
Función lineal de mínimos cuadrados. Aproximación de una función por el método de los mínimos cuadrados. Una breve teoría de los mínimos cuadrados para la dependencia lineal
Método de mínimos cuadrados (OLS, ing. Ordinary Least Squares, OLS)- un método matemático utilizado para resolver varios problemas, basado en minimizar la suma de los cuadrados de las desviaciones de algunas funciones de las variables deseadas. Se puede usar para "resolver" sistemas de ecuaciones sobredeterminados (cuando el número de ecuaciones excede el número de incógnitas), para encontrar una solución en el caso de sistemas de ecuaciones no lineales ordinarios (no sobredeterminados), para aproximar los valores de los puntos. de una función determinada. OLS es uno de los métodos básicos de análisis de regresión para estimar parámetros desconocidos de modelos de regresión a partir de datos de muestra.
YouTube enciclopédico
1 / 5
✪ Método de mínimos cuadrados. Temática
✪ Mínimos cuadrados, lección 1/2. Función lineal
✪ Econometría. Clase 5. Método de mínimos cuadrados
✪ Mitin I. V. - Procesamiento de los resultados del examen físico. experimento - Método de mínimos cuadrados (Clase 4)
✪ Econometría: La esencia del método de mínimos cuadrados #2
subtítulos
Historia
Hasta principios del siglo XIX. los científicos no tenían ciertas reglas para resolver un sistema de ecuaciones en el que el número de incógnitas es menor que el número de ecuaciones; Hasta ese momento, se usaban métodos particulares, dependiendo del tipo de ecuaciones y del ingenio de las calculadoras, y por lo tanto, diferentes calculadoras, partiendo de los mismos datos de observación, llegaban a diferentes conclusiones. A Gauss (1795) se le atribuye la primera aplicación del método, y Legendre (1805) lo descubrió y publicó de forma independiente con su nombre moderno (fr. Metodo des moindres quarres) . Laplace conectó el método con la teoría de las probabilidades y el matemático estadounidense Adrian (1808) consideró sus aplicaciones probabilísticas. El método está muy extendido y mejorado por investigaciones adicionales de Encke, Bessel, Hansen y otros.
La esencia del método de los mínimos cuadrados.
Dejar x (\ estilo de visualización x)- equipo n (\ estilo de visualización n) variables desconocidas (parámetros), f yo (x) (\displaystyle f_(i)(x)), , m > n (\displaystyle m>n)- conjunto de funciones de este conjunto de variables. El problema es elegir tales valores. x (\ estilo de visualización x) para que los valores de estas funciones se acerquen lo más posible a algunos valores y yo (\displaystyle y_(i)). En esencia, estamos hablando de la “solución” del sistema de ecuaciones sobredeterminado f yo (x) = y yo (\displaystyle f_(i)(x)=y_(i)), yo = 1 , ... , metro (\displaystyle i=1,\ldots ,m) en el sentido indicado, la máxima proximidad de las partes izquierda y derecha del sistema. La esencia de LSM es elegir como "medida de proximidad" la suma de las desviaciones al cuadrado de las partes izquierda y derecha | F yo (x) - y yo | (\displaystyle |f_(i)(x)-y_(i)|). Así, la esencia de la LSM se puede expresar de la siguiente manera:
∑ yo mi yo 2 = ∑ yo (y yo - F yo (x)) 2 → min x (\displaystyle \sum _(i)e_(i)^(2)=\sum _(i)(y_(i)-f_( i)(x))^(2)\flecha derecha \min _(x)).Si el sistema de ecuaciones tiene una solución, entonces el mínimo de la suma de los cuadrados será igual a cero y las soluciones exactas del sistema de ecuaciones se pueden encontrar analíticamente o, por ejemplo, mediante varios métodos de optimización numérica. Si el sistema está sobredeterminado, es decir, en términos generales, el número de ecuaciones independientes es mayor que el número de variables desconocidas, entonces el sistema no tiene una solución exacta y el método de mínimos cuadrados nos permite encontrar algún vector "óptimo". x (\ estilo de visualización x) en el sentido de la máxima proximidad de los vectores y (\ estilo de visualización y) y f (x) (\displaystyle f(x)) o la proximidad máxima del vector de desviación e (\ estilo de visualización e) a cero (la proximidad se entiende en el sentido de distancia euclidiana).
Ejemplo - sistema de ecuaciones lineales
En particular, el método de los mínimos cuadrados se puede utilizar para "resolver" el sistema de ecuaciones lineales
A x = segundo (\displaystyle Ax=b),donde A (\ estilo de visualización A) matriz de tamaño rectangular metro × norte , metro > norte (\displaystyle m\times n,m>n)(es decir, el número de filas de la matriz A es mayor que el número de variables requeridas).
Tal sistema de ecuaciones generalmente no tiene solución. Por lo tanto, este sistema puede "resolverse" solo en el sentido de elegir dicho vector x (\ estilo de visualización x) para minimizar la "distancia" entre vectores A x (\displaystyle Hacha) y b (\ estilo de visualización b). Para ello se puede aplicar el criterio de minimización de la suma de las diferencias al cuadrado de las partes izquierda y derecha de las ecuaciones del sistema, es decir (A x − b) T (A x − b) → min x (\displaystyle (Ax-b)^(T)(Ax-b)\rightarrow \min _(x)). Es fácil demostrar que la solución de este problema de minimización conduce a la solución del siguiente sistema de ecuaciones
UN T UN x = UN T segundo ⇒ x = (UN T UN) − 1 UN T segundo (\displaystyle A^(T)Ax=A^(T)b\Rightarrow x=(A^(T)A)^(-1)A^ (Tuberculosis).MCO en análisis de regresión (aproximación de datos)
Dejalo ser n (\ estilo de visualización n) valores de alguna variable y (\ estilo de visualización y)(pueden ser los resultados de observaciones, experimentos, etc.) y las variables correspondientes x (\ estilo de visualización x). El reto es hacer que la relación entre y (\ estilo de visualización y) y x (\ estilo de visualización x) aproximado por alguna función conocida hasta algunos parámetros desconocidos b (\ estilo de visualización b), es decir, encontrar realmente los mejores valores de los parámetros b (\ estilo de visualización b), aproximando al máximo los valores f (x, b) (\displaystyle f(x,b)) a los valores reales y (\ estilo de visualización y). De hecho, esto se reduce al caso de "solución" de un sistema de ecuaciones sobredeterminado con respecto a b (\ estilo de visualización b):
F (x t , segundo) = y t , t = 1 , ... , norte (\displaystyle f(x_(t),b)=y_(t),t=1,\ldots,n).
En el análisis de regresión, y en particular en la econometría, se utilizan modelos probabilísticos de relación entre variables.
Y t = F (x t , segundo) + ε t (\displaystyle y_(t)=f(x_(t),b)+\varepsilon _(t)),
donde ε t (\displaystyle \varepsilon_(t))- así llamado errores aleatorios modelos
En consecuencia, las desviaciones de los valores observados y (\ estilo de visualización y) del modelo f (x, b) (\displaystyle f(x,b)) ya asumido en el propio modelo. La esencia de LSM (ordinario, clásico) es encontrar tales parámetros b (\ estilo de visualización b), en el que la suma de las desviaciones al cuadrado (errores, para los modelos de regresión a menudo se denominan residuos de regresión) e t (\displaystyle e_(t)) será mínimo:
segundo ^ O L S = arg min segundo R S S (b) (\displaystyle (\hat (b))_(OLS)=\arg \min _(b)RSS(b)),donde R S S (\displaystyle RSS)- Inglés. La suma residual de cuadrados se define como:
R S S (b) = mi T mi = ∑ t = 1 norte mi t 2 = ∑ t = 1 norte (y t − F (x t , b)) 2 (\displaystyle RSS(b)=e^(T)e=\sum _ (t=1)^(n)e_(t)^(2)=\sum_(t=1)^(n)(y_(t)-f(x_(t),b))^(2) ).En el caso general, este problema se puede resolver mediante métodos numéricos de optimización (minimización). En este caso, se habla de mínimos cuadrados no lineales(NLS o NLLS - ing. Mínimos cuadrados no lineales). En muchos casos, se puede obtener una solución analítica. Para resolver el problema de minimización, es necesario encontrar los puntos estacionarios de la función R S S (b) (\displaystyle RSS(b)), diferenciándolo con respecto a parámetros desconocidos b (\ estilo de visualización b), igualando las derivadas a cero y resolviendo el sistema de ecuaciones resultante:
∑ t = 1 norte (y t − F (x t , segundo)) ∂ F (x t , segundo) ∂ segundo = 0 (\displaystyle \sum _(t=1)^(n)(y_(t)-f(x_ (t),b))(\frac (\parcial f(x_(t),b))(\parcial b))=0).LSM en el caso de regresión lineal
Sea la dependencia de la regresión lineal:
y t = ∑ j = 1 k segundo j X t j + ε = X t T segundo + ε t (\displaystyle y_(t)=\sum _(j=1)^(k)b_(j)x_(tj)+\varepsilon =x_( t)^(T)b+\varepsilon_(t)).Dejar y es el vector columna de observaciones de la variable que se explica, y X (\ estilo de visualización X)- este es (n × k) (\displaystyle ((n\times k)))- matriz de observaciones de factores (filas de la matriz - vectores de valores de factores en una observación dada, por columnas - vector de valores de un factor dado en todas las observaciones). La representación matricial del modelo lineal tiene la forma:
y = Xb + ε (\displaystyle y=Xb+\varepsilon).Entonces el vector de estimaciones de la variable explicada y el vector de residuos de regresión serán iguales a
y ^ = X segundo , mi = y − y ^ = y − X segundo (\displaystyle (\hat (y))=Xb,\quad e=y-(\hat (y))=y-Xb).en consecuencia, la suma de los cuadrados de los residuos de la regresión será igual a
R S S = mi T mi = (y − X segundo) T (y − X segundo) (\displaystyle RSS=e^(T)e=(y-Xb)^(T)(y-Xb)).Derivando esta función con respecto al vector de parámetros b (\ estilo de visualización b) e igualando las derivadas a cero, obtenemos un sistema de ecuaciones (en forma matricial):
(X T X) segundo = X T y (\displaystyle (X^(T)X)b=X^(T)y).En la forma matricial descifrada, este sistema de ecuaciones se ve así:
(∑ x t 1 2 ∑ x t 1 x t 2 ∑ x t 1 x t 3 … ∑ x t 1 x t k ∑ x t 2 x t 1 ∑ x t 2 2 ∑ x t 2 x t 3 … ∑ x t 2 x t k ∑ x t 3 x t 2 … ∑ x t ∑ x t 3 x t k ⋮ ⋮ ⋮ ⋱ ⋮ ∑ x t k x t 1 ∑ x t k x t 2 ∑ x t k x t 3 … ∑ x t k 2) (b 1 b 2 b 3 ⋮ b k) = (∑ x t 1 y x t ∑ x 3 y ∑ t) estilo (\begin(pmatrix)\sum x_(t1)^(2)&\sum x_(t1)x_(t2)&\sum x_(t1)x_(t3)&\ldots &\sum x_(t1)x_( tk)\\\suma x_(t2)x_(t1)&\suma x_(t2)^(2)&\suma x_(t2)x_(t3)&\ldots &\ suma x_(t2)x_(tk) \\\suma x_(t3)x_(t1)&\suma x_(t3)x_(t2)&\suma x_(t3)^(2)&\ldots &\suma x_ (t3)x_(tk)\\ \vdots &\vdots &\vdots &\ddots &\vdots \\\sum x_(tk)x_(t1)&\sum x_(tk)x_(t2)&\sum x_ (tk)x_(t3)&\ ldots &\sum x_(tk)^(2)\\\end(pmatrix))(\begin(pmatrix)b_(1)\\b_(2)\\b_(3 )\\\vdots \\b_( k)\\\end(pmatriz))=(\begin(pmatriz)\sum x_(t1)y_(t)\\\sum x_(t2)y_(t)\\ \sum x_(t3)y_(t )\\\vpuntos \\\sum x_(tk)y_(t)\\\end(pmatriz))) donde todas las sumas se toman sobre todos los valores admisibles t (\ estilo de visualización t).
