
Fonction linéaire des moindres carrés. Approximation d'une fonction par la méthode des moindres carrés. Une brève théorie des moindres carrés pour la dépendance linéaire
Méthode des moindres carrés (OLS, ing. Ordinary Least Squares, OLS)- une méthode mathématique utilisée pour résoudre divers problèmes, basée sur la minimisation de la somme des écarts au carré de certaines fonctions par rapport aux variables souhaitées. Il peut être utilisé pour "résoudre" des systèmes d'équations surdéterminés (lorsque le nombre d'équations dépasse le nombre d'inconnues), pour trouver une solution dans le cas de systèmes d'équations non linéaires ordinaires (non surdéterminés), pour approximer les valeurs ponctuelles d'une certaine fonction. L'OLS est l'une des méthodes de base de l'analyse de régression pour estimer les paramètres inconnus des modèles de régression à partir de données d'échantillon.
YouTube encyclopédique
1 / 5
✪ Méthode des moindres carrés. Thème
✪ Moindres carrés, leçon 1/2. Fonction linéaire
✪ Économétrie. Cours 5. Méthode des moindres carrés
✪ Mitin I. V. - Traitement des résultats de physique. expérience - Méthode des moindres carrés (Lecture 4)
✪ Économétrie : L'essentiel de la méthode des moindres carrés #2
Les sous-titres
L'histoire
Jusqu'au début du XIXème siècle. les scientifiques n'avaient pas certaines règles pour résoudre un système d'équations dans lequel le nombre d'inconnues est inférieur au nombre d'équations; Jusqu'à cette époque, des méthodes particulières étaient utilisées, en fonction du type d'équations et de l'ingéniosité des calculateurs, et donc différents calculateurs, partant des mêmes données d'observation, arrivaient à des conclusions différentes. Gauss (1795) est crédité de la première application de la méthode, et Legendre (1805) la découvrit et la publia indépendamment sous son nom moderne (fr. Méthode des moindres carrés). Laplace a relié la méthode à la théorie des probabilités et le mathématicien américain Adrain (1808) a considéré ses applications probabilistes. La méthode est répandue et améliorée par d'autres recherches par Encke, Bessel, Hansen et d'autres.
L'essence de la méthode des moindres carrés
Laisser être x (\displaystyle x)- trousse n (\displaystyle n) variables inconnues (paramètres), f je (x) (\displaystyle f_(i)(x)), , m > n (\displaystyle m>n)- ensemble de fonctions à partir de cet ensemble de variables. Le problème est de choisir de telles valeurs x (\displaystyle x) pour que les valeurs de ces fonctions soient aussi proches que possible de certaines valeurs y je (\displaystyle y_(i)). Essentiellement, nous parlons de la "solution" du système d'équations surdéterminé f je (x) = y je (\displaystyle f_(i)(x)=y_(i)), je = 1 , … , m (\displaystyle i=1,\ldots ,m) dans le sens indiqué, la proximité maximale des parties gauche et droite du système. L'essence de LSM est de choisir comme "mesure de proximité" la somme des écarts au carré des parties gauche et droite | f je (x) - y je | (\displaystyle |f_(i)(x)-y_(i)|). Ainsi, l'essence du LSM peut être exprimée comme suit :
∑ je e je 2 = ∑ je (y je - F je (x)) 2 → min X (\displaystyle \sum _(i)e_(i)^(2)=\sum _(i)(y_(i)-f_( i)(x))^(2)\flèchedroite\min _(x)).Si le système d'équations a une solution, alors le minimum de la somme des carrés sera égal à zéro et des solutions exactes du système d'équations peuvent être trouvées analytiquement ou, par exemple, par diverses méthodes d'optimisation numérique. Si le système est surdéterminé, c'est-à-dire, en gros, que le nombre d'équations indépendantes est supérieur au nombre de variables inconnues, alors le système n'a pas de solution exacte et la méthode des moindres carrés nous permet de trouver un vecteur "optimal" x (\displaystyle x) au sens de la proximité maximale des vecteurs y (\displaystyle y) et f (x) (\displaystyle f(x)) soit la proximité maximale du vecteur déviation e (\displaystyle e)à zéro (la proximité s'entend au sens de distance euclidienne).
Exemple - système d'équations linéaires
En particulier, la méthode des moindres carrés peut être utilisée pour "résoudre" le système d'équations linéaires
UNE x = b (\displaystyle Ax=b),où A (\displaystyle A) matrice de taille rectangulaire m × n , m > n (\displaystyle m\times n,m>n)(c'est-à-dire que le nombre de lignes de la matrice A est supérieur au nombre de variables requises).
Un tel système d'équations n'a généralement pas de solution. Par conséquent, ce système ne peut être "résolu" que dans le sens de choisir un tel vecteur x (\displaystyle x) pour minimiser la "distance" entre les vecteurs UNE x (\displaystyle Axe) et b (\ displaystyle b). Pour ce faire, vous pouvez appliquer le critère de minimisation de la somme des différences au carré des parties gauche et droite des équations du système, c'est-à-dire (A X - b) T (A X - b) → min X (\displaystyle (Ax-b)^(T)(Ax-b)\rightarrow \min _(x)). Il est facile de montrer que la solution de ce problème de minimisation conduit à la solution du système d'équations suivant
UNE T UNE X = UNE T b ⇒ X = (UNE TA) - 1 UNE T b (\displaystyle A^(T)Ax=A^(T)b\Rightarrow x=(A^(T)A)^(-1)A^ (V)b).OLS dans l'analyse de régression (approximation des données)
Qu'il y ait n (\displaystyle n) valeurs de certaines variables y (\displaystyle y)(cela peut être le résultat d'observations, d'expériences, etc.) et les variables correspondantes x (\displaystyle x). Le défi est de faire le lien entre y (\displaystyle y) et x (\displaystyle x) approché par une fonction connue à quelques paramètres inconnus près b (\ displaystyle b), c'est-à-dire trouver réellement les meilleures valeurs des paramètres b (\ displaystyle b), se rapprochant au maximum des valeurs f (x , b) (\displaystyle f(x,b)) aux valeurs réelles y (\displaystyle y). En fait, cela se ramène au cas de "solution" d'un système d'équations surdéterminé par rapport à b (\ displaystyle b):
F (x t , b) = y t , t = 1 , … , n (\displaystyle f(x_(t),b)=y_(t),t=1,\ldots ,n).
En analyse de régression, et en particulier en économétrie, des modèles probabilistes de la relation entre les variables sont utilisés.
Oui t = f (x t , b) + ε t (\displaystyle y_(t)=f(x_(t),b)+\varepsilon _(t)),
où ε t (\displaystyle \varepsilon _(t))- soi-disant erreurs aléatoires des modèles.
En conséquence, les écarts des valeurs observées y (\displaystyle y) du modèle f (x , b) (\displaystyle f(x,b)) déjà pris en compte dans le modèle lui-même. L'essence de LSM (ordinaire, classique) est de trouver de tels paramètres b (\ displaystyle b), à laquelle la somme des écarts au carré (erreurs, pour les modèles de régression, elles sont souvent appelées résidus de régression) e t (\displaystyle e_(t)) sera minime :
b ^ O L S = arg min b R S S (b) (\displaystyle (\hat (b))_(OLS)=\arg \min _(b)RSS(b)),où R S S (\displaystyle RSS)- Anglais. La somme résiduelle des carrés est définie comme suit :
R S S (b) = e T e = ∑ t = 1 n e t 2 = ∑ t = 1 n (y t - F (x t , b)) 2 (\displaystyle RSS(b)=e^(T)e=\sum _ (t=1)^(n)e_(t)^(2)=\somme _(t=1)^(n)(y_(t)-f(x_(t),b))^(2) ).Dans le cas général, ce problème peut être résolu par des méthodes numériques d'optimisation (minimisation). Dans ce cas, on parle de moindres carrés non linéaires(NLS ou NLLS - eng. Moindres carrés non linéaires). Dans de nombreux cas, une solution analytique peut être obtenue. Pour résoudre le problème de minimisation, il faut trouver les points stationnaires de la fonction R S S (b) (\displaystyle RSS(b)), en le différenciant par rapport à des paramètres inconnus b (\ displaystyle b), assimilant les dérivées à zéro et résolvant le système d'équations résultant :
∑ t = 1 n (y t - F (x t , b)) ∂ F (x t , b) ∂ b = 0 (\displaystyle \sum _(t=1)^(n)(y_(t)-f(x_ (t),b))(\frac (\partial f(x_(t),b))(\partial b))=0).LSM dans le cas de la régression linéaire
Soit la dépendance de la régression linéaire :
y t = ∑ j = 1 k b j X t j + ε = X t T b + ε t (\displaystyle y_(t)=\sum _(j=1)^(k)b_(j)x_(tj)+\varepsilon =x_( t)^(T)b+\varepsilon _(t)).Laisser être y est le vecteur colonne des observations de la variable expliquée, et X (\displaystyle X)- il (n × k) (\displaystyle ((n\fois k)))- matrice d'observations de facteurs (lignes de la matrice - vecteurs de valeurs de facteurs dans une observation donnée, par colonnes - vecteur de valeurs d'un facteur donné dans toutes les observations). La représentation matricielle du modèle linéaire a la forme :
y = Xb + ε (\displaystyle y=Xb+\varepsilon ).Alors le vecteur des estimations de la variable expliquée et le vecteur des résidus de régression seront égaux à
y ^ = X b , e = y − y ^ = y − X b (\displaystyle (\hat (y))=Xb,\quad e=y-(\hat (y))=y-Xb).en conséquence, la somme des carrés des résidus de régression sera égale à
R S S = e T e = (y − X b) T (y − X b) (\displaystyle RSS=e^(T)e=(y-Xb)^(T)(y-Xb)).Différenciation de cette fonction par rapport au vecteur paramètre b (\ displaystyle b) et en assimilant les dérivées à zéro, on obtient un système d'équations (sous forme matricielle) :
(X T X) b = X T y (\displaystyle (X^(T)X)b=X^(T)y).Sous la forme matricielle déchiffrée, ce système d'équations ressemble à ceci :
(∑ x t 1 2 ∑ x t 1 x t 2 ∑ x t 1 x t 3 … ∑ x t 1 x t k ∑ x t 2 x t 1 ∑ x t 2 2 ∑ x t 2 x t 3 … ∑ x t 2 x t k ∑ x t 3 x t 1 x ∑ x t ∑ X t 3 X t k ⋮ ⋮ ⋮ ⋱ ⋮ ∑ X t k X t 1 ∑ X t k X t 2 ∑ X t k X t 3 … ∑ X t k 2) (b 1 b 2 b 3 ⋮ b k) = (∑ X t 1 y x k t ∑ 3 y ∋ t (\begin(pmatrix)\sum x_(t1)^(2)&\sum x_(t1)x_(t2)&\sum x_(t1)x_(t3)&\ldots &\sum x_(t1)x_( tk)\\\somme x_(t2)x_(t1)&\somme x_(t2)^(2)&\somme x_(t2)x_(t3)&\ldots &\ somme x_(t2)x_(tk) \\\somme x_(t3)x_(t1)&\somme x_(t3)x_(t2)&\somme x_(t3)^(2)&\ldots &\somme x_ (t3)x_(tk)\\ \vdots &\vdots &\vdots &\ddots &\vdots \\\sum x_(tk)x_(t1)&\sum x_(tk)x_(t2)&\sum x_ (tk)x_(t3)&\ ldots &\sum x_(tk)^(2)\\\end(pmatrix))(\begin(pmatrix)b_(1)\\b_(2)\\b_(3 )\\\vdots \\b_( k)\\\end(pmatrix))=(\begin(pmatrix)\sum x_(t1)y_(t)\\\sum x_(t2)y_(t)\\ \sum x_(t3)y_(t )\\\vpoints \\\somme x_(tk)y_(t)\\\end(pmatrix))) où toutes les sommes sont prises sur toutes les valeurs admissibles t (\displaystyle t).
