12 stores, information on the activities of which is presented in table. 2.1.
The company's management would like to know how the size of the annual turnover depends on the retail space of the store.
Table 2.1
| Store number | Annual turnover, RUB mln | Trade area, thousand m 2 |
| 19,76 | 0,24 | |
| 38,09 | 0,31 | |
| 40,95 | 0,55 | |
| 41,08 | 0,48 | |
| 56,29 | 0,78 | |
| 68,51 | 0,98 | |
| 75,01 | 0,94 | |
| 89,05 | 1,21 | |
| 91,13 | 1,29 | |
| 91,26 | 1,12 | |
| 99,84 | 1,29 | |
| 108,55 | 1,49 |
Least squares solution. Let's designate - the annual turnover of the th store, mln rubles; - sales area of the th store, thousand m 2.

Figure 2.1. Scatter plot for example 2.1
To determine the form of the functional relationship between the variables and build a scatter diagram (Fig. 2.1).
Based on the scatter diagram, it can be concluded that the annual turnover is positively dependent on the retail space (i.e., y will grow with growth). The most appropriate form of functional communication is linear.
Information for further calculations is presented in table. 2.2. Using the least squares method, we estimate the parameters of a linear one-factor econometric model

Table 2.2
| t | y t | x 1t | y t 2 | x 1t 2 | x 1t y t |
| 19,76 | 0,24 | 390,4576 | 0,0576 | 4,7424 | |
| 38,09 | 0,31 | 1450,8481 | 0,0961 | 11,8079 | |
| 40,95 | 0,55 | 1676,9025 | 0,3025 | 22,5225 | |
| 41,08 | 0,48 | 1687,5664 | 0,2304 | 19,7184 | |
| 56,29 | 0,78 | 3168,5641 | 0,6084 | 43,9062 | |
| 68,51 | 0,98 | 4693,6201 | 0,9604 | 67,1398 | |
| 75,01 | 0,94 | 5626,5001 | 0,8836 | 70,5094 | |
| 89,05 | 1,21 | 7929,9025 | 1,4641 | 107,7505 | |
| 91,13 | 1,29 | 8304,6769 | 1,6641 | 117,5577 | |
| 91,26 | 1,12 | 8328,3876 | 1,2544 | 102,2112 | |
| 99,84 | 1,29 | 9968,0256 | 1,6641 | 128,7936 | |
| 108,55 | 1,49 | 11783,1025 | 2,2201 | 161,7395 | |
| S | 819,52 | 10,68 | 65008,554 | 11,4058 | 858,3991 |
| The average | 68,29 | 0,89 |
Thus,
Consequently, with an increase in the sales area by 1 thousand m 2, all other things being equal, the average annual turnover increases by 67.8871 million rubles.
Example 2.2. The company's management noticed that the annual turnover depends not only on the retail space of the store (see example 2.1), but also on the average number of visitors. The relevant information is presented in table. 2.3.
Table 2.3
Solution. Let's designate - the average number of visitors to the th store per day, thousand people.
To determine the form of the functional relationship between the variables and build a scatter diagram (Fig. 2.2).
Based on the scatterplot, it can be concluded that the annual turnover is positively dependent on the average number of visitors per day (i.e., y will grow with growth). The form of functional dependence is linear.

Rice. 2.2. Scatterplot for Example 2.2
Table 2.4
| t | x 2t | x 2t 2 | y t x 2t | x 1t x 2t |
| 8,25 | 68,0625 | 163,02 | 1,98 | |
| 10,24 | 104,8575 | 390,0416 | 3,1744 | |
| 9,31 | 86,6761 | 381,2445 | 5,1205 | |
| 11,01 | 121,2201 | 452,2908 | 5,2848 | |
| 8,54 | 72,9316 | 480,7166 | 6,6612 | |
| 7,51 | 56,4001 | 514,5101 | 7,3598 | |
| 12,36 | 152,7696 | 927,1236 | 11,6184 | |
| 10,81 | 116,8561 | 962,6305 | 13,0801 | |
| 9,89 | 97,8121 | 901,2757 | 12,7581 | |
| 13,72 | 188,2384 | 1252,0872 | 15,3664 | |
| 12,27 | 150,5529 | 1225,0368 | 15,8283 | |
| 13,92 | 193,7664 | 1511,016 | 20,7408 | |
| S | 127,83 | 1410,44 | 9160,9934 | 118,9728 |
| Average | 10,65 |
In general, it is necessary to determine the parameters of the two-factor econometric model
у t = a 0 + a 1 х 1t + a 2 х 2t + ε t
The information required for further calculations is presented in table. 2.4.
Let us estimate the parameters of a linear two-factor econometric model using the least squares method.