Si se incluye una constante en el modelo (como es habitual), entonces x t 1 = 1 (\displaystyle x_(t1)=1) para todos t (\ estilo de visualización t), por lo tanto, en la esquina superior izquierda de la matriz del sistema de ecuaciones está el número de observaciones n (\ estilo de visualización n), y en los elementos restantes de la primera fila y la primera columna, solo la suma de los valores de las variables: ∑ x t j (\displaystyle \sum x_(tj)) y el primer elemento del lado derecho del sistema - ∑ y t (\displaystyle \sum y_(t)).
La solución de este sistema de ecuaciones da la fórmula general para las estimaciones de mínimos cuadrados para el modelo lineal:
segundo ^ O L S = (X T X) − 1 X T y = (1 norte X T X) − 1 1 norte X T y = V x − 1 C x y (\displaystyle (\hat (b))_(OLS)=(X^(T) )X)^(-1)X^(T)y=\left((\frac (1)(n))X^(T)X\right)^(-1)(\frac (1)(n) ))X^(T)y=V_(x)^(-1)C_(xy)).A efectos analíticos resulta útil la última representación de esta fórmula (en el sistema de ecuaciones al dividir por n aparecen medias aritméticas en lugar de sumas). Si los datos en el modelo de regresión centrado, entonces en esta representación la primera matriz tiene el significado de matriz de covarianzas muestrales de factores, y la segunda es el vector de covarianzas de factores con variable dependiente. Si, además, los datos también son normalizado en el SKO (es decir, en última instancia estandarizado), entonces la primera matriz tiene el significado de la matriz de correlación de muestra de factores, el segundo vector - el vector de correlación de muestra de factores con la variable dependiente.
Una propiedad importante de las estimaciones LLS para modelos con una constante- la línea de la regresión construida pasa por el centro de gravedad de los datos muestrales, es decir, se cumple la igualdad:
y ¯ = segundo 1 ^ + ∑ j = 2 k segundo ^ j X ¯ j (\displaystyle (\bar (y))=(\hat (b_(1)))+\sum _(j=2)^(k) (\sombrero (b))_(j)(\bar (x))_(j)).En particular, en el caso extremo, cuando el único regresor es una constante, encontramos que la estimación MCO de un solo parámetro (la propia constante) es igual al valor medio de la variable que se explica. Es decir, la media aritmética, conocida por sus buenas propiedades de las leyes de los grandes números, también es una estimación de mínimos cuadrados: satisface el criterio de la suma mínima de las desviaciones al cuadrado.
Los casos especiales más simples.
En el caso de la regresión lineal por pares y t = una + segundo x t + ε t (\displaystyle y_(t)=a+bx_(t)+\varepsilon _(t)), cuando se estima la dependencia lineal de una variable con otra, las fórmulas de cálculo se simplifican (se puede prescindir del álgebra matricial). El sistema de ecuaciones tiene la forma:
(1 x ¯ x ¯ x 2 ¯) (a segundo) = (y ¯ x y ¯) (\displaystyle (\begin(pmatrix)1&(\bar (x))\\(\bar (x))&(\bar (x^(2)))\\\end(pmatriz))(\begin(pmatriz)a\\b\\\end(pmatriz))=(\begin(pmatriz)(\bar (y))\\ (\overline(xy))\\\end(pmatriz))).A partir de aquí es fácil encontrar estimaciones para los coeficientes:
( segundo ^ = Cov (x , y) Var (x) = x y ¯ − x ¯ y ¯ x 2 ¯ − x ¯ 2 , un ^ = y ¯ − segundo x ¯ . (\displaystyle (\begin(cases) (\hat (b))=(\frac (\mathop (\textrm (Cov)) (x,y))(\mathop (\textrm (Var)) (x)))=(\frac ((\overline (xy))-(\bar (x))(\bar (y)))((\overline (x^(2)))-(\overline (x))^(2))),\\( \hat (a))=(\bar (y))-b(\bar (x)).\end(casos)))A pesar de que, en general, los modelos con una constante son preferibles, en algunos casos se sabe por consideraciones teóricas que la constante a (\ estilo de visualización a) debe ser igual a cero. Por ejemplo, en física, la relación entre voltaje y corriente tiene la forma U = yo ⋅ R (\displaystyle U=I\cdot R); midiendo voltaje y corriente, es necesario estimar la resistencia. En este caso, estamos hablando de un modelo. y = segundo x (\displaystyle y=bx). En este caso, en lugar de un sistema de ecuaciones, tenemos una sola ecuación
(∑ x t 2) segundo = ∑ x t y t (\displaystyle \left(\sum x_(t)^(2)\right)b=\sum x_(t)y_(t)).
Por lo tanto, la fórmula para estimar un solo coeficiente tiene la forma
segundo ^ = ∑ t = 1 norte X t y t ∑ t = 1 norte X t 2 = X y ¯ x 2 ¯ (\displaystyle (\hat (b))=(\frac (\sum _(t=1)^(n)x_(t )y_(t))(\sum _(t=1)^(n)x_(t)^(2)))=(\frac (\overline (xy))(\overline (x^(2)) ))).
El caso de un modelo polinomial
Si los datos se ajustan mediante una función de regresión polinomial de una variable f (x) = segundo 0 + ∑ yo = 1 k segundo yo x yo (\displaystyle f(x)=b_(0)+\sum \limits _(i=1)^(k)b_(i)x^(i)), entonces, percibiendo grados x yo (\ estilo de visualización x ^ (i)) como factores independientes para cada yo (\ estilo de visualización i) es posible estimar los parámetros del modelo en base a la fórmula general para estimar los parámetros del modelo lineal. Para ello, basta tener en cuenta en la fórmula general que con tal interpretación x t yo x t j = x t yo x t j = x t yo + j (\displaystyle x_(ti)x_(tj)=x_(t)^(i)x_(t)^(j)=x_(t)^(i+j)) y x t j y t = x t j y t (\displaystyle x_(tj)y_(t)=x_(t)^(j)y_(t)). Por lo tanto, las ecuaciones matriciales en este caso tomarán la forma:
(norte ∑ norte X t ... ∑ norte X t k ∑ norte x t ∑ norte X t 2 ... ∑ norte X t k + 1 ⋮ ⋱ ⋮ ∑ norte x t k ∑ norte x t k + 1 ... ∑ norte x t 2 k) [segundo 0 segundo 1 ⋮ segundo k] = [ ∑ norte ∑ norte X t y t ⋮ norte X t k y t ] . (\displaystyle (\begin(pmatrix)n&\sum \limits _(n)x_(t)&\ldots &\sum \limits _(n)x_(t)^(k)\\\sum \limits _( n)x_(t)&\sum \limits _(n)x_(t)^(2)&\ldots &\sum \limits _(n)x_(t)^(k+1)\\\vdots & \vdots &\ddots &\vdots \\\sum \limits _(n)x_(t)^(k)&\sum \limits _(n)x_(t)^(k+1)&\ldots &\ suma \limits _(n)x_(t)^(2k)\end(pmatrix))(\begin(bmatrix)b_(0)\\b_(1)\\\vdots \\b_(k)\end( bmatriz))=(\begin(bmatriz)\sum \limits _(n)y_(t)\\\sum \limits _(n)x_(t)y_(t)\\\vdots \\\sum \limits _(n)x_(t)^(k)y_(t)\end(bmatriz)).)
Propiedades estadísticas de las estimaciones de OLS
En primer lugar, observamos que para los modelos lineales, las estimaciones de mínimos cuadrados son estimaciones lineales, como se deduce de la fórmula anterior. Para la falta de sesgo de las estimaciones de mínimos cuadrados, es necesario y suficiente cumplir con la condición más importante del análisis de regresión: la expectativa matemática de un error aleatorio condicionado a los factores debe ser igual a cero. Esta condición se cumple, en particular, si
- la expectativa matemática de errores aleatorios es cero, y
- los factores y los errores aleatorios son valores aleatorios independientes.
La segunda condición, la condición de los factores exógenos, es fundamental. Si esta propiedad no se cumple, entonces podemos suponer que casi todas las estimaciones serán extremadamente insatisfactorias: ni siquiera serán consistentes (es decir, incluso una gran cantidad de datos no permite obtener estimaciones cualitativas en este caso). En el caso clásico, se hace una suposición más fuerte sobre el determinismo de los factores, en contraste con un error aleatorio, lo que automáticamente significa que se cumple la condición exógena. En el caso general, para la consistencia de las estimaciones, es suficiente satisfacer la condición de exogeneidad junto con la convergencia de la matriz Vx (\displaystyle V_(x)) a alguna matriz no degenerada a medida que el tamaño de la muestra aumenta hasta el infinito.
Para que, además de la consistencia y la imparcialidad, las estimaciones de los (habituales) mínimos cuadrados sean también efectivas (las mejores de la clase de estimaciones lineales insesgadas), es necesario cumplir propiedades adicionales de un error aleatorio:
Estos supuestos se pueden formular para la matriz de covarianza del vector de errores aleatorios V (ε) = σ 2 yo (\displaystyle V(\varepsilon)=\sigma ^(2)I).
Un modelo lineal que satisface estas condiciones se llama clásico. Las estimaciones de OLS para la regresión lineal clásica son estimaciones no sesgadas, consistentes y más eficientes en la clase de todas las estimaciones lineales no sesgadas (en la literatura inglesa, la abreviatura se usa a veces azul (Mejor estimador lineal imparcial) es la mejor estimación lineal insesgada; en la literatura nacional, se cita más a menudo el teorema de Gauss - Markov). Como es fácil de demostrar, la matriz de covarianza del vector de estimación de coeficientes será igual a:
V (segundo ^ O L S) = σ 2 (X T X) − 1 (\displaystyle V((\hat (b))_(OLS))=\sigma ^(2)(X^(T)X)^(-1 )).