Si une constante est incluse dans le modèle (comme d'habitude), alors x t 1 = 1 (\displaystyle x_(t1)=1) pour tous t (\displaystyle t), donc, dans le coin supérieur gauche de la matrice du système d'équations se trouve le nombre d'observations n (\displaystyle n), et dans les éléments restants de la première ligne et de la première colonne - juste la somme des valeurs des variables : ∑ X t j (\displaystyle\sum x_(tj)) et le premier élément du côté droit du système - ∑ y t (\displaystyle\sum y_(t)).
La solution de ce système d'équations donne la formule générale des estimations des moindres carrés pour le modèle linéaire :
b ^ O L S = (X T X) − 1 X T y = (1 n X T X) − 1 1 n X T y = V X − 1 C X y (\displaystyle (\hat (b))_(OLS)=(X^(T )X)^(-1)X^(T)y=\left((\frac (1)(n))X^(T)X\right)^(-1)(\frac (1)(n ))X^(T)y=V_(x)^(-1)C_(xy)).À des fins analytiques, la dernière représentation de cette formule s'avère utile (dans le système d'équations lorsqu'il est divisé par n, les moyennes arithmétiques apparaissent à la place des sommes). Si les données du modèle de régression centré, alors dans cette représentation la première matrice a la signification de la matrice de covariance des facteurs de l'échantillon, et la seconde est le vecteur des covariances des facteurs avec variable dépendante. Si, en plus, les données sont également normalisé au SKO (c'est-à-dire, finalement standardisé), alors la première matrice a la signification de la matrice de corrélation d'échantillons de facteurs, le second vecteur - le vecteur de corrélations d'échantillons de facteurs avec la variable dépendante.
Une propriété importante des estimations LLS pour les modèles avec une constante- la ligne de régression construite passe par le centre de gravité des données de l'échantillon, c'est-à-dire que l'égalité est satisfaite :
y ¯ = b 1 ^ + ∑ j = 2 k b ^ j X ¯ j (\displaystyle (\bar (y))=(\hat (b_(1)))+\sum _(j=2)^(k) (\hat (b))_(j)(\bar (x))_(j)).En particulier, dans le cas extrême, lorsque le seul régresseur est une constante, nous constatons que l'estimation MCO d'un seul paramètre (la constante elle-même) est égale à la valeur moyenne de la variable expliquée. Autrement dit, la moyenne arithmétique, connue pour ses bonnes propriétés d'après les lois des grands nombres, est également une estimation des moindres carrés - elle satisfait le critère de la somme minimale des écarts au carré par rapport à celle-ci.
Les cas particuliers les plus simples
Dans le cas de la régression linéaire par paires y t = une + b X t + ε t (\displaystyle y_(t)=a+bx_(t)+\varepsilon _(t)), lorsque la dépendance linéaire d'une variable à une autre est estimée, les formules de calcul sont simplifiées (vous pouvez vous passer de l'algèbre matricielle). Le système d'équations a la forme :
(1 x ¯ x ¯ x 2 ¯) (a b) = (y ¯ x y ¯) (\displaystyle (\begin(pmatrix)1&(\bar (x))\\(\bar (x))&(\bar (x^(2)))\\\end(pmatrix))(\begin(pmatrix)a\\b\\\end(pmatrix))=(\begin(pmatrix)(\bar (y))\\ (\overline(xy))\\\end(pmatrix))).À partir de là, il est facile de trouver des estimations pour les coefficients :
( b ^ = Cov (x , y) Var (x) = x y ¯ − x ¯ y ¯ x 2 ¯ − x ¯ 2 , une ^ = y ¯ − b X ¯ . (\displaystyle (\begin(cases) (\hat (b))=(\frac (\mathop (\textrm (Cov)) (x,y))(\mathop (\textrm (Var)) (x)))=(\frac ((\overline (xy))-(\bar (x))(\bar (y)))((\overline (x^(2)))-(\overline (x))^(2))),\\( \hat (a))=(\bar (y))-b(\bar (x)).\end(cases)))Malgré le fait qu'en général, les modèles avec une constante sont préférables, dans certains cas, il est connu à partir de considérations théoriques que la constante un (\displaystyle un) doit être égal à zéro. Par exemple, en physique, la relation entre la tension et le courant a la forme U = je ⋅ R (\displaystyle U=I\cdot R); mesurant la tension et le courant, il est nécessaire d'estimer la résistance. Dans ce cas, on parle d'un modèle y = b X (\displaystyle y=bx). Dans ce cas, au lieu d'un système d'équations, nous avons une seule équation
(∑ X t 2) b = ∑ X t y t (\displaystyle \left(\sum x_(t)^(2)\right)b=\sum x_(t)y_(t)).
Par conséquent, la formule d'estimation d'un seul coefficient a la forme
B ^ = ∑ t = 1 n X t y t ∑ t = 1 n X t 2 = X y ¯ X 2 ¯ (\displaystyle (\hat (b))=(\frac (\sum _(t=1)^(n)x_(t )y_(t))(\sum _(t=1)^(n)x_(t)^(2)))=(\frac (\overline (xy))(\overline (x^(2)) ))).
Le cas d'un modèle polynomial
Si les données sont ajustées par une fonction de régression polynomiale d'une variable f (x) = b 0 + ∑ je = 1 k b je X je (\displaystyle f(x)=b_(0)+\sum \limits _(i=1)^(k)b_(i)x^(i)), puis, percevant des degrés x je (\displaystyle x^(i)) comme facteurs indépendants pour chaque je (\displaystyle je) il est possible d'estimer les paramètres du modèle à partir de la formule générale d'estimation des paramètres du modèle linéaire. Pour ce faire, il suffit de prendre en compte dans la formule générale qu'avec une telle interprétation X t je X t j = X t je X t j = X t je + j (\displaystyle x_(ti)x_(tj)=x_(t)^(i)x_(t)^(j)=x_(t)^(i+j)) et X t j y t = X t j y t (\displaystyle x_(tj)y_(t)=x_(t)^(j)y_(t)). Par conséquent, les équations matricielles dans ce cas prendront la forme :
(n ∑ n X t ... ∑ n X t k ∑ n X t ∑ n X t 2 ... ∑ n X t k + 1 ⋮ ⋱ ⋮ ∑ n X t k ∑ n X t k + 1 ... ∑ n X t 2 k) [b 0 b 1 ⋮ b k] = [∑ n y t ∑ n X t y t ⋮ n X t k y t ] . (\displaystyle (\begin(pmatrix)n&\sum \limits _(n)x_(t)&\ldots &\sum \limits _(n)x_(t)^(k)\\\sum \limits _( n)x_(t)&\sum \limits _(n)x_(t)^(2)&\ldots &\sum \limits _(n)x_(t)^(k+1)\\\vdots & \vdots &\ddots &\vdots \\\sum \limits _(n)x_(t)^(k)&\sum \limits _(n)x_(t)^(k+1)&\ldots &\ somme \limits _(n)x_(t)^(2k)\end(pmatrix))(\begin(bmatrix)b_(0)\\b_(1)\\\vdots \\b_(k)\end( bmatrix))=(\begin(bmatrix)\sum \limits _(n)y_(t)\\\sum \limits _(n)x_(t)y_(t)\\\vdots \\\sum \limits _(n)x_(t)^(k)y_(t)\end(bmatrice)).)
Propriétés statistiques des estimations MCO
Tout d'abord, nous notons que pour les modèles linéaires, les estimations des moindres carrés sont des estimations linéaires, comme il ressort de la formule ci-dessus. Pour l'absence de biais des estimations des moindres carrés, il est nécessaire et suffisant de remplir la condition la plus importante de l'analyse de régression : l'espérance mathématique d'une erreur aléatoire conditionnelle aux facteurs doit être égale à zéro. Cette condition est satisfaite, notamment, si
- l'espérance mathématique des erreurs aléatoires est nulle, et
- les facteurs et les erreurs aléatoires sont des valeurs indépendantes aléatoires .
La deuxième condition - la condition des facteurs exogènes - est fondamentale. Si cette propriété n'est pas satisfaite, nous pouvons supposer que presque toutes les estimations seront extrêmement insatisfaisantes : elles ne seront même pas cohérentes (c'est-à-dire que même une très grande quantité de données ne permet pas d'obtenir des estimations qualitatives dans ce cas). Dans le cas classique, une hypothèse plus forte est faite sur le déterminisme des facteurs, contrairement à une erreur aléatoire, ce qui signifie automatiquement que la condition exogène est satisfaite. Dans le cas général, pour la cohérence des estimations, il suffit de satisfaire la condition d'exogénéité ainsi que la convergence de la matrice V x (\displaystyle V_(x))à une matrice non dégénérée lorsque la taille de l'échantillon augmente à l'infini.
Pour que, en plus de la cohérence et de l'absence de biais, les estimations des moindres carrés (habituels) soient également efficaces (les meilleures de la classe des estimations linéaires sans biais), il est nécessaire de remplir des propriétés supplémentaires d'une erreur aléatoire :
Ces hypothèses peuvent être formulées pour la covariance matrice du vecteur d'erreurs aléatoires V (ε) = σ 2 I (\displaystyle V(\varepsilon)=\sigma ^(2)I).
Un modèle linéaire qui satisfait ces conditions est appelé classique. Les estimations MCO pour la régression linéaire classique sont des estimations impartiales, cohérentes et les plus efficaces dans la classe de toutes les estimations linéaires impartiales (dans la littérature anglaise, l'abréviation est parfois utilisée bleu (Meilleur estimateur linéaire sans biais) est la meilleure estimation linéaire sans biais ; dans la littérature nationale, le théorème de Gauss - Markov est plus souvent cité). Comme il est facile de le montrer, la matrice de covariance du vecteur d'estimations des coefficients sera égale à :
V (b ^ O L S) = σ 2 (X T X) − 1 (\displaystyle V((\hat (b))_(OLS))=\sigma ^(2)(X^(T)X)^(-1 )).
L'efficacité signifie que cette matrice de covariance est "minimale" (toute combinaison linéaire de coefficients, et en particulier les coefficients eux-mêmes, a une variance minimale), c'est-à-dire que dans la classe des estimations linéaires sans biais, les estimations MCO sont les meilleures. Les éléments diagonaux de cette matrice - les variances des estimations des coefficients - sont des paramètres importants de la qualité des estimations obtenues. Cependant, il n'est pas possible de calculer la matrice de covariance car la variance de l'erreur aléatoire est inconnue. On peut prouver que l'estimation non biaisée et cohérente (pour le modèle linéaire classique) de la variance des erreurs aléatoires est la valeur :
S 2 = R S S / (n - k) (\displaystyle s^(2)=RSS/(n-k)).