Thus,
The estimate of the coefficient = 61.6583 shows that, all other things being equal, with an increase in the selling area by 1 thousand m 2, the annual turnover will increase by an average of 61.6583 million rubles.
The estimate of the coefficient = 2.2748 shows that, all other things being equal, with an increase in the average number of visitors per 1,000 people. per day, the annual turnover will increase by an average of 2.2748 million rubles.
Example 2.3. Using the information presented in table. 2.2 and 2.4, estimate the parameter of the univariate econometric model
![]()
where is the centered value of the annual turnover of the th store, million rubles; - the centered value of the average daily number of visitors to the t-th store, thousand people. (see examples 2.1-2.2).
Solution. Additional information required for calculations is presented in table. 2.5.
Table 2.5
| -48,53 | -2,40 | 5,7720 | 116,6013 | |
| -30,20 | -0,41 | 0,1702 | 12,4589 | |
| -27,34 | -1,34 | 1,8023 | 36,7084 | |
| -27,21 | 0,36 | 0,1278 | -9,7288 | |
| -12,00 | -2,11 | 4,4627 | 25,3570 | |
| 0,22 | -3,14 | 9,8753 | -0,6809 | |
| 6,72 | 1,71 | 2,9156 | 11,4687 | |
| 20,76 | 0,16 | 0,0348 | 3,2992 | |
| 22,84 | -0,76 | 0,5814 | -17,413 | |
| 22,97 | 3,07 | 9,4096 | 70,4503 | |
| 31,55 | 1,62 | 2,6163 | 51,0267 | |
| 40,26 | 3,27 | 10,6766 | 131,5387 | |
| Amount | 48,4344 | 431,0566 |
Using formula (2.35), we obtain

Thus,
![]()
http://www.cleverstudents.ru/articles/mnk.html
Example.
Experimental data on the values of variables NS and at are given in the table. 
As a result of their alignment, the function is obtained ![]()
Using least square method, approximate this data with a linear dependence y = ax + b(find parameters a and b). Find out which of the two lines is better (in the sense of the least squares method) equalizes the experimental data. Make a drawing.
Solution.
In our example n = 5... We fill in the table for the convenience of calculating the amounts that are included in the formulas of the desired coefficients. 
The values in the fourth row of the table are obtained by multiplying the values of the 2nd row by the values of the 3rd row for each number i.
The values in the fifth row of the table are obtained by squaring the values of the 2nd row for each number i.
The values in the last column of the table are the sums of the values by row.
We use the formulas of the least squares method to find the coefficients a and b... We substitute in them the corresponding values from the last column of the table: 
Hence, y = 0.165x + 2.184- the required approximating straight line.
It remains to find out which of the lines y = 0.165x + 2.184 or ![]() better approximates the original data, that is, make an estimate using the least squares method.
better approximates the original data, that is, make an estimate using the least squares method.
Proof.
So that when found a and b the function takes the smallest value, it is necessary that at this point the matrix of the quadratic form of the second-order differential for the function ![]() was positively definite. Let's show it.
was positively definite. Let's show it.
The differential of the second order has the form: 
That is
Therefore, the matrix of the quadratic form has the form 
and the values of the elements do not depend on a and b.
Let us show that the matrix is positive definite. This requires the corner minors to be positive.
Corner minor of the first order  ... The inequality is strict, since the points
... The inequality is strict, since the points