Eficiencia significa que esta matriz de covarianza es "mínima" (cualquier combinación lineal de coeficientes, y en particular los propios coeficientes, tienen una varianza mínima), es decir, en la clase de estimaciones lineales insesgadas, las estimaciones OLS son las mejores. Los elementos diagonales de esta matriz -las varianzas de las estimaciones de los coeficientes- son parámetros importantes de la calidad de las estimaciones obtenidas. Sin embargo, no es posible calcular la matriz de covarianza porque se desconoce la varianza del error aleatorio. Se puede demostrar que la estimación imparcial y consistente (para el modelo lineal clásico) de la varianza de los errores aleatorios es el valor:
S 2 = R S S / (n − k) (\displaystyle s^(2)=RSS/(n-k)).
Sustituyendo este valor en la fórmula de la matriz de covarianza, obtenemos una estimación de la matriz de covarianza. Las estimaciones resultantes también son imparciales y consistentes. También es importante que la estimación de la varianza del error (y por tanto las varianzas de los coeficientes) y las estimaciones de los parámetros del modelo sean variables aleatorias independientes, lo que permite obtener estadísticos de prueba para contrastar hipótesis sobre los coeficientes del modelo.
Cabe señalar que si no se cumplen los supuestos clásicos, las estimaciones de los parámetros de mínimos cuadrados no son las más eficientes y, cuando W (\ estilo de visualización W) es una matriz de peso definida positiva simétrica. Los mínimos cuadrados ordinarios son un caso especial de este enfoque, cuando la matriz de peso es proporcional a la matriz identidad. Como es sabido, para matrices simétricas (u operadores) existe una descomposición W = PAGS T PAGS (\displaystyle W=P^(T)P). Por lo tanto, este funcional se puede representar de la siguiente manera mi T PAGS T PAGS mi = (PAGS mi) T PAGS mi = mi ∗ T mi ∗ (\displaystyle e^(T)P^(T)Pe=(Pe)^(T)Pe=e_(*)^(T)e_( *)), es decir, este funcional se puede representar como la suma de los cuadrados de algunos "residuales" transformados. Por lo tanto, podemos distinguir una clase de métodos de mínimos cuadrados: métodos LS (Least Squares).
Se demuestra (teorema de Aitken) que para un modelo de regresión lineal generalizado (en el que no se imponen restricciones a la matriz de covarianza de errores aleatorios), los más efectivos (en la clase de estimaciones lineales no sesgadas) son las estimaciones de los llamados. MCO generalizado (OMNK, GLS - Mínimos cuadrados generalizados)- Método LS con una matriz de peso igual a la matriz de covarianza inversa de errores aleatorios: W = V ε − 1 (\displaystyle W=V_(\varepsilon)^(-1)).
Se puede demostrar que la fórmula para las estimaciones GLS de los parámetros del modelo lineal tiene la forma
segundo ^ GRAMO L S = (X T V − 1 X) − 1 X T V − 1 y (\displaystyle (\hat (b))_(GLS)=(X^(T)V^(-1)X)^(-1) X^(T)V^(-1)y).
La matriz de covarianza de estas estimaciones, respectivamente, será igual a
V (segundo ^ GRAMO L S) = (X T V − 1 X) − 1 (\displaystyle V((\hat (b))_(GLS))=(X^(T)V^(-1)X)^(- 1)).
De hecho, la esencia del OLS radica en una cierta transformación (lineal) (P) de los datos originales y la aplicación de los mínimos cuadrados habituales a los datos transformados. El propósito de esta transformación es que para los datos transformados, los errores aleatorios ya satisfagan los supuestos clásicos.
Mínimos cuadrados ponderados
En el caso de una matriz de pesos diagonal (y por tanto de la matriz de covarianza de errores aleatorios), tenemos los llamados mínimos cuadrados ponderados (WLS - Weighted Least Squares). En este caso, se minimiza la suma ponderada de cuadrados de los residuos del modelo, es decir, cada observación recibe un “peso” que es inversamente proporcional a la varianza del error aleatorio en esta observación: mi T W mi = ∑ t = 1 norte mi t 2 σ t 2 (\displaystyle e^(T)We=\sum _(t=1)^(n)(\frac (e_(t)^(2))(\ sigma_(t)^(2)))). De hecho, los datos se transforman ponderando las observaciones (dividiendo por una cantidad proporcional a la desviación estándar supuesta de los errores aleatorios), y se aplican mínimos cuadrados normales a los datos ponderados.
ISBN 978-5-7749-0473-0.
TRABAJO DEL CURSO
disciplina: Informática
Tema: Aproximación de una función por el método de los mínimos cuadrados
Introducción
1. Planteamiento del problema
2. Fórmulas de cálculo
Cálculo usando tablas hechas usando Microsoft Excel
esquema de algoritmo
Cálculo en MathCad
Resultados lineales
Presentación de resultados en forma de gráficos.
Introducción
El objetivo del trabajo del curso es profundizar el conocimiento en informática, desarrollar y consolidar habilidades en el trabajo con el procesador de hojas de cálculo Microsoft Excel y el producto de software MathCAD y aplicarlos para resolver problemas usando una computadora del área temática relacionada con la investigación.
Aproximación (del latín "approximare" - "aproximación") - una expresión aproximada de cualquier objeto matemático (por ejemplo, números o funciones) a través de otros más simples, más convenientes de usar o simplemente más conocidos. En la investigación científica, la aproximación se utiliza para describir, analizar, generalizar y utilizar aún más los resultados empíricos.
Como es sabido, puede haber una relación exacta (funcional) entre los valores, cuando un valor del argumento corresponde a un valor específico, y una relación menos precisa (correlación), cuando un valor específico del argumento corresponde a un valor aproximado. o algún conjunto de valores de función que son más o menos cercanos entre sí. Al realizar una investigación científica, procesar los resultados de una observación o experimento, generalmente debe lidiar con la segunda opción.
Al estudiar las dependencias cuantitativas de varios indicadores, cuyos valores se determinan empíricamente, por regla general, existe cierta variabilidad. Está determinada en parte por la heterogeneidad de los objetos estudiados de naturaleza inanimada y, especialmente, viva, y en parte por el error de observación y procesamiento cuantitativo de los materiales. No siempre es posible eliminar por completo el último componente; solo puede minimizarse mediante una elección cuidadosa de un método de investigación adecuado y la precisión del trabajo. Por lo tanto, al realizar cualquier trabajo de investigación, surge el problema de identificar la verdadera naturaleza de la dependencia de los indicadores estudiados, tal o cual grado enmascarado por el descuido de la variabilidad: los valores. Para esto, se utiliza la aproximación: una descripción aproximada de la dependencia de correlación de las variables mediante una ecuación de dependencia funcional adecuada que transmite la tendencia principal de la dependencia (o su "tendencia").
Al elegir una aproximación, uno debe partir de la tarea específica del estudio. Por lo general, cuanto más simple sea la ecuación utilizada para la aproximación, más aproximada será la descripción obtenida de la dependencia. Por lo tanto, es importante leer qué tan significativo y qué causó las desviaciones de valores específicos de la tendencia resultante. Al describir la dependencia de valores determinados empíricamente, se puede lograr una precisión mucho mayor utilizando una ecuación multiparamétrica más compleja. Sin embargo, no tiene sentido tratar de transmitir desviaciones aleatorias de valores en series específicas de datos empíricos con la máxima precisión. Es mucho más importante captar la regularidad general, que en este caso es más lógicamente y con una precisión aceptable expresada precisamente por la ecuación de dos parámetros de la función de potencia. Por lo tanto, al elegir un método de aproximación, el investigador siempre hace un compromiso: decide hasta qué punto en este caso es conveniente y apropiado "sacrificar" los detalles y, en consecuencia, qué tan generalizada debe expresarse la dependencia de las variables comparadas. Junto con la identificación de patrones enmascarados por desviaciones aleatorias de datos empíricos del patrón general, la aproximación también permite resolver muchos otros problemas importantes: formalizar la dependencia encontrada; encontrar valores desconocidos de la variable dependiente por interpolación o, en su caso, extrapolación.
En cada tarea se formulan las condiciones del problema, los datos iniciales, la forma de emisión de resultados, se indican las principales dependencias matemáticas para la resolución del problema. De acuerdo con el método para resolver el problema, se desarrolla un algoritmo de solución, que se presenta en forma gráfica.
1. Planteamiento del problema
1. Usando el método de mínimos cuadrados, aproxime la función dada en una tabla:
a) un polinomio de primer grado ![]() ;
;
b) un polinomio de segundo grado;
c) dependencia exponencial.
Para cada dependencia, calcule el coeficiente de determinismo.
Calcular el coeficiente de correlación (solo en el caso a).
Dibuje una línea de tendencia para cada dependencia.
Usando la función ESTIMACION.LINEAL, calcule las características numéricas de la dependencia de .
Compare sus cálculos con los resultados obtenidos usando la función ESTIMACION.LINEAL.
Concluya cuál de las fórmulas obtenidas se aproxima mejor a la función.
Escriba un programa en uno de los lenguajes de programación y compare los resultados del cálculo con los obtenidos anteriormente.
Opción 3. La función se da en la Tabla. 1.
Tabla 1.