En remplaçant cette valeur dans la formule de la matrice de covariance, nous obtenons une estimation de la matrice de covariance. Les estimations qui en résultent sont également impartiales et cohérentes. Il est également important que l'estimation de la variance d'erreur (et donc les variances des coefficients) et les estimations des paramètres du modèle soient des variables aléatoires indépendantes, ce qui permet d'obtenir des statistiques de test pour tester les hypothèses sur les coefficients du modèle.
Il convient de noter que si les hypothèses classiques ne sont pas satisfaites, les estimations des paramètres des moindres carrés ne sont pas les plus efficaces et, le cas échéant, W (\displaystyle W) est une matrice de poids définie positive symétrique. Les moindres carrés ordinaires sont un cas particulier de cette approche, lorsque la matrice de poids est proportionnelle à la matrice d'identité. Comme on le sait, pour les matrices (ou opérateurs) symétriques, il existe une décomposition W = P T P (\displaystyle W=P^(T)P). Par conséquent, cette fonctionnelle peut être représentée comme suit e T P T P e = (P e) T P e = e ∗ T e ∗ (\displaystyle e^(T)P^(T)Pe=(Pe)^(T)Pe=e_(*)^(T)e_( *)), c'est-à-dire que cette fonctionnelle peut être représentée comme la somme des carrés de certains "résidus" transformés. Ainsi, on peut distinguer une classe de méthodes des moindres carrés - les méthodes LS (Least Squares).
Il est prouvé (théorème d'Aitken) que pour un modèle de régression linéaire généralisé (dans lequel aucune restriction n'est imposée sur la matrice de covariance des erreurs aléatoires), les plus efficaces (dans la classe des estimations linéaires sans biais) sont les estimations de ce qu'on appelle. OLS généralisé (OMNK, GLS - Moindres Carrés Généralisés)- Méthode LS avec une matrice de poids égale à la matrice de covariance inverse des erreurs aléatoires : W = V ε − 1 (\displaystyle W=V_(\varepsilon )^(-1)).
On peut montrer que la formule des estimations GLS des paramètres du modèle linéaire a la forme
B ^ G L S = (X T V - 1 X) - 1 X T V - 1 y (\displaystyle (\hat (b))_(GLS)=(X^(T)V^(-1)X)^(-1) X^(T)V^(-1)y).
La matrice de covariance de ces estimations, respectivement, sera égale à
V (b ^ G L S) = (X T V - 1 X) - 1 (\displaystyle V((\hat (b))_(GLS))=(X^(T)V^(-1)X)^(- un)).
En fait, l'essence de l'OLS réside dans une certaine transformation (linéaire) (P) des données d'origine et l'application des moindres carrés habituels aux données transformées. Le but de cette transformation est que pour les données transformées, les erreurs aléatoires satisfont déjà les hypothèses classiques.
Moindres carrés pondérés
Dans le cas d'une matrice de poids diagonale (et donc de la matrice de covariance des erreurs aléatoires), on a ce qu'on appelle les moindres carrés pondérés (WLS - Weighted Least Squares). Dans ce cas, la somme pondérée des carrés des résidus du modèle est minimisée, c'est-à-dire que chaque observation reçoit un « poids » inversement proportionnel à la variance de l'erreur aléatoire sur cette observation : e T W e = ∑ t = 1 n e t 2 σ t 2 (\displaystyle e^(T)We=\sum _(t=1)^(n)(\frac (e_(t)^(2))(\ sigma _(t)^(2)))). En fait, les données sont transformées en pondérant les observations (en divisant par une quantité proportionnelle à l'écart type supposé des erreurs aléatoires), et les moindres carrés normaux sont appliqués aux données pondérées.
ISBN 978-5-7749-0473-0.
COURS DE TRAVAIL
Discipline : Informatique
Sujet : Approximation d'une fonction par la méthode des moindres carrés
Introduction
1. Énoncé du problème
2. Formules de calcul
Calcul à l'aide de tableaux réalisés à l'aide de Microsoft Excel
Schéma d'algorithme
Calcul dans MathCad
Résultats linéaires
Présentation des résultats sous forme de graphiques
Introduction
Le but du cours est d'approfondir les connaissances en informatique, de développer et de consolider les compétences de travail avec le tableur Microsoft Excel et le produit logiciel MathCAD et de les appliquer pour résoudre des problèmes à l'aide d'un ordinateur du domaine lié à la recherche.
Approximation (du latin "approximare" - "approche") - une expression approximative de tout objet mathématique (par exemple, des nombres ou des fonctions) à travers d'autres plus simples, plus pratiques à utiliser ou simplement mieux connues. Dans la recherche scientifique, l'approximation est utilisée pour décrire, analyser, généraliser et utiliser davantage les résultats empiriques.
Comme on le sait, il peut exister une relation exacte (fonctionnelle) entre les valeurs, lorsqu'une valeur de l'argument correspond à une valeur spécifique, et une relation moins précise (corrélation), lorsqu'une valeur spécifique de l'argument correspond à une valeur approchée ou un ensemble de valeurs de fonction plus ou moins proches les unes des autres. Lorsque vous menez une recherche scientifique, traitez les résultats d'une observation ou d'une expérience, vous devez généralement faire face à la deuxième option.
Lors de l'étude des dépendances quantitatives de divers indicateurs, dont les valeurs sont déterminées de manière empirique, il existe généralement une certaine variabilité. Elle est déterminée en partie par l'hétérogénéité des objets étudiés de nature inanimée et, surtout, vivante, et en partie par l'erreur d'observation et de traitement quantitatif des matériaux. Il n'est pas toujours possible d'éliminer complètement le dernier élément; il ne peut être minimisé que par un choix judicieux d'une méthode de recherche adéquate et de la précision du travail. Par conséquent, lors de la réalisation de tout travail de recherche, se pose le problème d'identifier la véritable nature de la dépendance des indicateurs étudiés, tel ou tel degré masqué par la négligence de la variabilité : les valeurs. Pour cela, une approximation est utilisée - une description approximative de la dépendance de corrélation des variables par une équation de dépendance fonctionnelle appropriée qui traduit la tendance principale de la dépendance (ou sa "tendance").
Lors du choix d'une approximation, il convient de partir de la tâche spécifique de l'étude. Habituellement, plus l'équation utilisée pour l'approximation est simple, plus la description obtenue de la dépendance est approximative. Par conséquent, il est important de lire dans quelle mesure et ce qui a causé les écarts de valeurs spécifiques par rapport à la tendance résultante. Lors de la description de la dépendance de valeurs déterminées empiriquement, une précision beaucoup plus grande peut être obtenue en utilisant une équation multiparamétrique plus complexe. Cependant, il est inutile d'essayer de transmettre des écarts aléatoires de valeurs dans des séries spécifiques de données empiriques avec une précision maximale. Il est beaucoup plus important de saisir la régularité générale, qui dans ce cas est le plus logiquement et avec une précision acceptable exprimée précisément par l'équation à deux paramètres de la fonction puissance. Ainsi, lors du choix d'une méthode d'approximation, le chercheur fait toujours un compromis: il décide dans quelle mesure dans ce cas il est opportun et approprié de «sacrifier» les détails et, en conséquence, dans quelle mesure la dépendance des variables comparées doit être exprimée de manière généralisée. Parallèlement à l'identification de motifs masqués par des déviations aléatoires des données empiriques par rapport au motif général, l'approximation permet également de résoudre de nombreux autres problèmes importants : formaliser la dépendance trouvée ; trouver des valeurs inconnues de la variable dépendante par interpolation ou, le cas échéant, extrapolation.
Dans chaque tâche, les conditions du problème, les données initiales, le formulaire d'émission des résultats sont formulés, les principales dépendances mathématiques pour résoudre le problème sont indiquées. Conformément à la méthode de résolution du problème, un algorithme de solution est développé, qui est présenté sous forme graphique.
1. Énoncé du problème
1. En utilisant la méthode des moindres carrés, approximez la fonction donnée dans un tableau :
a) un polynôme du premier degré ![]() ;
;
b) un polynôme du second degré ;
c) dépendance exponentielle.
Pour chaque dépendance, calculez le coefficient de déterminisme.
Calculer le coefficient de corrélation (uniquement dans le cas a).
Tracez une ligne de tendance pour chaque dépendance.
À l'aide de la fonction DROITEREG, calculez les caractéristiques numériques de la dépendance à l'égard de .
Comparez vos calculs avec les résultats obtenus à l'aide de la fonction DROITEREG.
Conclure laquelle des formules obtenues se rapproche le mieux de la fonction .
Écrivez un programme dans l'un des langages de programmation et comparez les résultats des calculs avec ceux obtenus ci-dessus.
Option 3. La fonction est indiquée dans le tableau. un.
Tableau 1.
2. Formules de calcul Souvent, lors de l'analyse de données empiriques, il devient nécessaire de trouver une relation fonctionnelle entre les valeurs de x et y, qui sont obtenues à la suite de l'expérience ou de mesures. Xi (valeur indépendante) est fixée par l'expérimentateur, et yi, appelées valeurs empiriques ou expérimentales, est obtenue à la suite de l'expérience. La forme analytique de la dépendance fonctionnelle qui existe entre les valeurs x et y est généralement inconnue, par conséquent, une tâche pratiquement importante se pose - trouver une formule empirique (où sont les paramètres), dont les valeurs à éventuellement différeraient peu des valeurs expérimentales. Selon la méthode des moindres carrés, les meilleurs coefficients sont ceux pour lesquels la somme des écarts au carré de la fonction empirique trouvée par rapport aux valeurs données de la fonction sera minimale. En utilisant la condition nécessaire pour l'extremum d'une fonction de plusieurs variables - égalité à zéro des dérivées partielles, trouver un ensemble de coefficients qui délivrent le minimum de la fonction définie par la formule (2) et obtenir un système normal de détermination des coefficients Ainsi, trouver les coefficients revient à résoudre le système (3). Le type de système (3) dépend de la classe de formules empiriques dont on recherche la dépendance (1). Dans le cas d'une dépendance linéaire, le système (3) prendra la forme : Dans le cas d'une dépendance quadratique, le système (3) prendra la forme : Dans certains cas, en tant que formule empirique, une fonction est prise dans laquelle des coefficients incertains entrent de manière non linéaire. Dans ce cas, le problème peut parfois être linéarisé, c'est-à-dire réduire à linéaire. Parmi ces dépendances figure la dépendance exponentielle où a1 et a2 sont des coefficients indéfinis. La linéarisation est obtenue en prenant le logarithme d'égalité (6), après quoi on obtient la relation Notons et respectivement par et , alors la dépendance (6) peut s'écrire , ce qui permet d'appliquer les formules (4) avec a1 remplacé par et par . Le graphique de la dépendance fonctionnelle restaurée y(x) à partir des résultats des mesures (xi, yi), i=1,2,…,n est appelé la courbe de régression. Pour vérifier la concordance de la courbe de régression construite avec les résultats de l'expérience, les caractéristiques numériques suivantes sont généralement introduites : le coefficient de corrélation (dépendance linéaire), le rapport de corrélation et le coefficient de déterminisme. Le coefficient de corrélation est une mesure de la relation linéaire entre les variables aléatoires dépendantes : il montre à quel point, en moyenne, l'une des variables peut être représentée comme une fonction linéaire de l'autre. Le coefficient de corrélation est calculé par la formule : où est la moyenne arithmétique, respectivement, pour x, y. Le coefficient de corrélation entre variables aléatoires ne dépasse pas en valeur absolue 1. Plus il est proche de 1, plus la relation linéaire entre x et y est étroite. Dans le cas d'une corrélation non linéaire, les valeurs moyennes conditionnelles sont situées près de la ligne courbe. Dans ce cas, en tant que caractéristique de la force de la connexion, il est recommandé d'utiliser le rapport de corrélation, dont l'interprétation ne dépend pas du type de dépendance à l'étude. Le rapport de corrélation est calculé par la formule : où Est toujours. Égalité = correspond à des variables aléatoires non corrélées ; = si et seulement s'il existe une relation fonctionnelle exacte entre x et y. Dans le cas d'une dépendance linéaire de y sur x, le rapport de corrélation coïncide avec le carré du coefficient de corrélation. La valeur est utilisée comme indicateur de l'écart de la régression par rapport à la linéarité. Le rapport de corrélation est une mesure de la corrélation y c x sous n'importe quelle forme, mais ne peut donner une idée du degré de proximité des données empiriques avec une forme particulière. Pour savoir avec quelle précision la courbe construite reflète les données empiriques, une autre caractéristique est introduite - le coefficient de détermination. Le coefficient de déterminisme est déterminé par la formule : où Sres = - somme résiduelle des carrés, qui caractérise l'écart des données expérimentales par rapport aux données théoriques total - somme totale des carrés, où la valeur moyenne est yi. Plus la somme des carrés résiduelle est petite par rapport à la somme des carrés totale, plus la valeur du coefficient de déterminisme r2 est élevée, ce qui indique dans quelle mesure l'équation obtenue par analyse de régression explique les relations entre les variables. S'il est égal à 1, alors il y a une corrélation complète avec le modèle, c'est-à-dire il n'y a pas de différence entre les valeurs y réelles et estimées. Sinon, si le coefficient de déterminisme est 0, l'équation de régression ne parvient pas à prédire les valeurs y. Le coefficient de déterminisme ne dépasse toujours pas le rapport de corrélation. Dans le cas où l'égalité est satisfaite, nous pouvons supposer que la formule empirique construite reflète le plus fidèlement les données empiriques. 3. Calcul à l'aide de tableaux réalisés à l'aide de Microsoft Excel Pour les calculs, il est conseillé de disposer les données sous forme de tableau 2 à l'aide du tableur Microsoft Excel. Tableau 2
Expliquons comment le tableau 2 est compilé. Étape 1. Dans les cellules A1:A25, nous entrons les valeurs xi. Étape 2. Dans les cellules B1: B25, nous entrons les valeurs de yi. Étape 3. Dans la cellule C1, entrez la formule = A1 ^ 2. Étape 4. Cette formule est copiée dans les cellules C1 : C25. Étape 5. Dans la cellule D1, entrez la formule = A1 * B1. Étape 6. Cette formule est copiée dans les cellules D1:D25. Étape 7. Dans la cellule F1, entrez la formule = A1 ^ 4. Étape 8. Dans les cellules F1:F25, cette formule est copiée. Étape 9. Dans la cellule G1, entrez la formule =A1^2*B1. Étape 10. Cette formule est copiée dans les cellules G1 : G25. Étape 11. Dans la cellule H1, entrez la formule = LN (B1). Étape 12. Cette formule est copiée dans les cellules H1:H25. Étape 13. Dans la cellule I1, entrez la formule = A1 * LN (B1). Étape 14. Cette formule est copiée dans les cellules I1:I25. Nous effectuons les étapes suivantes en utilisant la sommation automatique S. Étape 15. Dans la cellule A26, entrez la formule = SUM (A1 : A25). Étape 16. Dans la cellule B26, entrez la formule = SOMME (B1 : B25). Étape 17. Dans la cellule C26, entrez la formule = SUM (C1 : C25). Étape 18. Dans la cellule D26, entrez la formule = SOMME (D1 : D25). Étape 19. Dans la cellule E26, entrez la formule = SUM (E1 : E25). Étape 20. Dans la cellule F26, entrez la formule = SUM (F1 : F25). Étape 21. Dans la cellule G26, entrez la formule = SOMME (G1 : G25). Étape 22. Dans la cellule H26, entrez la formule = SUM(H1:H25). Étape 23. Dans la cellule I26, entrez la formule = SUM(I1:I25). Nous approchons la fonction par une fonction linéaire . Pour déterminer les coefficients et on utilise le système (4). En utilisant les totaux du tableau 2, situés dans les cellules A26, B26, C26 et D26, nous écrivons le système (4) comme en résolvant, on obtient Le système a été résolu par la méthode de Cramer. Dont l'essence est la suivante. Considérons un système de n équations linéaires algébriques à n inconnues : Le déterminant du système est le déterminant de la matrice du système : Dénotons - le déterminant qui sera obtenu à partir du déterminant du système Δ en remplaçant la jème colonne par la colonne Ainsi, l'approximation linéaire a la forme Nous résolvons le système (11) à l'aide des outils Microsoft Excel. Les résultats sont présentés dans le tableau 3. Tableau 3
matrice inverse Dans le tableau 3, les cellules A32:B33 contiennent la formule (=MOBR(A28:B29)). Les cellules E32:E33 contiennent la formule (=MULTI(A32:B33),(C28:C29)). Ensuite, nous approchons la fonction par une fonction quadratique en résolvant, on obtient a1=10.663624, Ainsi, l'approximation quadratique a la forme Nous résolvons le système (16) à l'aide des outils Microsoft Excel. Les résultats sont présentés dans le tableau 4. Tableau 4
matrice inverse Dans le tableau 4, les cellules A41:C43 contiennent la formule (=MOBR(A36:C38)). Les cellules F41:F43 contiennent la formule (=MMULT(A41:C43),(D36:D38)). Maintenant, nous approchons la fonction par la fonction exponentielle . Pour déterminer les coefficients et prendre le logarithme des valeurs et, en utilisant les totaux du tableau 2, situés dans les cellules A26, C26, H26 et I26, on obtient le système En résolvant le système (18), on obtient et . Après potentialisation on obtient . Ainsi, l'approximation exponentielle a la forme Nous résolvons le système (18) à l'aide des outils Microsoft Excel. Les résultats sont présentés dans le tableau 5. Tableau 5
matrice inverse Les cellules A50:B51 contiennent la formule (=MOBR(A46:B47)). Dans les cellules E49:E50 la formule est écrite (=MULTI(A50:B51),(C46:C47)). La cellule E51 contient la formule=EXP(E49). Calculez la moyenne arithmétique et par les formules : Les résultats des calculs et les outils Microsoft Excel sont présentés dans le tableau 6. Tableau 6
La cellule B54 contient la formule =A26/25. La cellule B55 contient la formule = B26/25 Tableau 7
Étape 1. Dans la cellule J1, entrez la formule = (A1-$B$54)*(B1-$B$55). Étape 2. Cette formule est copiée dans les cellules J2 : J25. Étape 3. Dans la cellule K1, entrez la formule = (A1-$B$54)^2. Étape 4. Cette formule est copiée dans les cellules k2:K25. Étape 5. Dans la cellule L1, entrez la formule = (B1-$B$55)^2. Étape 6. Cette formule est copiée dans les cellules L2 : L25. Étape 7. Dans la cellule M1, entrez la formule = ($E$32+$E$33*A1-B1)^2. Étape 8. Cette formule est copiée dans les cellules M2:M25. Étape 9. Dans la cellule N1, entrez la formule = ($F$41+$F$42*A1+$F$43*A1^2-B1)^2. Étape 10. Dans les cellules N2:N25, cette formule est copiée. Étape 11. Dans la cellule O1, entrez la formule = ($E$51*EXP($E$50*A1)-B1)^2. Étape 12. Dans les cellules O2:O25, cette formule est copiée. Nous effectuons les étapes suivantes en utilisant la sommation automatique S. Étape 13. Dans la cellule J26, entrez la formule = SUM (J1 : J25). Étape 14. Dans la cellule K26, entrez la formule = SUM(K1:K25). Étape 15. Dans la cellule L26, entrez la formule = SUM (L1 : L25). Étape 16. Dans la cellule M26, entrez la formule = SUM(M1:M25). Étape 17. Dans la cellule N26, entrez la formule = SUM(N1:N25). Étape 18. Dans la cellule O26, entrez la formule = SOMME (O1 : O25). Calculons maintenant le coefficient de corrélation à l'aide de la formule (8) (uniquement pour l'approximation linéaire) et le coefficient de déterminisme à l'aide de la formule (10). Les résultats des calculs à l'aide de Microsoft Excel sont présentés dans le tableau 8. Tableau 8
Coefficient de corrélation Coefficient de déterminisme (approximation linéaire) Coefficient de déterminisme (approximation quadratique) Coefficient de déterminisme (approximation exponentielle) La cellule E57 contient la formule =J26/(K26*L26)^(1/2). La cellule E59 contient la formule=1-M26/L26. La cellule E61 contient la formule=1-N26/L26. La cellule E63 contient la formule=1-O26/L26. Une analyse des résultats de calcul montre que l'approximation quadratique décrit le mieux les données expérimentales. Schéma d'algorithme Riz. 1. Schéma de l'algorithme pour le programme de calcul. 5. Calcul dans MathCad Régression linéaire · ligne (x, y) - vecteur à deux éléments (b, a) des coefficients de régression linéaire b+ax ; · x - vecteur de données réelles de l'argument ; · y est un vecteur de valeurs de données réelles de même taille. Figure 2. La régression polynomiale consiste à ajuster les données (x1, y1) avec un polynôme de degré k. Pour k=i, le polynôme est une droite, pour k=2 c'est une parabole, pour k=3 c'est une parabole cubique, etc. En règle générale, k<5. · régression (x, y, k) - vecteur de coefficients pour la construction de régression de données polynomiales ; interp (s,x,y,t) - résultat de la régression polynomiale ; s=régression(x,y,k); · x est un vecteur de données réelles de l'argument dont les éléments sont rangés par ordre croissant ; · y est un vecteur de valeurs de données réelles de même taille ; k - degré du polynôme de régression (entier positif); · t - la valeur de l'argument du polynôme de régression. figure 3 En plus de ceux considérés, plusieurs autres types de régression à trois paramètres sont intégrés à Mathcad, leur implémentation est quelque peu différente des options de régression ci-dessus en ce que, en plus du tableau de données, il est nécessaire de définir certaines valeurs initiales de les coefficients a, b, c. Utilisez le type de régression approprié si vous avez une bonne idée de la dépendance qui décrit votre tableau de données. Lorsque le type de régression ne reflète pas bien la séquence de données, alors son résultat est souvent insatisfaisant et même très différent selon le choix des valeurs initiales. Chacune des fonctions produit un vecteur de paramètres raffinés a, b, c. DROITEREG Résultats Considérez le but de la fonction LINEST. Cette fonction utilise la méthode des moindres carrés pour calculer la ligne droite qui correspond le mieux aux données disponibles. La fonction renvoie un tableau qui décrit la ligne résultante. L'équation d'une droite est : M1x1 + m2x2 + ... + b ou y = mx + b, algorithme tabulaire logiciel Microsoft où la valeur dépendante de y est une fonction de la valeur indépendante de x. Les m valeurs sont les coefficients correspondant à chaque variable indépendante x, et b est une constante. Notez que y, x et m peuvent être des vecteurs. Pour obtenir les résultats, vous devez créer une formule de feuille de calcul qui s'étendra sur 5 lignes et 2 colonnes. Cet intervalle peut être placé n'importe où sur la feuille de calcul. Dans cet intervalle, vous devez entrer la fonction DROITEREG. En conséquence, toutes les cellules de l'intervalle A65:B69 doivent être remplies (comme indiqué dans le tableau 9). Tableau 9
Expliquons le but de certaines des quantités situées dans le tableau 9. Les valeurs situées dans les cellules A65 et B65 caractérisent respectivement la pente et le décalage. - coefficient de déterminisme. - valeur F-observée. - nombre de degrés de liberté. Présentation des résultats sous forme de graphiques Riz. 4. Graphique d'approximation linéaire Riz. 5. Graphique d'approximation quadratique Riz. 6. Tracé d'approximation exponentielle résultats Tirons des conclusions sur la base des résultats des données obtenues. Une analyse des résultats de calcul montre que l'approximation quadratique décrit le mieux les données expérimentales, puisque sa ligne de tendance reflète le plus fidèlement le comportement de la fonction dans cette zone. En comparant les résultats obtenus à l'aide de la fonction DROITEREG, nous voyons qu'ils coïncident complètement avec les calculs effectués ci-dessus. Cela indique que les calculs sont corrects. Les résultats obtenus à l'aide du programme MathCad correspondent parfaitement aux valeurs indiquées ci-dessus. Cela indique l'exactitude des calculs. Bibliographie 1 BP Demidovich, I.A. Bordeaux. Fondamentaux des mathématiques computationnelles. M : Maison d'édition publique de littérature physique et mathématique. 2 Informatique : manuel, éd. prof. NV Makarova. M : Finances et statistiques, 2007. 3 Informatique : Atelier sur l'informatique, éd. prof. NV Makarova. M : Finances et statistiques, 2010. 4 V.B. Komyaguine. Programmation sous Excel en Visual Basic. M : Radio et communication, 2007. 5 N. Nicole, R. Albrecht. Exceller. Feuilles de calcul. M : Éd. "ECOM", 2008. 6 Lignes directrices pour la mise en œuvre des cours d'informatique (pour les étudiants du département de correspondance de toutes les spécialités), éd. Zhurova G.N., SPbGGI(TU), 2011.