2. Fórmulas de cálculo A menudo, al analizar datos empíricos, se hace necesario encontrar una relación funcional entre los valores de xey, que se obtienen como resultado de la experiencia o las mediciones. Xi (valor independiente) lo establece el experimentador, y yi, llamados valores empíricos o experimentales, se obtiene como resultado del experimento. La forma analítica de la dependencia funcional que existe entre los valores x e y generalmente se desconoce, por lo tanto, surge una tarea prácticamente importante: encontrar una fórmula empírica. (dónde están los parámetros), cuyos valores posiblemente diferirían poco de los valores experimentales. De acuerdo con el método de mínimos cuadrados, los mejores coeficientes son aquellos para los cuales la suma de las desviaciones al cuadrado de la función empírica encontrada de los valores dados de la función será mínima. Usando la condición necesaria para el extremo de una función de varias variables - igualdad a cero de derivadas parciales, encuentre un conjunto de coeficientes que entreguen el mínimo de la función definida por la fórmula (2) y obtenga un sistema normal para determinar los coeficientes Por lo tanto, encontrar los coeficientes se reduce a resolver el sistema (3). El tipo de sistema (3) depende de la clase de fórmulas empíricas de las que buscamos la dependencia (1). En el caso de una dependencia lineal, el sistema (3) tomará la forma: En el caso de una dependencia cuadrática, el sistema (3) tomará la forma: En algunos casos, como fórmula empírica, se toma una función en la que entran coeficientes inciertos de forma no lineal. En este caso, a veces el problema se puede linealizar, es decir reducir a lineal. Entre tales dependencias se encuentra la dependencia exponencial donde a1 y a2 son coeficientes indefinidos. La linealización se logra tomando el logaritmo de la igualdad (6), luego de lo cual obtenemos la relación Denotemos y respectivamente por y , entonces la dependencia (6) se puede escribir como , lo que nos permite aplicar las fórmulas (4) con a1 reemplazada por y por . La gráfica de la dependencia funcional restaurada y(x) basada en los resultados de las mediciones (xi, yi), i=1,2,…,n se denomina curva de regresión. Para comprobar la concordancia de la curva de regresión construida con los resultados del experimento, se suelen introducir las siguientes características numéricas: el coeficiente de correlación (dependencia lineal), la razón de correlación y el coeficiente de determinismo. El coeficiente de correlación es una medida de la relación lineal entre variables aleatorias dependientes: muestra qué tan bien, en promedio, una de las variables se puede representar como una función lineal de la otra. El coeficiente de correlación se calcula mediante la fórmula: donde es la media aritmética, respectivamente, para x, y. El coeficiente de correlación entre variables aleatorias no supera en valor absoluto 1. Cuanto más cerca de 1, más estrecha es la relación lineal entre x e y. En el caso de una correlación no lineal, los valores promedio condicionales se ubican cerca de la línea curva. En este caso, como característica de la fuerza de la conexión, se recomienda utilizar la relación de correlación, cuya interpretación no depende del tipo de dependencia en estudio. La relación de correlación se calcula mediante la fórmula: donde Siempre. Igualdad = corresponde a variables aleatorias no correlacionadas; = si y sólo si existe una relación funcional exacta entre x e y. En el caso de una dependencia lineal de y respecto de x, la relación de correlación coincide con el cuadrado del coeficiente de correlación. El valor se utiliza como indicador de la desviación de la regresión de la linealidad. El índice de correlación es una medida de la correlación y c x en cualquier forma, pero no puede dar una idea del grado de cercanía de los datos empíricos a una forma especial. Para averiguar con qué precisión la curva construida refleja los datos empíricos, se introduce una característica más: el coeficiente de determinación. El coeficiente de determinismo está determinado por la fórmula: donde Sres = - suma residual de cuadrados, que caracteriza la desviación de los datos experimentales de los teóricos total - suma total de cuadrados, donde el valor promedio es yi. Cuanto menor sea la suma residual de cuadrados en comparación con la suma total de cuadrados, mayor será el valor del coeficiente de determinismo r2, que indica qué tan bien la ecuación obtenida mediante el análisis de regresión explica las relaciones entre variables. Si es igual a 1, entonces existe una correlación completa con el modelo, es decir, no hay diferencia entre los valores reales y estimados de y. De lo contrario, si el coeficiente de determinismo es 0, entonces la ecuación de regresión no puede predecir los valores de y. El coeficiente de determinismo siempre no excede la relación de correlación. En el caso de que se satisfaga la igualdad, podemos suponer que la fórmula empírica construida refleja con mayor precisión los datos empíricos. 3. Cálculo mediante tablas realizadas con Microsoft Excel Para los cálculos, es recomendable ordenar los datos en forma de tabla 2 utilizando la hoja de cálculo Microsoft Excel. Tabla 2
Expliquemos cómo se compila la Tabla 2. Paso 1. En las celdas A1:A25 ingresamos los valores xi. Paso 2. En las celdas B1:B25 ingresamos los valores de yi. Paso 3. En la celda C1, ingresa la fórmula = A1 ^ 2. Paso 4. Esta fórmula se copia en las celdas C1:C25. Paso 5. En la celda D1, ingresa la fórmula = A1 * B1. Paso 6. Esta fórmula se copia en las celdas D1:D25. Paso 7. En la celda F1, ingresa la fórmula = A1 ^ 4. Paso 8. En las celdas F1:F25, se copia esta fórmula. Paso 9. En la celda G1, ingresa la fórmula =A1^2*B1. Paso 10. Esta fórmula se copia en las celdas G1:G25. Paso 11. En la celda H1, ingresa la fórmula = LN (B1). Paso 12. Esta fórmula se copia en las celdas H1:H25. Paso 13. En la celda I1, ingresa la fórmula = A1 * LN (B1). Paso 14. Esta fórmula se copia en las celdas I1:I25. Hacemos los siguientes pasos usando la autosuma S. Paso 15. En la celda A26, ingresa la fórmula = SUMA (A1: A25). Paso 16. En la celda B26, ingresa la fórmula = SUMA (B1: B25). Paso 17. En la celda C26, ingresa la fórmula = SUMA (C1: C25). Paso 18. En la celda D26, ingresa la fórmula = SUMA (D1: D25). Paso 19. En la celda E26, ingresa la fórmula = SUMA (E1: E25). Paso 20. En la celda F26, ingresa la fórmula = SUMA (F1: F25). Paso 21. En la celda G26, ingresa la fórmula = SUMA (G1: G25). Paso 22. En la celda H26, ingresa la fórmula = SUM(H1:H25). Paso 23. En la celda I26, ingresa la fórmula = SUMA(I1:I25). Aproximamos la función por una función lineal. Para determinar los coeficientes y usamos el sistema (4). Usando los totales de la Tabla 2, ubicados en las celdas A26, B26, C26 y D26, escribimos el sistema (4) como resolviendo cual, obtenemos El sistema se resolvió por el método de Cramer. cuya esencia es la siguiente. Considere un sistema de n ecuaciones lineales algebraicas con n incógnitas: El determinante del sistema es el determinante de la matriz del sistema: Denote: el determinante que se obtendrá del determinante del sistema Δ reemplazando la j-ésima columna con la columna Por lo tanto, la aproximación lineal tiene la forma Resolvemos el sistema (11) utilizando las herramientas de Microsoft Excel. Los resultados se presentan en la tabla 3. Tabla 3
matriz inversa En la tabla 3, las celdas A32:B33 contienen la fórmula (=MOBR(A28:B29)). Las celdas E32:E33 contienen la fórmula (=MULTI(A32:B33),(C28:C29)). A continuación, aproximamos la función mediante una función cuadrática resolviendo cual, obtenemos a1=10.663624, Por lo tanto, la aproximación cuadrática tiene la forma Resolvemos el sistema (16) utilizando las herramientas de Microsoft Excel. Los resultados se presentan en la tabla 4. Tabla 4
matriz inversa En la Tabla 4, las celdas A41:C43 contienen la fórmula (=MOBR(A36:C38)). Las celdas F41:F43 contienen la fórmula (=MMULT(A41:C43),(D36:D38)). Ahora aproximamos la función por la función exponencial. Para determinar los coeficientes y tomar el logaritmo de los valores y, utilizando los totales de la Tabla 2, ubicados en las celdas A26, C26, H26 e I26, obtenemos el sistema Resolviendo el sistema (18), obtenemos y . Después de la potenciación obtenemos . Por lo tanto, la aproximación exponencial tiene la forma Resolvemos el sistema (18) utilizando las herramientas de Microsoft Excel. Los resultados se presentan en la tabla 5. Tabla 5
matriz inversa Las celdas A50:B51 contienen la fórmula (=MOBR(A46:B47)). En las celdas E49:E50 se escribe la fórmula (=MULTI(A50:B51),(C46:C47)). La celda E51 contiene la fórmula = EXP (E49). Calcular la media aritmética y por las fórmulas: Los resultados de los cálculos y las herramientas de Microsoft Excel se presentan en la Tabla 6. Tabla 6
La celda B54 contiene la fórmula =A26/25. La celda B55 contiene la fórmula = B26/25 Tabla 7
Paso 1. En la celda J1, ingresa la fórmula = (A1-$B$54)*(B1-$B$55). Paso 2. Esta fórmula se copia en las celdas J2:J25. Paso 3. En la celda K1, ingresa la fórmula = (A1-$B$54)^2. Paso 4. Esta fórmula se copia en las celdas k2:K25. Paso 5. En la celda L1, ingresa la fórmula = (B1-$B$55)^2. Paso 6. Esta fórmula se copia en las celdas L2:L25. Paso 7. En la celda M1, ingresa la fórmula = ($E$32+$E$33*A1-B1)^2. Paso 8. Esta fórmula se copia en las celdas M2:M25. Paso 9. En la celda N1, ingresa la fórmula = ($F$41+$F$42*A1+$F$43*A1^2-B1)^2. Paso 10. En las celdas N2:N25, se copia esta fórmula. Paso 11. En la celda O1, ingresa la fórmula = ($E$51*EXP($E$50*A1)-B1)^2. Paso 12. En las celdas O2:O25, se copia esta fórmula. Realizamos los siguientes pasos utilizando la suma automática S. Paso 13. En la celda J26, ingresa la fórmula = SUMA (J1: J25). Paso 14. En la celda K26, ingresa la fórmula = SUMA (K1:K25). Paso 15. En la celda L26, ingresa la fórmula = SUMA (L1: L25). Paso 16. En la celda M26, ingresa la fórmula = SUMA(M1:M25). Paso 17. En la celda N26, ingresa la fórmula = SUMA (N1: N25). Paso 18. En la celda O26, ingresa la fórmula = SUMA (O1: O25). Ahora calculemos el coeficiente de correlación usando la fórmula (8) (solo para aproximación lineal) y el coeficiente de determinismo usando la fórmula (10). Los resultados de los cálculos utilizando Microsoft Excel se presentan en la Tabla 8. Tabla 8
Coeficiente de correlación Coeficiente de determinismo (aproximación lineal) Coeficiente de determinismo (aproximación cuadrática) Coeficiente de determinismo (aproximación exponencial) La celda E57 contiene la fórmula =J26/(K26*L26)^(1/2). La celda E59 contiene la fórmula = 1-M26/L26. La celda E61 contiene la fórmula = 1-N26/L26. La celda E63 contiene la fórmula = 1-O26/L26. Un análisis de los resultados del cálculo muestra que la aproximación cuadrática describe mejor los datos experimentales. esquema de algoritmo Arroz. 1. Esquema del algoritmo para el programa de cálculo. 5. Cálculo en MathCad Regresión lineal · línea (x, y) - vector de dos elementos (b, a) de coeficientes de regresión lineal b+ax; · x - vector de datos reales del argumento; · y es un vector de valores de datos reales del mismo tamaño. Figura 2. La regresión polinomial significa ajustar los datos (x1, y1) con un polinomio de grado k. Para k=i, el polinomio es una línea recta, para k=2 es una parábola, para k=3 es una parábola cúbica, y así. Como regla, k<5. · regresión (x, y, k) - vector de coeficientes para la construcción de regresión de datos polinómicos; interp (s,x,y,t) - resultado de la regresión polinomial; s=regresión(x,y,k); · x es un vector de datos reales del argumento, cuyos elementos están dispuestos en orden ascendente; · y es un vector de valores de datos reales del mismo tamaño; k - grado del polinomio de regresión (entero positivo); · t - el valor del argumento del polinomio de regresión. figura 3 Además de los considerados, Mathcad incorpora varios tipos más de regresión de tres parámetros, su implementación es algo diferente de las opciones de regresión anteriores en que, además de la matriz de datos, se requiere establecer algunos valores iniciales de los coeficientes a, b, c. Use el tipo de regresión apropiado si tiene una buena idea de qué dependencia describe su matriz de datos. Cuando el tipo de regresión no refleja bien la secuencia de datos, su resultado suele ser insatisfactorio e incluso muy diferente según la elección de los valores iniciales. Cada una de las funciones produce un vector de parámetros refinados a, b, c. Resultados ESTIMACION.LINEAL Considere el propósito de la función ESTIMACION.LINEAL. Esta función utiliza el método de mínimos cuadrados para calcular la línea recta que mejor se ajusta a los datos disponibles. La función devuelve una matriz que describe la línea resultante. La ecuación de una recta es: M1x1 + m2x2 + ... + b o y = mx + b, algoritmo tabular software de microsoft donde el valor dependiente de y es una función del valor independiente de x. Los valores de m son los coeficientes correspondientes a cada variable independiente x, y b es una constante. Tenga en cuenta que y, x y m pueden ser vectores. Para obtener los resultados, debe crear una fórmula de hoja de cálculo que abarque 5 filas y 2 columnas. Este intervalo se puede colocar en cualquier parte de la hoja de trabajo. En este intervalo, debe ingresar la función ESTIMACION.LINEAL. Como resultado, se deben llenar todas las celdas del intervalo A65:B69 (como se muestra en la Tabla 9). Tabla 9
Expliquemos el propósito de algunas de las cantidades ubicadas en la Tabla 9. Los valores ubicados en las celdas A65 y B65 caracterizan la pendiente y el desplazamiento, respectivamente.- coeficiente de determinismo.- valor F-observado.- número de grados de libertad. Presentación de resultados en forma de gráficos. Arroz. 4. Gráfica de aproximación lineal Arroz. 5. Gráfica de Aproximación Cuadrática Arroz. 6. Gráfico de aproximación exponencial recomendaciones Saquemos conclusiones basadas en los resultados de los datos obtenidos. Un análisis de los resultados del cálculo muestra que la aproximación cuadrática describe mejor los datos experimentales, ya que la línea de tendencia refleja con mayor precisión el comportamiento de la función en esta área. Comparando los resultados obtenidos mediante la función ESTIMACION.LINEAL, vemos que coinciden completamente con los cálculos realizados anteriormente. Esto indica que los cálculos son correctos. Los resultados obtenidos utilizando el programa MathCad coinciden completamente con los valores dados anteriormente. Esto indica la exactitud de los cálculos. Bibliografía 1 AP Demidovich, I. A. Granate. Fundamentos de Matemática Computacional. M: Editorial estatal de literatura física y matemática. 2 Informática: Libro de texto, ed. profe. NEVADA. Makárova. M: Finanzas y estadísticas, 2007. 3 Informática: Taller de tecnología informática, ed. profe. NEVADA. Makárova. M: Finanzas y estadísticas, 2010. 4 V.B. Komiagin. Programación en Excel en Visual Basic. M: Radio y comunicación, 2007. 5 N. Nicole, R. Albrecht. Sobresalir. Hojas de cálculo. M: Edición. “ECOM”, 2008. 6 Pautas para la implementación de cursos en informática (para estudiantes del departamento de correspondencia de todas las especialidades), ed. Zhurova G. N., SPbGGI(TU), 2011.