![]() , (1)
, (1)
![]() :
:![]() (3)
(3)
 (4)
(4)
 (5)
(5)
![]() (7)
(7)
 (8)
(8) (9)
(9) (10)
(10)
![]() et le numérateur caractérise la dispersion des moyennes conditionnelles autour de la moyenne inconditionnelle.
et le numérateur caractérise la dispersion des moyennes conditionnelles autour de la moyenne inconditionnelle.![]() - somme des carrés de régression caractérisant l'étalement des données.
- somme des carrés de régression caractérisant l'étalement des données.
 (11)
(11)
![]() et .
et . (12)
(12)
 (13)
(13)
![]() . Pour déterminer les coefficients a1, a2 et a3, on utilise le système (5). En utilisant les totaux du tableau 2, situés dans les cellules A26, B26, C26 , D26, E26, F26, G26, nous écrivons le système (5) comme
. Pour déterminer les coefficients a1, a2 et a3, on utilise le système (5). En utilisant les totaux du tableau 2, situés dans les cellules A26, B26, C26 , D26, E26, F26, G26, nous écrivons le système (5) comme  (16)
(16)
![]() et
et ![]()
 (18)
(18)








La méthode des moindres carrés est l'une des plus courantes et des plus développées en raison de sa simplicité et efficacité des méthodes d'estimation des paramètres de. Dans le même temps, une certaine prudence doit être observée lors de son utilisation, car les modèles construits à l'aide de celui-ci peuvent ne pas répondre à un certain nombre d'exigences concernant la qualité de leurs paramètres et, par conséquent, ne reflètent pas « bien » les modèles de développement de processus.
Examinons plus en détail la procédure d'estimation des paramètres d'un modèle économétrique linéaire par la méthode des moindres carrés. Un tel modèle sous forme générale peut être représenté par l'équation (1.2):
y t = une 0 + une 1 X 1 t +...+ une n X nt + ε t .
La donnée initiale lors de l'estimation des paramètres a 0 , a 1 ,..., a n est le vecteur de valeurs de la variable dépendante y= (y 1 , y 2 , ... , y T)" et la matrice des valeurs des variables indépendantes

dans laquelle la première colonne, composée de uns, correspond au coefficient du modèle .
La méthode des moindres carrés tire son nom du principe de base selon lequel les estimations de paramètres obtenues sur sa base doivent satisfaire : la somme des carrés de l'erreur du modèle doit être minimale.
Exemples de résolution de problèmes par la méthode des moindres carrés
Exemple 2.1. L'entreprise commerciale dispose d'un réseau composé de 12 magasins, dont les informations sur les activités sont présentées dans le tableau. 2.1.
La direction de l'entreprise aimerait savoir comment la taille de l'annuel dépend de la surface de vente du magasin.
Tableau 2.1
|
Numéro de magasin |
Chiffre d'affaires annuel, millions de roubles |
Zone commerciale, milliers de m 2 |
Solution des moindres carrés. Désignons - le chiffre d'affaires annuel du -ème magasin, en millions de roubles; - surface de vente du -ème magasin, mille m 2.

Fig.2.1. Nuage de points pour l'exemple 2.1
Déterminer la forme de la relation fonctionnelle entre les variables et construire un nuage de points (Fig. 2.1).
Sur la base du diagramme de dispersion, nous pouvons conclure que le chiffre d'affaires annuel dépend positivement de la zone de vente (c'est-à-dire que y augmentera avec la croissance de ). La forme la plus appropriée de connexion fonctionnelle est − linéaire.
Les informations pour les calculs ultérieurs sont présentées dans le tableau. 2.2. En utilisant la méthode des moindres carrés, nous estimons les paramètres du modèle économétrique linéaire à un facteur

Tableau 2.2
Ainsi,
Par conséquent, avec une augmentation de la zone commerciale de 1 000 m 2, toutes choses étant égales par ailleurs, le chiffre d'affaires annuel moyen augmente de 67,8871 millions de roubles.
Exemple 2.2. La direction de l'entreprise a remarqué que le chiffre d'affaires annuel dépend non seulement de la surface de vente du magasin (voir exemple 2.1), mais également du nombre moyen de visiteurs. Les informations pertinentes sont présentées dans le tableau. 2.3.
Tableau 2.3
Décision. Dénoter - le nombre moyen de visiteurs au e magasin par jour, mille personnes.
Déterminer la forme de la relation fonctionnelle entre les variables et construire un nuage de points (Fig. 2.2).
Sur la base du diagramme de dispersion, nous pouvons conclure que le chiffre d'affaires annuel est positivement lié au nombre moyen de visiteurs par jour (c'est-à-dire que y augmentera avec la croissance de ). La forme de dépendance fonctionnelle est linéaire.

Riz. 2.2. Nuage de points par exemple 2.2
Tableau 2.4
De manière générale, il est nécessaire de déterminer les paramètres du modèle économétrique à deux facteurs
y t \u003d une 0 + une 1 x 1 t + une 2 x 2 t + ε t
Les informations requises pour les calculs ultérieurs sont présentées dans le tableau. 2.4.
Estimons les paramètres d'un modèle économétrique linéaire à deux facteurs par la méthode des moindres carrés.

Ainsi,
L'évaluation du coefficient = 61,6583 montre que, toutes choses étant égales par ailleurs, avec une augmentation de la surface commerciale de 1 000 m 2, le chiffre d'affaires annuel augmentera en moyenne de 61,6583 millions de roubles.
(voir l'image). Il faut trouver l'équation d'une droite
Plus le nombre en valeur absolue est petit, mieux la droite (2) est choisie. Comme caractéristique de la précision de la sélection d'une droite (2), on peut prendre la somme des carrés
Les conditions minimales pour S seront
 |
(6) |
 |
(7) |
Les équations (6) et (7) peuvent être écrites sous la forme suivante :
 |
(8) |
 |
(9) |
À partir des équations (8) et (9), il est facile de trouver a et b à partir des valeurs expérimentales x i et y i . La droite (2) définie par les équations (8) et (9) est appelée droite obtenue par la méthode des moindres carrés (ce nom souligne que la somme des carrés S a un minimum). Les équations (8) et (9), à partir desquelles la droite (2) est déterminée, sont appelées équations normales.
Il est possible d'indiquer une manière simple et générale de compiler des équations normales. En utilisant les points expérimentaux (1) et l'équation (2), nous pouvons écrire le système d'équations pour a et b
| y 1 \u003d axe 1 +b, | |||
| y 2 \u003dax 2 +b, ... |
(10) | ||
| yn=axn+b, | |||
Nous multiplions les parties gauche et droite de chacune de ces équations par le coefficient à la première inconnue a (c'est-à-dire x 1 , x 2 , ..., x n) et additionnons les équations résultantes, nous obtenons ainsi la première équation normale ( 8).
On multiplie les membres gauche et droit de chacune de ces équations par le coefficient de la seconde inconnue b, c'est-à-dire par 1, et additionnez les équations résultantes, ce qui donne la deuxième équation normale (9).
Cette méthode d'obtention des équations normales est générale : elle convient, par exemple, à la fonction
est une valeur constante et doit être déterminée à partir de données expérimentales (1).
Le système d'équations de k s'écrit :
Trouvez la droite (2) en utilisant la méthode des moindres carrés.
Décision. Nous trouvons:
x je =21, y je =46,3, x je 2 =91, x je y je =179,1.
On écrit les équations (8) et (9)
De là, nous trouvons
Estimation de la précision de la méthode des moindres carrés
Donnons une estimation de la précision de la méthode pour le cas linéaire lorsque l'équation (2) a lieu.
Soit les valeurs expérimentales x i exactes, et les valeurs expérimentales y i ont des erreurs aléatoires avec la même variance pour tout i.
Nous introduisons la notation
| (16) |
Alors les solutions des équations (8) et (9) peuvent être représentées comme
| (17) | |
| (18) | |
| où | |
| (19) | |
| De l'équation (17) nous trouvons | |
| (20) | |
| De même, à partir de l'équation (18), nous obtenons | |
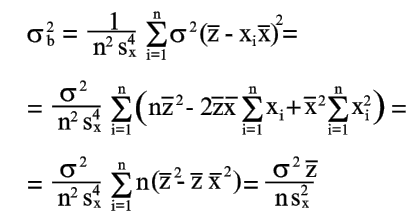 |
(21) |
| car | |
| (22) | |
| A partir des équations (21) et (22) on trouve | |
 |
(23) |
Les équations (20) et (23) donnent une estimation de la précision des coefficients déterminés par les équations (8) et (9).
A noter que les coefficients a et b sont corrélés. Par de simples transformations, on trouve leur moment de corrélation.
De là, nous trouvons
0,072 à x=1 et 6,
0,041 à x=3,5.
Littérature
Rive. Ya. B. Méthodes statistiques d'analyse et de contrôle de la qualité et de la fiabilité. M. : Gosenergoizdat, 1962, p. 552, p. 92-98.