![]() , (1)
, (1)
![]() :
:![]() (3)
(3)
 (4)
(4)
 (5)
(5)
![]() (7)
(7)
 (8)
(8) (9)
(9) (10)
(10)
![]() y el numerador caracteriza la dispersión de los promedios condicionales alrededor del promedio incondicional.
y el numerador caracteriza la dispersión de los promedios condicionales alrededor del promedio incondicional.![]() - suma de cuadrados de regresión que caracteriza la dispersión de los datos.
- suma de cuadrados de regresión que caracteriza la dispersión de los datos.
 (11)
(11)
![]() y .
y . (12)
(12)
 (13)
(13)
![]() . Para determinar los coeficientes a1, a2 y a3, usamos el sistema (5). Usando los totales de la tabla 2, ubicados en las celdas A26, B26, C26, D26, E26, F26, G26, escribimos el sistema (5) como
. Para determinar los coeficientes a1, a2 y a3, usamos el sistema (5). Usando los totales de la tabla 2, ubicados en las celdas A26, B26, C26, D26, E26, F26, G26, escribimos el sistema (5) como  (16)
(16)
![]() y
y ![]()
 (18)
(18)








El método de los mínimos cuadrados es uno de los más comunes y desarrollados debido a su simplicidad y eficiencia de los métodos para estimar los parámetros de linealidad. Al mismo tiempo, se debe tener cierta precaución al usarlo, ya que los modelos construidos con él pueden no cumplir con una serie de requisitos para la calidad de sus parámetros y, como resultado, no reflejan "bien" los patrones de desarrollo del proceso.
Consideremos con más detalle el procedimiento para estimar los parámetros de un modelo econométrico lineal utilizando el método de mínimos cuadrados. Tal modelo en forma general se puede representar mediante la ecuación (1.2):
y t = un 0 + un 1 X 1 t +...+ un norte X nt + ε t .
El dato inicial al estimar los parámetros a 0 , a 1 ,..., an es el vector de valores de la variable dependiente y= (y 1 , y 2 , ... , y T)" y la matriz de valores de las variables independientes

en la que la primera columna, formada por unos, corresponde al coeficiente del modelo.
El método de los mínimos cuadrados obtuvo su nombre basado en el principio básico de que las estimaciones de los parámetros obtenidas sobre su base deben satisfacer: la suma de los cuadrados del error del modelo debe ser mínima.
Ejemplos de resolución de problemas por el método de mínimos cuadrados
Ejemplo 2.1. La empresa comercial tiene una red que consta de 12 tiendas, cuya información sobre las actividades se presenta en la Tabla. 2.1.
A la gerencia de la empresa le gustaría saber cómo depende el tamaño de la anual del área de ventas de la tienda.
Tabla 2.1
|
Número de tienda |
Facturación anual, millones de rublos. |
Área comercial, mil m 2 |
Solución de mínimos cuadrados. Designemos: el volumen de negocios anual de la -ésima tienda, millones de rublos; - área de venta de la -ésima tienda, mil m 2.

Figura 2.1. Diagrama de dispersión para el ejemplo 2.1
Determinar la forma de la relación funcional entre las variables y construir un diagrama de dispersión (Fig. 2.1).
Con base en el diagrama de dispersión, podemos concluir que la facturación anual depende positivamente del área de venta (es decir, y aumentará con el crecimiento de ). La forma más apropiada de conexión funcional es: lineal.
La información para cálculos adicionales se presenta en la Tabla. 2.2. Usando el método de mínimos cuadrados, estimamos los parámetros del modelo econométrico lineal de un factor

Cuadro 2.2
De este modo,
Por lo tanto, con un aumento en el área comercial de 1 mil m 2, en igualdad de condiciones, la facturación anual promedio aumenta en 67,8871 millones de rublos.
Ejemplo 2.2. La gerencia de la empresa notó que la facturación anual depende no solo del área de ventas de la tienda (ver ejemplo 2.1), sino también del número promedio de visitantes. La información relevante se presenta en la tabla. 2.3.
Cuadro 2.3
Decisión. Denote: el número promedio de visitantes a la tienda por día, mil personas.
Determinar la forma de la relación funcional entre las variables y construir un diagrama de dispersión (Fig. 2.2).
Con base en el diagrama de dispersión, podemos concluir que la facturación anual está positivamente relacionada con el número promedio de visitantes por día (es decir, y aumentará con el crecimiento de ). La forma de dependencia funcional es lineal.

Arroz. 2.2. Diagrama de dispersión para el ejemplo 2.2
Cuadro 2.4
En general, es necesario determinar los parámetros del modelo econométrico de dos factores
y t \u003d un 0 + un 1 x 1 t + un 2 x 2 t + ε t
La información requerida para cálculos posteriores se presenta en la Tabla. 2.4.
Estimemos los parámetros de un modelo econométrico lineal de dos factores usando el método de mínimos cuadrados.

De este modo,
La evaluación del coeficiente = 61,6583 muestra que, en igualdad de condiciones, con un aumento en el área comercial de 1 mil m 2, la facturación anual aumentará en un promedio de 61,6583 millones de rublos.
(ver foto). Se requiere encontrar la ecuación de una recta
Cuanto menor sea el número en valor absoluto, mejor se elige la línea recta (2). Como característica de la precisión de la selección de una recta (2), podemos tomar la suma de cuadrados
Las condiciones mínimas para S serán
 |
(6) |
 |
(7) |
Las ecuaciones (6) y (7) se pueden escribir de la siguiente forma:
 |
(8) |
 |
(9) |
A partir de las ecuaciones (8) y (9) es fácil encontrar a y b a partir de los valores experimentales x i e y i . La línea (2) definida por las ecuaciones (8) y (9) se llama la línea obtenida por el método de los mínimos cuadrados (este nombre enfatiza que la suma de cuadrados S tiene un mínimo). Las ecuaciones (8) y (9), a partir de las cuales se determina la recta (2), se denominan ecuaciones normales.
Es posible indicar una forma simple y general de compilar ecuaciones normales. Usando los puntos experimentales (1) y la ecuación (2), podemos escribir el sistema de ecuaciones para a y b
| y 1 \u003d hacha 1 +b, | |||
| y 2 \u003dax 2 +b, ... |
(10) | ||
| yn=axn+b, | |||
Multiplicamos las partes izquierda y derecha de cada una de estas ecuaciones por el coeficiente en la primera incógnita a (es decir, x 1 , x 2 , ..., x n) y sumamos las ecuaciones resultantes, como resultado obtenemos la primera ecuación normal ( 8).
Multiplicamos los lados izquierdo y derecho de cada una de estas ecuaciones por el coeficiente de la segunda incógnita b, es decir por 1, y sume las ecuaciones resultantes, dando como resultado la segunda ecuación normal (9).
Este método de obtención de ecuaciones normales es general: es adecuado, por ejemplo, para la función
es un valor constante y debe determinarse a partir de datos experimentales (1).
El sistema de ecuaciones para k se puede escribir:
Encuentre la línea (2) usando el método de mínimos cuadrados.
Decisión. Encontramos:
x i = 21, y i = 46,3, x i 2 = 91, x i y i = 179,1.
Escribimos las ecuaciones (8) y (9)
A partir de aquí encontramos
Estimación de la precisión del método de mínimos cuadrados
Demos una estimación de la precisión del método para el caso lineal cuando se cumple la ecuación (2).
Deje que los valores experimentales x i sean exactos, y los valores experimentales y i tengan errores aleatorios con la misma varianza para todo i.
Introducimos la notación
| (16) |
Entonces las soluciones de las ecuaciones (8) y (9) se pueden representar como
| (17) | |
| (18) | |
| donde | |
| (19) | |
| De la ecuación (17) encontramos | |
| (20) | |
| De manera similar, de la ecuación (18) obtenemos | |
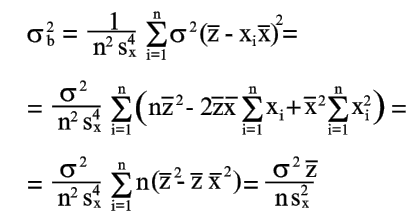 |
(21) |
| como | |
| (22) | |
| De las ecuaciones (21) y (22) encontramos | |
 |
(23) |
Las ecuaciones (20) y (23) dan una estimación de la precisión de los coeficientes determinados por las ecuaciones (8) y (9).