Cet ouvrage s'adresse à un large éventail d'ingénieurs (instituts de recherche, bureaux d'études, sites d'essais et usines) impliqués dans la détermination de la qualité et de la fiabilité des équipements électroniques et autres produits industriels de masse (construction mécanique, lutherie, artillerie, etc.).
Le livre donne une application des méthodes de statistiques mathématiques au traitement et à l'évaluation des résultats des tests, dans laquelle la qualité et la fiabilité des produits testés sont déterminées. Pour la commodité des lecteurs, les informations nécessaires des statistiques mathématiques sont fournies, ainsi qu'un grand nombre de tableaux mathématiques auxiliaires qui facilitent les calculs nécessaires.
La présentation est illustrée par un grand nombre d'exemples tirés du domaine de l'électronique radio et de la technologie de l'artillerie.
Méthode des moindres carrés
Dans la dernière leçon du sujet, nous nous familiariserons avec l'application la plus célèbre FNP, qui trouve l'application la plus large dans divers domaines de la science et de la pratique. Cela peut être la physique, la chimie, la biologie, l'économie, la sociologie, la psychologie, etc. Par la volonté du destin, je dois souvent m'occuper de l'économie, et donc aujourd'hui je vais organiser pour vous un billet pour un pays étonnant appelé Économétrie=) … Comment tu ne veux pas ça ?! C'est très bien là-bas - vous n'avez qu'à décider! …Mais ce que vous voulez certainement, c'est apprendre à résoudre des problèmes moindres carrés. Et les lecteurs particulièrement assidus apprendront à les résoudre non seulement avec précision, mais aussi TRÈS RAPIDEMENT ;-) Mais d'abord énoncé général du problème+ exemple lié :
Laissez les indicateurs être étudiés dans un certain domaine qui ont une expression quantitative. En même temps, il y a tout lieu de croire que l'indicateur dépend de l'indicateur. Cette hypothèse peut être à la fois une hypothèse scientifique et basée sur le bon sens élémentaire. Laissons la science de côté, cependant, et explorons des domaines plus appétissants, à savoir les épiceries. Dénoter par :
– surface commerciale d'une épicerie, m²,
- chiffre d'affaires annuel d'une épicerie, millions de roubles.
Il est bien clair que plus la superficie du magasin est grande, plus son chiffre d'affaires est important dans la plupart des cas.
Supposons qu'après avoir effectué des observations/expériences/calculs/dansé avec un tambourin, nous ayons à notre disposition des données numériques : 
Avec les épiceries, je pense que tout est clair : - c'est la surface du 1er magasin, - son chiffre d'affaires annuel, - la surface du 2ème magasin, - son chiffre d'affaires annuel, etc. Soit dit en passant, il n'est pas du tout nécessaire d'avoir accès à des documents classifiés - une évaluation assez précise du chiffre d'affaires peut être obtenue en utilisant statistiques mathématiques. Cependant, ne vous laissez pas distraire, le cours d'espionnage commercial est déjà payé =)
Les données tabulaires peuvent également être écrites sous forme de points et représentées de la manière habituelle pour nous. Système cartésien .
Répondons à une question importante : combien de points faut-il pour une étude qualitative ?
Le plus gros le meilleur. L'ensemble minimum admissible se compose de 5-6 points. De plus, avec une petite quantité de données, les résultats « anormaux » ne doivent pas être inclus dans l'échantillon. Ainsi, par exemple, un petit magasin d'élite peut aider des ordres de grandeur plus que "ses collègues", déformant ainsi le schéma général qui doit être trouvé !
Si c'est assez simple, il faut choisir une fonction , programme qui passe le plus près possible des points ![]() . Une telle fonction est appelée se rapprochant
(approximation - approximation) ou alors fonction théorique
. D'une manière générale, apparaît ici immédiatement un "prétendant" évident - un polynôme de haut degré, dont le graphique passe par TOUS les points. Mais cette option est compliquée et souvent simplement incorrecte. (parce que le graphique "s'enroulera" tout le temps et reflétera mal la tendance principale).
. Une telle fonction est appelée se rapprochant
(approximation - approximation) ou alors fonction théorique
. D'une manière générale, apparaît ici immédiatement un "prétendant" évident - un polynôme de haut degré, dont le graphique passe par TOUS les points. Mais cette option est compliquée et souvent simplement incorrecte. (parce que le graphique "s'enroulera" tout le temps et reflétera mal la tendance principale).
Ainsi, la fonction souhaitée doit être suffisamment simple et en même temps refléter adéquatement la dépendance. Comme vous pouvez le deviner, l'une des méthodes pour trouver de telles fonctions s'appelle moindres carrés. Analysons d'abord son essence de manière générale. Laissez une fonction approximer les données expérimentales : 
Comment évaluer la précision de cette approximation ? Calculons également les différences (écarts) entre les valeurs expérimentales et fonctionnelles (nous étudions le dessin). La première pensée qui vient à l'esprit est d'estimer la taille de la somme, mais le problème est que les différences peuvent être négatives. (par exemple, ![]() )
et les écarts résultant de cette sommation s'annuleront mutuellement. Par conséquent, comme estimation de la précision de l'approximation, il se suggère de prendre la somme modules déviations :
)
et les écarts résultant de cette sommation s'annuleront mutuellement. Par conséquent, comme estimation de la précision de l'approximation, il se suggère de prendre la somme modules déviations :
![]() ou sous forme pliée : (pour ceux qui ne connaissent pas :
est l'icône de la somme, et
- variable auxiliaire - "compteur", qui prend des valeurs de 1 à
)
.
ou sous forme pliée : (pour ceux qui ne connaissent pas :
est l'icône de la somme, et
- variable auxiliaire - "compteur", qui prend des valeurs de 1 à
)
.
En approximant les points expérimentaux avec différentes fonctions, nous obtiendrons des valeurs différentes, et il est évident que là où cette somme est inférieure - cette fonction est plus précise.
Une telle méthode existe et s'appelle méthode du moindre module. Cependant, dans la pratique, il est devenu beaucoup plus répandu. méthode des moindres carrés, dans lequel les éventuelles valeurs négatives sont éliminées non pas par le module, mais en quadrillant les écarts:
![]() , après quoi les efforts sont dirigés vers la sélection d'une fonction telle que la somme des écarts au carré
, après quoi les efforts sont dirigés vers la sélection d'une fonction telle que la somme des écarts au carré ![]() était le plus petit possible. En fait, d'où le nom de la méthode.
était le plus petit possible. En fait, d'où le nom de la méthode.
Et maintenant, revenons à un autre point important : comme indiqué ci-dessus, la fonction sélectionnée devrait être assez simple - mais il existe également de nombreuses fonctions de ce type : linéaire , hyperbolique , exponentiel , logarithmique , quadratique etc. Et, bien sûr, ici, je voudrais immédiatement "réduire le champ d'activité". Quelle classe de fonctions choisir pour la recherche ? Technique primitive mais efficace :
- La façon la plus simple de dessiner des points ![]() sur le dessin et analyser leur emplacement. S'ils ont tendance à être en ligne droite, vous devriez rechercher équation de droite
sur le dessin et analyser leur emplacement. S'ils ont tendance à être en ligne droite, vous devriez rechercher équation de droite ![]() avec des valeurs optimales et . En d'autres termes, la tâche consiste à trouver des coefficients TEL - de sorte que la somme des écarts au carré soit la plus petite.
avec des valeurs optimales et . En d'autres termes, la tâche consiste à trouver des coefficients TEL - de sorte que la somme des écarts au carré soit la plus petite.
Si les points sont situés, par exemple, le long hyperbole, alors il est clair que la fonction linéaire donnera une mauvaise approximation. Dans ce cas, on recherche les coefficients les plus "favorables" pour l'équation de l'hyperbole ![]() - ceux qui donnent la somme minimale des carrés
- ceux qui donnent la somme minimale des carrés  .
.
Notez maintenant que dans les deux cas, nous parlons de fonctions de deux variables, dont les arguments sont options de dépendance recherchées:
Et essentiellement, nous devons résoudre un problème standard - trouver minimum d'une fonction de deux variables.
Rappelons notre exemple : supposons que les points « boutique » tendent à se situer en ligne droite et qu'il y ait tout lieu de croire à la présence dépendance linéaire chiffre d'affaires de la zone commerciale. Trouvons TELS coefficients "a" et "be" pour que la somme des écarts au carré ![]() était le plus petit. Tout comme d'habitude - d'abord dérivées partielles du 1er ordre. Selon règle de linéarité vous pouvez différencier juste sous l'icône de somme :
était le plus petit. Tout comme d'habitude - d'abord dérivées partielles du 1er ordre. Selon règle de linéarité vous pouvez différencier juste sous l'icône de somme : 
Si vous souhaitez utiliser ces informations pour un essai ou une dissertation, je serai très reconnaissant pour le lien dans la liste des sources, vous ne trouverez nulle part des calculs aussi détaillés : 
Faisons un système standard : 
Nous réduisons chaque équation par un "deux" et, en plus, "séparons" les sommes : 
Noter
: analyser indépendamment pourquoi "a" et "be" peuvent être retirés de l'icône de la somme. Soit dit en passant, formellement, cela peut être fait avec la somme ![]()
Réécrivons le système sous une forme "appliquée": 
après quoi l'algorithme pour résoudre notre problème commence à être dessiné:
Connaît-on les coordonnées des points ? Nous savons. Sommes ![]() peut-on trouver ? Facile. Nous composons le plus simple système de deux équations linéaires à deux inconnues("a" et "beh"). Nous résolvons le système, par exemple, La méthode de Cramer, résultant en un point stationnaire . Vérification condition suffisante pour un extremum, on peut vérifier qu'à ce stade la fonction
peut-on trouver ? Facile. Nous composons le plus simple système de deux équations linéaires à deux inconnues("a" et "beh"). Nous résolvons le système, par exemple, La méthode de Cramer, résultant en un point stationnaire . Vérification condition suffisante pour un extremum, on peut vérifier qu'à ce stade la fonction ![]() atteint avec précision le minimum. La vérification est associée à des calculs supplémentaires et nous la laisserons donc dans les coulisses. (si nécessaire, le cadre manquant peut être visualiséici
)
. Nous tirons la conclusion finale :
atteint avec précision le minimum. La vérification est associée à des calculs supplémentaires et nous la laisserons donc dans les coulisses. (si nécessaire, le cadre manquant peut être visualiséici
)
. Nous tirons la conclusion finale :
Une fonction ![]() le meilleur moyen (au moins par rapport à toute autre fonction linéaire) rapproche les points expérimentaux
le meilleur moyen (au moins par rapport à toute autre fonction linéaire) rapproche les points expérimentaux ![]() . Grosso modo, son graphique passe le plus près possible de ces points. Dans la tradition économétrie la fonction d'approximation résultante est également appelée équation de régression linéaire appariée
.
. Grosso modo, son graphique passe le plus près possible de ces points. Dans la tradition économétrie la fonction d'approximation résultante est également appelée équation de régression linéaire appariée
.
Le problème considéré est d'une grande importance pratique. Dans la situation de notre exemple, l'équation ![]() vous permet de prédire quel type de chiffre d'affaires ("yig") sera au magasin avec l'une ou l'autre valeur de la surface de vente (l'un ou l'autre sens de "x"). Oui, la prévision résultante ne sera qu'une prévision, mais dans de nombreux cas, elle s'avérera assez précise.
vous permet de prédire quel type de chiffre d'affaires ("yig") sera au magasin avec l'une ou l'autre valeur de la surface de vente (l'un ou l'autre sens de "x"). Oui, la prévision résultante ne sera qu'une prévision, mais dans de nombreux cas, elle s'avérera assez précise.
J'analyserai un seul problème avec des nombres «réels», car il ne présente aucune difficulté - tous les calculs sont au niveau du programme scolaire en 7e et 8e année. Dans 95 % des cas, il vous sera demandé de trouver uniquement une fonction linéaire, mais à la toute fin de l'article, je montrerai qu'il n'est pas plus difficile de trouver les équations de l'hyperbole optimale, de l'exposant et de certaines autres fonctions.
En fait, il reste à distribuer les goodies promis - afin que vous appreniez à résoudre de tels exemples non seulement avec précision, mais aussi rapidement. Nous étudions attentivement la norme :
Une tâche
À la suite de l'étude de la relation entre deux indicateurs, les paires de nombres suivantes ont été obtenues : 
En utilisant la méthode des moindres carrés, trouvez la fonction linéaire qui se rapproche le mieux de la valeur empirique (expérimenté) Les données. Faire un dessin sur lequel, dans un système de coordonnées rectangulaires cartésiennes, tracer des points expérimentaux et un graphique de la fonction d'approximation ![]() . Trouver la somme des écarts au carré entre les valeurs empiriques et théoriques. Découvrez si la fonction est meilleure (selon la méthode des moindres carrés) points expérimentaux approximatifs.
. Trouver la somme des écarts au carré entre les valeurs empiriques et théoriques. Découvrez si la fonction est meilleure (selon la méthode des moindres carrés) points expérimentaux approximatifs.
Notez que les valeurs "x" sont des valeurs naturelles, et cela a une signification significative caractéristique, dont je parlerai un peu plus tard; mais ils peuvent bien sûr être fractionnaires. De plus, selon le contenu d'une tâche particulière, les valeurs "X" et "G" peuvent être totalement ou partiellement négatives. Eh bien, on nous a confié une tâche "sans visage", et nous la commençons décision:
On trouve les coefficients de la fonction optimale comme solution du système : 
Pour les besoins d'une notation plus compacte, la variable « compteur » peut être omise, puisqu'il est déjà clair que la sommation s'effectue de 1 à .
Il est plus pratique de calculer les montants requis sous forme de tableau : 
Les calculs peuvent être effectués sur une microcalculatrice, mais il est préférable d'utiliser Excel - à la fois plus rapide et sans erreur; regarder une courte vidéo :
Ainsi, nous obtenons ce qui suit système:![]()
Ici, vous pouvez multiplier la deuxième équation par 3 et soustraire la 2ème de la 1ère équation terme à terme. Mais c'est de la chance - dans la pratique, les systèmes ne sont souvent pas doués, et dans de tels cas, cela permet d'économiser La méthode de Cramer:
, donc le système a une solution unique.

Faisons une vérification. Je comprends que je ne veux pas, mais pourquoi sauter des erreurs là où vous ne pouvez absolument pas les manquer ? Remplacez la solution trouvée dans le côté gauche de chaque équation du système :
Les bonnes parties des équations correspondantes sont obtenues, ce qui signifie que le système est résolu correctement.
Ainsi, la fonction d'approximation recherchée : – de toutes les fonctions linéaires les données expérimentales s'en rapprochent le mieux.
Contrairement à droit
dépendance du chiffre d'affaires du magasin à sa surface, la dépendance constatée est inverse
(principe "plus - moins"), et ce fait est immédiatement révélé par la négative coefficient angulaire. Une fonction ![]() nous informe qu'avec une augmentation d'un certain indicateur d'une unité, la valeur de l'indicateur dépendant diminue moyenne de 0,65 unités. Comme on dit, plus le prix du sarrasin est élevé, moins il en vend.
nous informe qu'avec une augmentation d'un certain indicateur d'une unité, la valeur de l'indicateur dépendant diminue moyenne de 0,65 unités. Comme on dit, plus le prix du sarrasin est élevé, moins il en vend.
Pour tracer la fonction d'approximation, on trouve deux de ses valeurs :
et exécutez le dessin: 
La droite construite s'appelle ligne de tendance
(à savoir une ligne de tendance linéaire, c'est-à-dire que dans le cas général, une tendance n'est pas forcément une ligne droite). Tout le monde connaît l'expression "être dans la tendance", et je pense que ce terme n'a pas besoin de commentaires supplémentaires.
Calculer la somme des écarts au carré ![]() entre les valeurs empiriques et théoriques. Géométriquement, c'est la somme des carrés des longueurs des segments "cramoisis" (dont deux sont si petits que vous ne pouvez même pas les voir).
entre les valeurs empiriques et théoriques. Géométriquement, c'est la somme des carrés des longueurs des segments "cramoisis" (dont deux sont si petits que vous ne pouvez même pas les voir).
Résumons les calculs dans un tableau : 
Elles peuvent à nouveau être réalisées manuellement, au cas où je donnerai un exemple pour le 1er point : ![]()
mais il est bien plus efficace de faire de la manière déjà connue :
Répétons : quelle est la signification du résultat ? De toutes les fonctions linéaires une fonction ![]() l'exposant est le plus petit, c'est-à-dire qu'il est la meilleure approximation de sa famille. Et ici, soit dit en passant, la dernière question du problème n'est pas accidentelle : et si la fonction exponentielle proposée
l'exposant est le plus petit, c'est-à-dire qu'il est la meilleure approximation de sa famille. Et ici, soit dit en passant, la dernière question du problème n'est pas accidentelle : et si la fonction exponentielle proposée ![]() sera-t-il préférable d'approximer les points expérimentaux ?
sera-t-il préférable d'approximer les points expérimentaux ?
Trouvons la somme correspondante des écarts au carré - pour les distinguer, je les désignerai par la lettre "epsilon". La technique est exactement la même : 
Et encore pour chaque calcul de feu pour le 1er point : 
Dans Excel, nous utilisons la fonction standard EXP (La syntaxe peut être trouvée dans l'aide d'Excel).
Production: , donc la fonction exponentielle approche les points expérimentaux moins bien que la droite ![]() .
.
Mais il convient de noter ici que "pire" est ne veut pas encore dire, Qu'est-ce qui ne va pas. Maintenant, j'ai construit un graphique de cette fonction exponentielle - et elle passe également près des points ![]() - à tel point que sans étude analytique il est difficile de dire quelle fonction est la plus précise.
- à tel point que sans étude analytique il est difficile de dire quelle fonction est la plus précise.
Ceci complète la solution, et je reviens à la question des valeurs naturelles de l'argument. Dans diverses études, en règle générale, économiques ou sociologiques, les mois, les années ou d'autres intervalles de temps égaux sont numérotés avec un "X" naturel. Considérons, par exemple, le problème suivant :
Nous disposons des données suivantes sur le chiffre d'affaires du magasin pour le premier semestre :
À l'aide d'un alignement analytique en ligne droite, trouvez le volume des ventes pour juillet.
Oui, pas de problème: nous numérotons les mois 1, 2, 3, 4, 5, 6 et utilisons l'algorithme habituel, à la suite duquel nous obtenons une équation - la seule chose en ce qui concerne le temps est généralement la lettre "te " (même si ce n'est pas critique). L'équation qui en résulte montre qu'au cours du premier semestre de l'année, le chiffre d'affaires a augmenté en moyenne de 27,74 UM. par mois. Obtenir une prévision pour juillet (mois #7): UE.
Et des tâches similaires - l'obscurité est sombre. Ceux qui le souhaitent peuvent utiliser un service supplémentaire, à savoir mon Calculatrice Excel (version de démonstration), lequel résout le problème presque instantanément! La version de travail du programme est disponible en échange ou pour paiement symbolique.
À la fin de la leçon, une brève information sur la recherche de dépendances de certains autres types. En fait, il n'y a rien de spécial à dire, puisque l'approche fondamentale et l'algorithme de solution restent les mêmes.
Supposons que la localisation des points expérimentaux ressemble à une hyperbole. Ensuite, pour trouver les coefficients de la meilleure hyperbole, il faut trouver le minimum de la fonction - ceux qui le souhaitent peuvent effectuer des calculs détaillés et arriver à un système similaire : 
D'un point de vue technique formel, il est obtenu à partir du système "linéaire"  (marquons-le d'un astérisque) en remplaçant "x" par . Eh bien, les montants
(marquons-le d'un astérisque) en remplaçant "x" par . Eh bien, les montants ![]() calculer, après quoi les coefficients optimaux "a" et "be" à portée de main.
calculer, après quoi les coefficients optimaux "a" et "be" à portée de main.
S'il y a tout lieu de croire que les points ![]() sont disposés le long d'une courbe logarithmique, puis de rechercher les valeurs optimales et de trouver le minimum de la fonction
sont disposés le long d'une courbe logarithmique, puis de rechercher les valeurs optimales et de trouver le minimum de la fonction ![]() . Formellement, dans le système (*) doit être remplacé par :
. Formellement, dans le système (*) doit être remplacé par : 
Lors du calcul dans Excel, utilisez la fonction NL. J'avoue qu'il ne me sera pas difficile de créer des calculatrices pour chacun des cas envisagés, mais ce sera encore mieux si vous "programmez" vous-même les calculs. Tutoriels vidéo pour vous aider.
Avec une dépendance exponentielle, la situation est légèrement plus compliquée. Pour réduire la question au cas linéaire, nous prenons le logarithme de la fonction et utilisons propriétés du logarithme:
Maintenant, en comparant la fonction obtenue avec la fonction linéaire , nous arrivons à la conclusion que dans le système (*) doit être remplacé par , et - par . Par commodité, on note : 
Veuillez noter que le système est résolu par rapport à et , et donc, après avoir trouvé les racines, vous ne devez pas oublier de trouver le coefficient lui-même.
Approcher des points expérimentaux ![]() parabole optimale
parabole optimale ![]() , doit se trouver minimum d'une fonction de trois variables
, doit se trouver minimum d'une fonction de trois variables ![]() . Après avoir effectué des actions standard, nous obtenons le "travail" suivant système:
. Après avoir effectué des actions standard, nous obtenons le "travail" suivant système:
Oui, bien sûr, il y a plus de montants ici, mais il n'y a aucune difficulté lors de l'utilisation de votre application préférée. Et enfin, je vous dirai comment vérifier rapidement à l'aide d'Excel et construire la ligne de tendance souhaitée: créez un nuage de points, sélectionnez l'un des points avec la souris ![]() et clic droit sélectionnez l'option "Ajouter une ligne de tendance". Ensuite, sélectionnez le type de graphique et sur l'onglet "Paramètres" activer l'option "Afficher l'équation sur le graphique". D'ACCORD
et clic droit sélectionnez l'option "Ajouter une ligne de tendance". Ensuite, sélectionnez le type de graphique et sur l'onglet "Paramètres" activer l'option "Afficher l'équation sur le graphique". D'ACCORD
Comme toujours, je veux terminer l'article avec une belle phrase, et j'ai failli taper "Soyez dans la tendance!". Mais avec le temps, il a changé d'avis. Et pas parce que c'est une formule. Je ne sais comment personne, mais je ne veux pas du tout suivre la tendance promue américaine et surtout européenne =) Je souhaite donc à chacun de s'en tenir à sa propre ligne !
http://www.grandars.ru/student/vysshaya-matematika/metod-naimenshih-kvadratov.html
La méthode des moindres carrés est l'une des plus courantes et des plus développées en raison de sa simplicité et efficacité des méthodes d'estimation des paramètres des modèles économétriques linéaires. Dans le même temps, une certaine prudence doit être observée lors de son utilisation, car les modèles construits à l'aide de celui-ci peuvent ne pas répondre à un certain nombre d'exigences concernant la qualité de leurs paramètres et, par conséquent, ne reflètent pas « bien » les modèles de développement de processus.