Tenga en cuenta que los coeficientes a y b están correlacionados. Por transformaciones simples, encontramos su momento de correlación.
A partir de aquí encontramos
0.072 en x=1 y 6,
0,041 en x=3,5.
Literatura
Orilla. Ya. B. Métodos estadísticos de análisis y control de calidad y confiabilidad. M.: Gosenergoizdat, 1962, p. 552, págs. 92-98.
Este libro está destinado a una amplia gama de ingenieros (institutos de investigación, oficinas de diseño, sitios de prueba y fábricas) involucrados en la determinación de la calidad y confiabilidad de equipos electrónicos y otros productos industriales masivos (construcción de maquinaria, fabricación de instrumentos, artillería, etc.).
El libro ofrece una aplicación de los métodos de las estadísticas matemáticas al procesamiento y evaluación de los resultados de las pruebas, en las que se determinan la calidad y la fiabilidad de los productos probados. Para comodidad de los lectores, se brinda la información necesaria de la estadística matemática, así como una gran cantidad de tablas matemáticas auxiliares que facilitan los cálculos necesarios.
La presentación se ilustra con una gran cantidad de ejemplos tomados del campo de la electrónica de radio y la tecnología de artillería.
Método de mínimos cuadrados
En la lección final del tema, nos familiarizaremos con la aplicación más famosa. FNP, que encuentra la aplicación más amplia en varios campos de la ciencia y la práctica. Puede ser física, química, biología, economía, sociología, psicología y así sucesivamente. Por voluntad del destino, a menudo tengo que lidiar con la economía y, por lo tanto, hoy organizaré para ti un boleto a un país increíble llamado Econometría=) … ¡¿Cómo no quieres eso?! Es muy bueno allí, ¡solo tienes que decidir! …Pero lo que probablemente quieras es aprender a resolver problemas mínimos cuadrados. Y los lectores especialmente diligentes aprenderán a resolverlos no solo con precisión, sino también MUY RÁPIDO ;-) Pero primero enunciado general del problema+ ejemplo relacionado:
Que se estudien indicadores en alguna materia que tengan una expresión cuantitativa. Al mismo tiempo, hay muchas razones para creer que el indicador depende del indicador. Esta suposición puede ser tanto una hipótesis científica como estar basada en el sentido común elemental. Sin embargo, dejemos la ciencia a un lado y exploremos áreas más apetitosas, a saber, las tiendas de comestibles. Denotamos por:
– espacio comercial de una tienda de abarrotes, m2,
- Volumen de negocios anual de una tienda de comestibles, millones de rublos.
Está bastante claro que cuanto mayor sea el área de la tienda, mayor será su facturación en la mayoría de los casos.
Supongamos que después de realizar observaciones/experimentos/cálculos/bailar con una pandereta, tenemos a nuestra disposición datos numéricos: 
Con las tiendas de abarrotes, creo que todo está claro: - esta es el área de la tienda 1, - su facturación anual, - el área de la tienda 2, - su facturación anual, etc. Por cierto, no es necesario tener acceso a materiales clasificados: se puede obtener una evaluación bastante precisa de la facturación utilizando estadísticas matemáticas. Sin embargo, no se distraigan, el curso de espionaje comercial ya está pagado =)
Los datos tabulares también se pueden escribir en forma de puntos y representar de la forma habitual para nosotros. sistema cartesiano .
Respondamos una pregunta importante: ¿Cuántos puntos se necesitan para un estudio cualitativo?
Cuanto más grande, mejor. El conjunto mínimo admisible consta de 5-6 puntos. Además, con una pequeña cantidad de datos, los resultados "anormales" no deben incluirse en la muestra. Entonces, por ejemplo, una pequeña tienda de élite puede ayudar mucho más que "sus colegas", distorsionando así el patrón general que debe encontrarse.
Si es bastante simple, tenemos que elegir una función, calendario que pasa lo más cerca posible de los puntos ![]() . Tal función se llama aproximando
(aproximación - aproximación) o función teórica
. En términos generales, aquí aparece inmediatamente un "pretendiente" obvio: un polinomio de alto grado, cuyo gráfico pasa por TODOS los puntos. Pero esta opción es complicada y, a menudo, simplemente incorrecta. (porque el gráfico "bobinará" todo el tiempo y reflejará mal la tendencia principal).
. Tal función se llama aproximando
(aproximación - aproximación) o función teórica
. En términos generales, aquí aparece inmediatamente un "pretendiente" obvio: un polinomio de alto grado, cuyo gráfico pasa por TODOS los puntos. Pero esta opción es complicada y, a menudo, simplemente incorrecta. (porque el gráfico "bobinará" todo el tiempo y reflejará mal la tendencia principal).
Así, la función deseada debe ser lo suficientemente simple y al mismo tiempo reflejar adecuadamente la dependencia. Como puede suponer, uno de los métodos para encontrar tales funciones se llama mínimos cuadrados. Primero, analicemos su esencia de manera general. Deje que alguna función aproxime los datos experimentales: 
¿Cómo evaluar la precisión de esta aproximación? Calculemos también las diferencias (desviaciones) entre los valores experimentales y funcionales (estudiamos el dibujo). El primer pensamiento que viene a la mente es estimar qué tan grande es la suma, pero el problema es que las diferencias pueden ser negativas. (por ejemplo, ![]() )
y las desviaciones como resultado de dicha suma se anularán entre sí. Por lo tanto, como una estimación de la precisión de la aproximación, se sugiere tomar la suma módulos desviaciones:
)
y las desviaciones como resultado de dicha suma se anularán entre sí. Por lo tanto, como una estimación de la precisión de la aproximación, se sugiere tomar la suma módulos desviaciones:
![]() o en forma plegada: (para los que no saben:
es el icono de suma, y
- variable auxiliar - "contador", que toma valores de 1 a
)
.
o en forma plegada: (para los que no saben:
es el icono de suma, y
- variable auxiliar - "contador", que toma valores de 1 a
)
.
Aproximando los puntos experimentales con diferentes funciones, obtendremos diferentes valores, y es obvio donde esta suma es menor, esa función es más precisa.
Tal método existe y se llama método de módulo mínimo. Sin embargo, en la práctica se ha generalizado mucho más. método de mínimos cuadrados, en el que los posibles valores negativos no se eliminan por el módulo, sino por el cuadrado de las desviaciones:
![]() , después de lo cual los esfuerzos se dirigen a la selección de una función tal que la suma de las desviaciones al cuadrado
, después de lo cual los esfuerzos se dirigen a la selección de una función tal que la suma de las desviaciones al cuadrado ![]() era lo más pequeño posible. En realidad, de ahí el nombre del método.
era lo más pequeño posible. En realidad, de ahí el nombre del método.
Y ahora volvemos a otro punto importante: como se señaló anteriormente, la función seleccionada debería ser bastante simple, pero también hay muchas funciones de este tipo: lineal , hiperbólico , exponencial , logarítmico , cuadrático etc. Y, por supuesto, aquí me gustaría inmediatamente "reducir el campo de actividad". ¿Qué clase de funciones elegir para la investigación? Técnica primitiva pero efectiva:
- La forma más fácil de dibujar puntos. ![]() en el dibujo y analizar su ubicación. Si tienden a estar en línea recta, entonces debe buscar ecuación de línea recta
en el dibujo y analizar su ubicación. Si tienden a estar en línea recta, entonces debe buscar ecuación de línea recta ![]() con valores óptimos y . En otras palabras, la tarea es encontrar TALES coeficientes, de modo que la suma de las desviaciones al cuadrado sea la más pequeña.
con valores óptimos y . En otras palabras, la tarea es encontrar TALES coeficientes, de modo que la suma de las desviaciones al cuadrado sea la más pequeña.
Si los puntos están ubicados, por ejemplo, a lo largo hipérbole, entonces está claro que la función lineal dará una mala aproximación. En este caso, buscamos los coeficientes más “favorables” para la ecuación de la hipérbola ![]() - los que dan la mínima suma de cuadrados
- los que dan la mínima suma de cuadrados  .
.
Ahora observe que en ambos casos estamos hablando de funciones de dos variables, cuyos argumentos son opciones de dependencia buscadas:
Y, en esencia, necesitamos resolver un problema estándar: encontrar mínimo de una función de dos variables.
Recuerde nuestro ejemplo: suponga que los puntos de "tienda" tienden a ubicarse en línea recta y hay muchas razones para creer que la presencia dependencia lineal facturación del área comercial. Encontremos TALES coeficientes "a" y "be" para que la suma de las desviaciones al cuadrado ![]() era el más pequeño. Todo como siempre - primero derivadas parciales de primer orden. De acuerdo a regla de linealidad puedes diferenciar justo debajo del ícono de suma:
era el más pequeño. Todo como siempre - primero derivadas parciales de primer orden. De acuerdo a regla de linealidad puedes diferenciar justo debajo del ícono de suma: 
Si desea utilizar esta información para un ensayo o un trabajo final, estaré muy agradecido por el enlace en la lista de fuentes, no encontrará cálculos tan detallados en ningún lado: 
Hagamos un sistema estándar: 
Reducimos cada ecuación por un “dos” y, además, “separamos” las sumas: 
Nota
: analice de forma independiente por qué "a" y "be" pueden eliminarse del icono de suma. Por cierto, formalmente esto se puede hacer con la suma ![]()
Reescribamos el sistema en una forma "aplicada": 
después de lo cual comienza a dibujarse el algoritmo para resolver nuestro problema:
¿Conocemos las coordenadas de los puntos? Sabemos. sumas ![]() podemos encontrar? Fácil. Componemos lo más simple sistema de dos ecuaciones lineales con dos incógnitas("a" y "beh"). Resolvemos el sistema, por ejemplo, método de Cramer, resultando en un punto estacionario . Comprobación condición suficiente para un extremo, podemos comprobar que en este punto la función
podemos encontrar? Fácil. Componemos lo más simple sistema de dos ecuaciones lineales con dos incógnitas("a" y "beh"). Resolvemos el sistema, por ejemplo, método de Cramer, resultando en un punto estacionario . Comprobación condición suficiente para un extremo, podemos comprobar que en este punto la función ![]() alcanza con precisión mínimo. La verificación está asociada con cálculos adicionales y, por lo tanto, la dejaremos atrás. (si es necesario, el marco que falta se puede veraquí
)
. Sacamos la conclusión final:
alcanza con precisión mínimo. La verificación está asociada con cálculos adicionales y, por lo tanto, la dejaremos atrás. (si es necesario, el marco que falta se puede veraquí
)
. Sacamos la conclusión final:
Función ![]() la mejor manera (al menos en comparación con cualquier otra función lineal) acerca los puntos experimentales
la mejor manera (al menos en comparación con cualquier otra función lineal) acerca los puntos experimentales ![]() . En términos generales, su gráfico pasa lo más cerca posible de estos puntos. en la tradición econometría la función de aproximación resultante también se llama ecuación de regresión lineal emparejada
.
. En términos generales, su gráfico pasa lo más cerca posible de estos puntos. en la tradición econometría la función de aproximación resultante también se llama ecuación de regresión lineal emparejada
.
El problema bajo consideración es de gran importancia práctica. En la situación con nuestro ejemplo, la ecuación ![]() le permite predecir qué tipo de facturación ("yig") estará en la tienda con uno u otro valor del área de venta (uno u otro significado de "x"). Sí, el pronóstico resultante será solo un pronóstico, pero en muchos casos resultará bastante preciso.
le permite predecir qué tipo de facturación ("yig") estará en la tienda con uno u otro valor del área de venta (uno u otro significado de "x"). Sí, el pronóstico resultante será solo un pronóstico, pero en muchos casos resultará bastante preciso.
Analizaré solo un problema con números "reales", ya que no presenta dificultades: todos los cálculos están al nivel del plan de estudios escolar en los grados 7-8. En el 95 por ciento de los casos, se le pedirá que encuentre solo una función lineal, pero al final del artículo mostraré que no es más difícil encontrar las ecuaciones para la hipérbola, el exponente y algunas otras funciones óptimas.
De hecho, queda por distribuir las golosinas prometidas, para que aprenda a resolver tales ejemplos no solo con precisión, sino también rápidamente. Estudiamos cuidadosamente el estándar:
Una tarea
Como resultado de estudiar la relación entre dos indicadores, se obtuvieron los siguientes pares de números: 
Usando el método de mínimos cuadrados, encuentre la función lineal que mejor se aproxime a la función empírica (experimentado) datos. Haz un dibujo en el que, en un sistema cartesiano de coordenadas rectangulares, trace puntos experimentales y una gráfica de la función de aproximación ![]() . Encuentre la suma de las desviaciones al cuadrado entre los valores empíricos y teóricos. Averigüe si la función es mejor (en términos del método de mínimos cuadrados) puntos experimentales aproximados.
. Encuentre la suma de las desviaciones al cuadrado entre los valores empíricos y teóricos. Averigüe si la función es mejor (en términos del método de mínimos cuadrados) puntos experimentales aproximados.
Tenga en cuenta que los valores de "x" son valores naturales, y esto tiene un significado significativo característico, del que hablaré un poco más adelante; pero, por supuesto, pueden ser fraccionarios. Además, según el contenido de una tarea en particular, tanto los valores "X" como "G" pueden ser total o parcialmente negativos. Pues nos han dado una tarea “sin rostro”, y la empezamos decisión:
Encontramos los coeficientes de la función óptima como solución al sistema: 
A los efectos de una notación más compacta, se puede omitir la variable “contador”, pues ya está claro que la sumatoria se realiza de 1 a .
Es más conveniente calcular las cantidades requeridas en forma tabular: 
Los cálculos se pueden realizar en una microcalculadora, pero es mucho mejor usar Excel, más rápido y sin errores; ver un video corto:
Así, obtenemos lo siguiente sistema:![]()
Aquí puedes multiplicar la segunda ecuación por 3 y restar la segunda de la primera ecuación término por término. Pero esto es suerte: en la práctica, los sistemas a menudo no están dotados y, en tales casos, ahorra método de Cramer:
, por lo que el sistema tiene solución única.

Hagamos una comprobación. Entiendo que no quiero hacerlo, pero ¿por qué omitir errores donde absolutamente no puedes pasarlos por alto? Sustituye la solución encontrada en el lado izquierdo de cada ecuación del sistema:
Se obtienen las partes correctas de las ecuaciones correspondientes, lo que significa que el sistema se resuelve correctamente.
Así, la función de aproximación deseada: – de todas las funciones lineales los datos experimentales se aproximan mejor con él.
A diferencia de derecho
dependencia de la facturación de la tienda en su área, la dependencia encontrada es contrarrestar
(principio "cuanto más - menos"), y este hecho es inmediatamente revelado por la negativa coeficiente angular. Función ![]() nos informa que con un aumento en un determinado indicador en 1 unidad, el valor del indicador dependiente disminuye promedio por 0,65 unidades. Como dicen, cuanto más alto es el precio del trigo sarraceno, menos se vende.
nos informa que con un aumento en un determinado indicador en 1 unidad, el valor del indicador dependiente disminuye promedio por 0,65 unidades. Como dicen, cuanto más alto es el precio del trigo sarraceno, menos se vende.
Para graficar la función de aproximación, encontramos dos de sus valores:
y ejecutar el dibujo: 
La recta construida se llama línea de tendencia
(es decir, una línea de tendencia lineal, es decir, en el caso general, una tendencia no es necesariamente una línea recta). Todo el mundo está familiarizado con la expresión "to be in trend", y creo que este término no necesita comentarios adicionales.
Calcular la suma de las desviaciones al cuadrado ![]() entre valores empíricos y teóricos. Geométricamente, esta es la suma de los cuadrados de las longitudes de los segmentos "carmesí" (dos de los cuales son tan pequeños que ni siquiera puedes verlos).
entre valores empíricos y teóricos. Geométricamente, esta es la suma de los cuadrados de las longitudes de los segmentos "carmesí" (dos de los cuales son tan pequeños que ni siquiera puedes verlos).
Resumamos los cálculos en una tabla: 
Se pueden volver a realizar manualmente, por si acaso daré un ejemplo para el 1er punto: ![]()
pero es mucho más eficiente hacerlo de la forma ya conocida:
Repitamos: ¿Cuál es el significado del resultado? De todas las funciones lineales función ![]() el exponente es el más pequeño, es decir, es la mejor aproximación de su familia. Y aquí, por cierto, la pregunta final del problema no es casual: ¿y si la función exponencial propuesta
el exponente es el más pequeño, es decir, es la mejor aproximación de su familia. Y aquí, por cierto, la pregunta final del problema no es casual: ¿y si la función exponencial propuesta ![]() ¿Será mejor aproximar los puntos experimentales?
¿Será mejor aproximar los puntos experimentales?
Encontremos la suma correspondiente de las desviaciones al cuadrado; para distinguirlas, las designaré con la letra "épsilon". La técnica es exactamente la misma: 
Y nuevamente para cada cálculo de fuego para el 1er punto: 
En Excel, usamos la función estándar Exp (La sintaxis se puede encontrar en la Ayuda de Excel).
Conclusión: , por lo que la función exponencial aproxima peor los puntos experimentales que la recta ![]() .
.
Pero cabe señalar aquí que "peor" es no significa todavía, lo que está mal. Ahora construí un gráfico de esta función exponencial - y también pasa cerca de los puntos ![]() - tanto es así que sin un estudio analítico es difícil decir qué función es más precisa.
- tanto es así que sin un estudio analítico es difícil decir qué función es más precisa.
Esto completa la solución, y vuelvo a la cuestión de los valores naturales del argumento. En varios estudios, por regla general, económicos o sociológicos, los meses, años u otros intervalos de tiempo iguales se numeran con "X" natural. Considere, por ejemplo, el siguiente problema:
Disponemos de los siguientes datos sobre la facturación minorista de la tienda para el primer semestre del año:
Utilizando la alineación analítica de línea recta, encuentre el volumen de ventas de julio.
Sí, no hay problema: numeramos los meses 1, 2, 3, 4, 5, 6 y usamos el algoritmo habitual, como resultado de lo cual obtenemos una ecuación: lo único cuando se trata de tiempo suele ser la letra "te " (aunque no es crítico). La ecuación resultante muestra que en la primera mitad del año, la rotación aumentó en un promedio de 27,74 u.m. por mes. Obtener un pronóstico para julio (mes #7): UE.
Y tareas similares: la oscuridad es oscura. Aquellos que lo deseen pueden utilizar un servicio adicional, a saber, mi calculadora excel (Versión de demostración), cual resuelve el problema casi al instante! La versión de trabajo del programa está disponible. a cambio o por pago simbólico.
Al final de la lección, una breve información sobre cómo encontrar dependencias de algunos otros tipos. En realidad, no hay nada especial que contar, ya que el enfoque fundamental y el algoritmo de solución siguen siendo los mismos.
Supongamos que la ubicación de los puntos experimentales se parece a una hipérbola. Luego, para encontrar los coeficientes de la mejor hipérbola, debe encontrar el mínimo de la función; aquellos que lo deseen pueden realizar cálculos detallados y llegar a un sistema similar: 
Desde un punto de vista técnico formal, se obtiene del sistema "lineal"  (vamos a marcarlo con un asterisco) reemplazando "x" con . Bueno, las cantidades
(vamos a marcarlo con un asterisco) reemplazando "x" con . Bueno, las cantidades ![]() calcular, después de lo cual a los coeficientes óptimos "a" y "be" a mano.
calcular, después de lo cual a los coeficientes óptimos "a" y "be" a mano.
Si hay todas las razones para creer que los puntos ![]() están dispuestos a lo largo de una curva logarítmica, luego para buscar los valores óptimos y encontrar el mínimo de la función
están dispuestos a lo largo de una curva logarítmica, luego para buscar los valores óptimos y encontrar el mínimo de la función ![]() . Formalmente, en el sistema (*) debe sustituirse por:
. Formalmente, en el sistema (*) debe sustituirse por: 
Al calcular en Excel, use la función LN. Confieso que no me será difícil crear calculadoras para cada uno de los casos que se están considerando, pero aún así será mejor si "programa" los cálculos usted mismo. Tutoriales en video para ayudar.
Con dependencia exponencial, la situación es un poco más complicada. Para reducir el asunto al caso lineal, tomamos el logaritmo de la función y usamos propiedades del logaritmo:
Ahora, comparando la función obtenida con la función lineal , llegamos a la conclusión de que en el sistema (*) se debe reemplazar por , y - por . Por conveniencia, denotamos: 
Tenga en cuenta que el sistema se resuelve con respecto a y , y por lo tanto, después de encontrar las raíces, no debe olvidar encontrar el coeficiente en sí.
Para aproximar puntos experimentales ![]() parábola óptima
parábola óptima ![]() , debe ser encontrado mínimo de una función de tres variables
, debe ser encontrado mínimo de una función de tres variables ![]() . Después de realizar acciones estándar, obtenemos el siguiente "funcionamiento" sistema:
. Después de realizar acciones estándar, obtenemos el siguiente "funcionamiento" sistema:
Sí, por supuesto, aquí hay más cantidades, pero no hay ninguna dificultad al usar su aplicación favorita. Y finalmente, le diré cómo verificar rápidamente usando Excel y construir la línea de tendencia deseada: cree un gráfico de dispersión, seleccione cualquiera de los puntos con el mouse ![]() y haga clic derecho en la opción de selección "Añadir línea de tendencia". A continuación, seleccione el tipo de gráfico y en la pestaña "Opciones" activar la opción "Mostrar ecuación en el gráfico". OK
y haga clic derecho en la opción de selección "Añadir línea de tendencia". A continuación, seleccione el tipo de gráfico y en la pestaña "Opciones" activar la opción "Mostrar ecuación en el gráfico". OK
Como siempre, quiero terminar el artículo con una frase hermosa, y casi escribo “¡Estar en tendencia!”. Pero con el tiempo cambió de opinión. Y no porque sea una fórmula. No sé cómo alguien, pero no quiero seguir la tendencia estadounidense y especialmente europea promovida en absoluto =) ¡Por lo tanto, deseo que cada uno de ustedes se ciña a su propia línea!
http://www.grandars.ru/student/vysshaya-matematika/metod-naimenshih-kvadratov.html
El método de los mínimos cuadrados es uno de los más comunes y desarrollados debido a su simplicidad y eficiencia de los métodos para estimar los parámetros de los modelos econométricos lineales. Al mismo tiempo, se debe tener cierta precaución al usarlo, ya que los modelos construidos con él pueden no cumplir con una serie de requisitos para la calidad de sus parámetros y, como resultado, no reflejan "bien" los patrones de desarrollo del proceso.