Examinons plus en détail la procédure d'estimation des paramètres d'un modèle économétrique linéaire par la méthode des moindres carrés. Un tel modèle sous forme générale peut être représenté par l'équation (1.2):
y t = une 0 + une 1 X 1t +...+ une n X nt + ε t .
La donnée initiale lors de l'estimation des paramètres a 0 , a 1 ,..., a n est le vecteur de valeurs de la variable dépendante y= (y 1 , y 2 , ... , y T)" et la matrice des valeurs des variables indépendantes

dans laquelle la première colonne, composée de uns, correspond au coefficient du modèle .
La méthode des moindres carrés tire son nom du principe de base selon lequel les estimations de paramètres obtenues sur sa base doivent satisfaire : la somme des carrés de l'erreur du modèle doit être minimale.
Exemples de résolution de problèmes par la méthode des moindres carrés
Exemple 2.1. L'entreprise commerciale dispose d'un réseau composé de 12 magasins, dont les informations sur les activités sont présentées dans le tableau. 2.1.
La direction de l'entreprise aimerait savoir comment la taille du chiffre d'affaires annuel dépend de l'espace de vente du magasin.
Tableau 2.1
| Numéro de magasin | Chiffre d'affaires annuel, millions de roubles | Zone commerciale, milliers de m 2 |
| 19,76 | 0,24 | |
| 38,09 | 0,31 | |
| 40,95 | 0,55 | |
| 41,08 | 0,48 | |
| 56,29 | 0,78 | |
| 68,51 | 0,98 | |
| 75,01 | 0,94 | |
| 89,05 | 1,21 | |
| 91,13 | 1,29 | |
| 91,26 | 1,12 | |
| 99,84 | 1,29 | |
| 108,55 | 1,49 |
Solution des moindres carrés. Désignons - le chiffre d'affaires annuel du -ème magasin, en millions de roubles; - surface de vente du ème magasin, mille m 2.

Fig.2.1. Nuage de points pour l'exemple 2.1
Déterminer la forme de la relation fonctionnelle entre les variables et construire un nuage de points (Fig. 2.1).
Sur la base du diagramme de dispersion, nous pouvons conclure que le chiffre d'affaires annuel dépend positivement de la zone de vente (c'est-à-dire que y augmentera avec la croissance de ). La forme la plus appropriée de connexion fonctionnelle est linéaire.
Les informations pour les calculs ultérieurs sont présentées dans le tableau. 2.2. En utilisant la méthode des moindres carrés, nous estimons les paramètres du modèle économétrique linéaire à un facteur

Tableau 2.2
| t | yt | x 1 t | y t 2 | x1t2 | x 1t y t |
| 19,76 | 0,24 | 390,4576 | 0,0576 | 4,7424 | |
| 38,09 | 0,31 | 1450,8481 | 0,0961 | 11,8079 | |
| 40,95 | 0,55 | 1676,9025 | 0,3025 | 22,5225 | |
| 41,08 | 0,48 | 1687,5664 | 0,2304 | 19,7184 | |
| 56,29 | 0,78 | 3168,5641 | 0,6084 | 43,9062 | |
| 68,51 | 0,98 | 4693,6201 | 0,9604 | 67,1398 | |
| 75,01 | 0,94 | 5626,5001 | 0,8836 | 70,5094 | |
| 89,05 | 1,21 | 7929,9025 | 1,4641 | 107,7505 | |
| 91,13 | 1,29 | 8304,6769 | 1,6641 | 117,5577 | |
| 91,26 | 1,12 | 8328,3876 | 1,2544 | 102,2112 | |
| 99,84 | 1,29 | 9968,0256 | 1,6641 | 128,7936 | |
| 108,55 | 1,49 | 11783,1025 | 2,2201 | 161,7395 | |
| S | 819,52 | 10,68 | 65008,554 | 11,4058 | 858,3991 |
| Moyenne | 68,29 | 0,89 |
Ainsi,
Par conséquent, avec une augmentation de la zone commerciale de 1 000 m 2, toutes choses étant égales par ailleurs, le chiffre d'affaires annuel moyen augmente de 67,8871 millions de roubles.
Exemple 2.2. La direction de l'entreprise a remarqué que le chiffre d'affaires annuel dépend non seulement de la surface de vente du magasin (voir exemple 2.1), mais également du nombre moyen de visiteurs. Les informations pertinentes sont présentées dans le tableau. 2.3.
Tableau 2.3
Décision. Dénoter - le nombre moyen de visiteurs au -ème magasin par jour, mille personnes.
Déterminer la forme de la relation fonctionnelle entre les variables et construire un nuage de points (Fig. 2.2).
Sur la base du diagramme de dispersion, nous pouvons conclure que le chiffre d'affaires annuel est positivement lié au nombre moyen de visiteurs par jour (c'est-à-dire que y augmentera avec la croissance de ). La forme de dépendance fonctionnelle est linéaire.

Riz. 2.2. Nuage de points par exemple 2.2
Tableau 2.4
| t | x 2t | x 2t 2 | yt x 2t | x 1t x 2t |
| 8,25 | 68,0625 | 163,02 | 1,98 | |
| 10,24 | 104,8575 | 390,0416 | 3,1744 | |
| 9,31 | 86,6761 | 381,2445 | 5,1205 | |
| 11,01 | 121,2201 | 452,2908 | 5,2848 | |
| 8,54 | 72,9316 | 480,7166 | 6,6612 | |
| 7,51 | 56,4001 | 514,5101 | 7,3598 | |
| 12,36 | 152,7696 | 927,1236 | 11,6184 | |
| 10,81 | 116,8561 | 962,6305 | 13,0801 | |
| 9,89 | 97,8121 | 901,2757 | 12,7581 | |
| 13,72 | 188,2384 | 1252,0872 | 15,3664 | |
| 12,27 | 150,5529 | 1225,0368 | 15,8283 | |
| 13,92 | 193,7664 | 1511,016 | 20,7408 | |
| S | 127,83 | 1410,44 | 9160,9934 | 118,9728 |
| Moyenne | 10,65 |
De manière générale, il est nécessaire de déterminer les paramètres du modèle économétrique à deux facteurs
y t \u003d une 0 + une 1 x 1t + une 2 x 2t + ε t
Les informations requises pour les calculs ultérieurs sont présentées dans le tableau. 2.4.
Estimons les paramètres d'un modèle économétrique linéaire à deux facteurs par la méthode des moindres carrés.

Ainsi,
L'évaluation du coefficient = 61,6583 montre que, toutes choses étant égales par ailleurs, avec une augmentation de la surface commerciale de 1 000 m 2, le chiffre d'affaires annuel augmentera en moyenne de 61,6583 millions de roubles.
L'estimation du coefficient = 2,2748 le montre, toutes choses égales par ailleurs, avec une augmentation du nombre moyen de visiteurs pour 1 000 habitants. par jour, le chiffre d'affaires annuel augmentera en moyenne de 2,2748 millions de roubles.
Exemple 2.3. En utilisant les informations présentées dans le tableau. 2.2 et 2.4, estimer le paramètre d'un modèle économétrique à facteur unique
![]()
où est la valeur centrée du chiffre d'affaires annuel du -ème magasin, en millions de roubles; - valeur centrée du nombre quotidien moyen de visiteurs dans le t-ème magasin, en milliers de personnes. (voir exemples 2.1-2.2).
Décision. Les informations supplémentaires requises pour les calculs sont présentées dans le tableau. 2.5.
Tableau 2.5
| -48,53 | -2,40 | 5,7720 | 116,6013 | |
| -30,20 | -0,41 | 0,1702 | 12,4589 | |
| -27,34 | -1,34 | 1,8023 | 36,7084 | |
| -27,21 | 0,36 | 0,1278 | -9,7288 | |
| -12,00 | -2,11 | 4,4627 | 25,3570 | |
| 0,22 | -3,14 | 9,8753 | -0,6809 | |
| 6,72 | 1,71 | 2,9156 | 11,4687 | |
| 20,76 | 0,16 | 0,0348 | 3,2992 | |
| 22,84 | -0,76 | 0,5814 | -17,413 | |
| 22,97 | 3,07 | 9,4096 | 70,4503 | |
| 31,55 | 1,62 | 2,6163 | 51,0267 | |
| 40,26 | 3,27 | 10,6766 | 131,5387 | |
| Somme | 48,4344 | 431,0566 |
En utilisant la formule (2.35), on obtient

Ainsi,
![]()
http://www.cleverstudents.ru/articles/mnk.html
Exemple.
Données expérimentales sur les valeurs des variables X et à sont donnés dans le tableau. 
Du fait de leur alignement, la fonction ![]()
En utilisant méthode des moindres carrés, approximer ces données avec une dépendance linéaire y=ax+b(trouver les paramètres une et b). Découvrez laquelle des deux lignes est la meilleure (au sens de la méthode des moindres carrés) aligne les données expérimentales. Faites un dessin.
Décision.
Dans notre exemple n=5. Nous remplissons le tableau pour faciliter le calcul des montants inclus dans les formules des coefficients requis. 
Les valeurs de la quatrième ligne du tableau sont obtenues en multipliant les valeurs de la 2ème ligne par les valeurs de la 3ème ligne pour chaque nombre je.
Les valeurs de la cinquième ligne du tableau sont obtenues en mettant au carré les valeurs de la 2ème ligne pour chaque nombre je.
Les valeurs de la dernière colonne du tableau sont les sommes des valeurs sur les lignes.
On utilise les formules de la méthode des moindres carrés pour trouver les coefficients une et b. Nous y substituons les valeurs correspondantes de la dernière colonne du tableau: 
Par conséquent, y=0,165x+2,184 est la droite d'approximation souhaitée.
Reste à savoir laquelle des lignes y=0,165x+2,184 ou alors ![]() mieux se rapprocher des données d'origine, c'est-à-dire faire une estimation en utilisant la méthode des moindres carrés.
mieux se rapprocher des données d'origine, c'est-à-dire faire une estimation en utilisant la méthode des moindres carrés.
Preuve.
Alors que lorsqu'il est trouvé une et b fonction prend la plus petite valeur, il faut qu'à ce point la matrice de la forme quadratique de la différentielle du second ordre pour la fonction ![]() était défini positif. Montrons-le.
était défini positif. Montrons-le.
La différentielle du second ordre a la forme : 
C'est
Par conséquent, la matrice de la forme quadratique a la forme 
et les valeurs des éléments ne dépendent pas de une et b.
Montrons que la matrice est définie positive. Cela nécessite que les mineurs d'angle soient positifs.
Mineur angulaire du premier ordre  . L'inégalité est stricte, puisque les points
. L'inégalité est stricte, puisque les points