Consideremos con más detalle el procedimiento para estimar los parámetros de un modelo econométrico lineal utilizando el método de mínimos cuadrados. Tal modelo en forma general se puede representar mediante la ecuación (1.2):
y t = un 0 + un 1 X 1t +...+ un norte X nt + ε t .
El dato inicial al estimar los parámetros a 0 , a 1 ,..., an es el vector de valores de la variable dependiente y= (y 1 , y 2 , ... , y T)" y la matriz de valores de las variables independientes

en la que la primera columna, formada por unos, corresponde al coeficiente del modelo.
El método de los mínimos cuadrados obtuvo su nombre basado en el principio básico de que las estimaciones de los parámetros obtenidas sobre su base deben satisfacer: la suma de los cuadrados del error del modelo debe ser mínima.
Ejemplos de resolución de problemas por el método de mínimos cuadrados
Ejemplo 2.1. La empresa comercial tiene una red que consta de 12 tiendas, cuya información sobre las actividades se presenta en la Tabla. 2.1.
A la gerencia de la empresa le gustaría saber cómo depende el tamaño de la facturación anual del espacio comercial de la tienda.
Tabla 2.1
| Número de tienda | Facturación anual, millones de rublos. | Área comercial, mil m 2 |
| 19,76 | 0,24 | |
| 38,09 | 0,31 | |
| 40,95 | 0,55 | |
| 41,08 | 0,48 | |
| 56,29 | 0,78 | |
| 68,51 | 0,98 | |
| 75,01 | 0,94 | |
| 89,05 | 1,21 | |
| 91,13 | 1,29 | |
| 91,26 | 1,12 | |
| 99,84 | 1,29 | |
| 108,55 | 1,49 |
Solución de mínimos cuadrados. Designemos: el volumen de negocios anual de la -ésima tienda, millones de rublos; - área de venta de la décima tienda, mil m 2.

Figura 2.1. Diagrama de dispersión para el ejemplo 2.1
Determinar la forma de la relación funcional entre las variables y construir un diagrama de dispersión (Fig. 2.1).
Con base en el diagrama de dispersión, podemos concluir que la facturación anual depende positivamente del área de venta (es decir, y aumentará con el crecimiento de ). La forma más apropiada de conexión funcional es lineal.
La información para cálculos adicionales se presenta en la Tabla. 2.2. Usando el método de mínimos cuadrados, estimamos los parámetros del modelo econométrico lineal de un factor

Cuadro 2.2
| t | yt | x 1 t | y t 2 | x1t2 | x 1t y t |
| 19,76 | 0,24 | 390,4576 | 0,0576 | 4,7424 | |
| 38,09 | 0,31 | 1450,8481 | 0,0961 | 11,8079 | |
| 40,95 | 0,55 | 1676,9025 | 0,3025 | 22,5225 | |
| 41,08 | 0,48 | 1687,5664 | 0,2304 | 19,7184 | |
| 56,29 | 0,78 | 3168,5641 | 0,6084 | 43,9062 | |
| 68,51 | 0,98 | 4693,6201 | 0,9604 | 67,1398 | |
| 75,01 | 0,94 | 5626,5001 | 0,8836 | 70,5094 | |
| 89,05 | 1,21 | 7929,9025 | 1,4641 | 107,7505 | |
| 91,13 | 1,29 | 8304,6769 | 1,6641 | 117,5577 | |
| 91,26 | 1,12 | 8328,3876 | 1,2544 | 102,2112 | |
| 99,84 | 1,29 | 9968,0256 | 1,6641 | 128,7936 | |
| 108,55 | 1,49 | 11783,1025 | 2,2201 | 161,7395 | |
| S | 819,52 | 10,68 | 65008,554 | 11,4058 | 858,3991 |
| Promedio | 68,29 | 0,89 |
De este modo,
Por lo tanto, con un aumento en el área comercial de 1 mil m 2, en igualdad de condiciones, la facturación anual promedio aumenta en 67,8871 millones de rublos.
Ejemplo 2.2. La gerencia de la empresa notó que la facturación anual depende no solo del área de ventas de la tienda (ver ejemplo 2.1), sino también del número promedio de visitantes. La información relevante se presenta en la tabla. 2.3.
Cuadro 2.3
Decisión. Denote: el número promedio de visitantes a la tienda por día, mil personas.
Determinar la forma de la relación funcional entre las variables y construir un diagrama de dispersión (Fig. 2.2).
Con base en el diagrama de dispersión, podemos concluir que la facturación anual está positivamente relacionada con el número promedio de visitantes por día (es decir, y aumentará con el crecimiento de ). La forma de dependencia funcional es lineal.

Arroz. 2.2. Diagrama de dispersión para el ejemplo 2.2
Cuadro 2.4
| t | x 2t | x 2t 2 | yt x 2t | x 1 t x 2 t |
| 8,25 | 68,0625 | 163,02 | 1,98 | |
| 10,24 | 104,8575 | 390,0416 | 3,1744 | |
| 9,31 | 86,6761 | 381,2445 | 5,1205 | |
| 11,01 | 121,2201 | 452,2908 | 5,2848 | |
| 8,54 | 72,9316 | 480,7166 | 6,6612 | |
| 7,51 | 56,4001 | 514,5101 | 7,3598 | |
| 12,36 | 152,7696 | 927,1236 | 11,6184 | |
| 10,81 | 116,8561 | 962,6305 | 13,0801 | |
| 9,89 | 97,8121 | 901,2757 | 12,7581 | |
| 13,72 | 188,2384 | 1252,0872 | 15,3664 | |
| 12,27 | 150,5529 | 1225,0368 | 15,8283 | |
| 13,92 | 193,7664 | 1511,016 | 20,7408 | |
| S | 127,83 | 1410,44 | 9160,9934 | 118,9728 |
| Promedio | 10,65 |
En general, es necesario determinar los parámetros del modelo econométrico de dos factores
y t \u003d un 0 + un 1 x 1t + un 2 x 2t + ε t
La información requerida para cálculos posteriores se presenta en la Tabla. 2.4.
Estimemos los parámetros de un modelo econométrico lineal de dos factores usando el método de mínimos cuadrados.

De este modo,
La evaluación del coeficiente = 61,6583 muestra que, en igualdad de condiciones, con un aumento en el área comercial de 1 mil m 2, la facturación anual aumentará en un promedio de 61,6583 millones de rublos.
La estimación del coeficiente = 2.2748 muestra que, en igualdad de condiciones, con un aumento en el número promedio de visitantes por 1 mil personas. por día, la facturación anual aumentará en un promedio de 2,2748 millones de rublos.
Ejemplo 2.3. Utilizando la información presentada en la tabla. 2.2 y 2.4, estimar el parámetro de un modelo econométrico de un solo factor
![]()
donde está el valor centrado de la facturación anual de la -ésima tienda, millones de rublos; - valor centrado del promedio diario de visitantes a la tienda t-ésima, mil personas. (ver ejemplos 2.1-2.2).
Decisión. La información adicional requerida para los cálculos se presenta en la Tabla. 2.5.
Cuadro 2.5
| -48,53 | -2,40 | 5,7720 | 116,6013 | |
| -30,20 | -0,41 | 0,1702 | 12,4589 | |
| -27,34 | -1,34 | 1,8023 | 36,7084 | |
| -27,21 | 0,36 | 0,1278 | -9,7288 | |
| -12,00 | -2,11 | 4,4627 | 25,3570 | |
| 0,22 | -3,14 | 9,8753 | -0,6809 | |
| 6,72 | 1,71 | 2,9156 | 11,4687 | |
| 20,76 | 0,16 | 0,0348 | 3,2992 | |
| 22,84 | -0,76 | 0,5814 | -17,413 | |
| 22,97 | 3,07 | 9,4096 | 70,4503 | |
| 31,55 | 1,62 | 2,6163 | 51,0267 | |
| 40,26 | 3,27 | 10,6766 | 131,5387 | |
| Suma | 48,4344 | 431,0566 |
Usando la fórmula (2.35), obtenemos

De este modo,
![]()
http://www.cleverstudents.ru/articles/mnk.html
Ejemplo.
Datos experimentales sobre los valores de las variables. X y a se dan en la tabla. 
Como resultado de su alineación, la función ![]()
Usando método de mínimos cuadrados, aproximar estos datos con una dependencia lineal y=ax+b(buscar parámetros a y b). Averigüe cuál de las dos líneas es mejor (en el sentido del método de mínimos cuadrados) alinea los datos experimentales. Haz un dibujo.
Decisión.
En nuestro ejemplo n=5. Completamos la tabla por conveniencia de calcular las cantidades que se incluyen en las fórmulas de los coeficientes requeridos. 
Los valores de la cuarta fila de la tabla se obtienen multiplicando los valores de la 2ª fila por los valores de la 3ª fila para cada número i.
Los valores de la quinta fila de la tabla se obtienen elevando al cuadrado los valores de la 2da fila para cada número i.
Los valores de la última columna de la tabla son las sumas de los valores de las filas.
Usamos las fórmulas del método de los mínimos cuadrados para encontrar los coeficientes a y b. Sustituimos en ellos los valores correspondientes de la última columna de la tabla: 
Como consecuencia, y=0.165x+2.184 es la línea recta de aproximación deseada.
Queda por saber cuál de las líneas y=0.165x+2.184 o ![]() aproxima mejor a los datos originales, es decir, hacer una estimación usando el método de mínimos cuadrados.
aproxima mejor a los datos originales, es decir, hacer una estimación usando el método de mínimos cuadrados.
Prueba.
para que cuando se encuentre a y b función toma el valor más pequeño, es necesario que en este punto la matriz de la forma cuadrática del diferencial de segundo orden para la función ![]() fue definida positiva. Mostrémoslo.
fue definida positiva. Mostrémoslo.
La diferencial de segundo orden tiene la forma: 
Es decir
Por lo tanto, la matriz de la forma cuadrática tiene la forma 
y los valores de los elementos no dependen de a y b.
Demostremos que la matriz es definida positiva. Esto requiere que los ángulos menores sean positivos.
Angular menor de primer orden  . La desigualdad es estricta, ya que los puntos
. La desigualdad es estricta, ya que los puntos